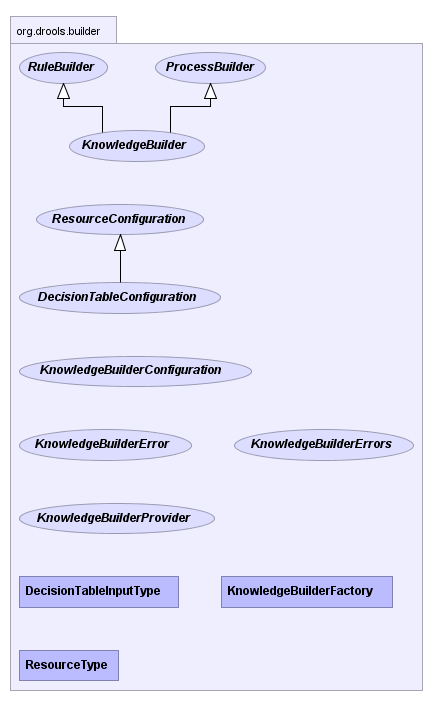
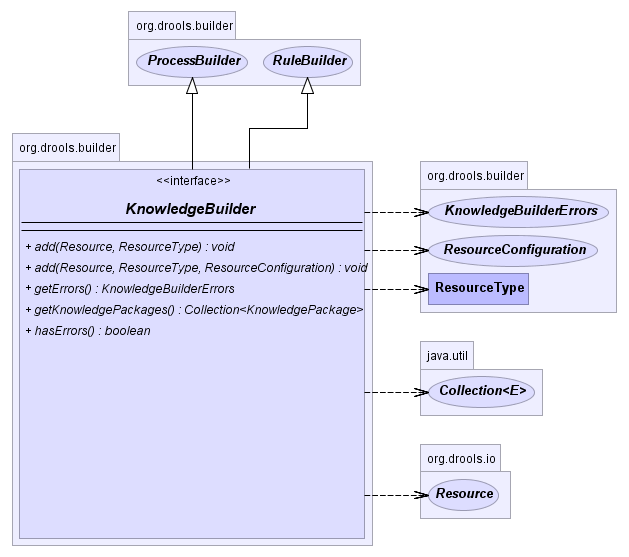
The KnowledgeBuilder is responsible for taking source files, such as
a DRL file or an Excel file, and turning them into a Knowledge Package of
rule and process definitions which a Knowledge Base can consume. An object
of the class ResourceType indicates the type of resource it is being
asked to build.
The ResourceFactory provides capabilities to load resources from a
number of sources, such as Reader, ClassPath, URL, File, or ByteArray.
Binaries, such as decision tables (Excel .xls files), should not use a Reader based
resource handler, which is only suitable for text based resources.
The KnowlegeBuilder is created using the KnowledgeBuilderFactory.
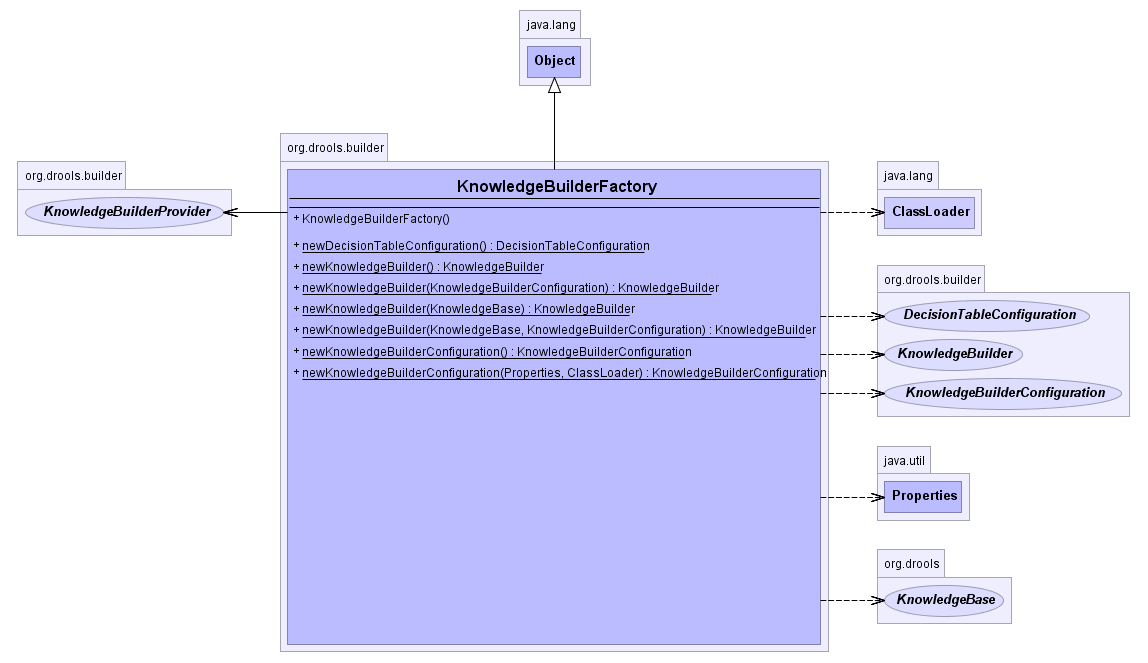
A KnowledgeBuilder can be created using the default configuration.
Example 4.1. Creating a new KnowledgeBuilder
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory.newKnowledgeBuilder();
A configuration can be created using the KnowledgeBuilderFactory.
This allows the behavior of the Knowledge Builder to be modified. The most
common usage is to provide a custom class loader so that the KnowledgeBuilder
object can resolve classes that are not in the default classpath. The first parameter
is for properties and is optional, i.e., it may be left null, in which case the
default options will be used. The options parameter can be used for things
like changing the dialect or registering new accumulator functions.
Example 4.2. Creating a new KnowledgeBuilder with a custom ClassLoader
KnowledgeBuilderConfiguration kbuilderConf = KnowledgeBuilderFactory.newKnowledgeBuilderConfiguration(null, classLoader );
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory.newKnowledgeBuilder(kbuilderConf);
Resources of any type can be added iteratively. Below, a DRL file is added. Unlike Drools 4.0 Package Builder, the Knowledge Builder can now handle multiple namespaces, so you can just keep adding resources regardless of namespace.
Example 4.3. Adding DRL Resources
kbuilder.add( ResourceFactory.newFileResource( "/project/myrules.drl" ),
ResourceType.DRL);
It is best practice to always check the hasErrors() method after an
addition. You should not add more resources or retrieve the Knowledge Packages
if there are errors. getKnowledgePackages() returns an empty list if
there are errors.
Example 4.4. Validating
if( kbuilder.hasErrors() ) {
System.out.println( kbuilder.getErrors() );
return;
}
When all the resources have been added and there are no errors the collection of Knowledge Packages can be retrieved. It is a Collection because there is one Knowledge Package per package namespace. These Knowledge Packages are serializable and often used as a unit of deployment.
Example 4.5. Getting the KnowledgePackages
Collection<KnowledgePackage> kpkgs = kbuilder.getKnowledgePackages();
The final example puts it all together.
Example 4.6. Putting it all together
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory.newKnowledgeBuilder();
if( kbuilder.hasErrors() ) {
System.out.println( kbuilder.getErrors() );
return;
}
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory.newKnowledgeBuilder();
kbuilder.add( ResourceFactory.newFileResource( "/project/myrules1.drl" ),
ResourceType.DRL);
kbuilder.add( ResourceFactory.newFileResource( "/project/myrules2.drl" ),
ResourceType.DRL);
if( kbuilder.hasErrors() ) {
System.out.println( kbuilder.getErrors() );
return;
}
Collection<KnowledgePackage> kpkgs = kbuilder.getKnowledgePackages();
Instead of adding the resources to create definitions programmatically it is also possible to do it by configuration, via the ChangeSet XML. The simple XML file supports three elements: add, remove, and modify, each of which has a sequence of <resource> subelements defining a configuration entity. The following XML schema is not normative and intended for illustration only.
Example 4.7. XML Schema for ChangeSet XML (not normative)
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns="http://drools.org/drools-5.0/change-set"
targetNamespace="http://drools.org/drools-5.0/change-set">
<xs:element name="change-set" type="ChangeSet"/>
<xs:complexType name="ChangeSet">
<xs:choice maxOccurs="unbounded">
<xs:element name="add" type="Operation"/>
<xs:element name="remove" type="Operation"/>
<xs:element name="modify" type="Operation"/>
</xs:choice>
</xs:complexType>
<xs:complexType name="Operation">
<xs:sequence>
<xs:element name="resource" type="Resource"
maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="Resource">
<xs:sequence>
<xs:element name="decisiontable-conf" type="DecTabConf"
minOccurs="0"/>
</xs:sequence>
<xs:attribute name="source" type="xs:string"/>
<xs:attribute name="type" type="ResourceType"/>
</xs:complexType>
<xs:complexType name="DecTabConf">
<xs:attribute name="input-type" type="DecTabInpType"/>
<xs:attribute name="worksheet-name" type="xs:string"
use="optional"/>
</xs:complexType>
<xs:simpleType name="ResourceType">
<xs:restriction base="xs:string">
<xs:enumeration value="DRL"/>
<xs:enumeration value="XDRL"/>
<xs:enumeration value="DSL"/>
<xs:enumeration value="DSLR"/>
<xs:enumeration value="DRF"/>
<xs:enumeration value="DTABLE"/>
<xs:enumeration value="PKG"/>
<xs:enumeration value="BRL"/>
<xs:enumeration value="CHANGE_SET"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="DecTabInpType">
<xs:restriction base="xs:string">
<xs:enumeration value="XLS"/>
<xs:enumeration value="CSV"/>
</xs:restriction>
</xs:simpleType>
</xs:schema>
Currently only the add element is supported, but the others will be implemented to support iterative changes. The following example loads a single DRL file.
Example 4.8. Simple ChangeSet XML
<change-set xmlns='http://drools.org/drools-5.0/change-set'
xmlns:xs='http://www.w3.org/2001/XMLSchema-instance'
xs:schemaLocation='http://drools.org/drools-5.0/change-set.xsd http://anonsvn.jboss.org/repos/labs/labs/jbossrules/trunk/drools-api/src/main/resources/change-set-1.0.0.xsd' >
<add>
<resource source='file:/project/myrules.drl' type='DRL' />
</add>
</change-set>
Notice the file: prefix, which signifies the protocol for the
resource. The Change Set supports all the protocols provided by
java.net.URL, such as "file" and "http", as well as an additional
"classpath". Currently the type attribute must always be specified for a
resource, as it is not inferred from the file name extension. Using the
ClassPath resource loader in Java allows you to specify the Class Loader to
be used to locate the resource but this is not possible from XML. Instead,
the Class Loader will default to the one used by the Knowledge Builder
unless the ChangeSet XML is itself loaded by the ClassPath resource, in
which case it will use the Class Loader specified for that resource.
Currently you still need to use the API to load that ChangeSet, but we will add support for containers such as Spring in the future, so that the process of creating a Knowledge Base can be done completely by XML configuration. Loading resources using an XML file couldn't be simpler, as it's just another resource type.
Example 4.9. Loading the ChangeSet XML
kbuilder.add( ResourceFactory.newUrlResource( url ), ResourceType.CHANGE_SET );
ChangeSets can include any number of resources, and they even support additional configuration information, which currently is only needed for decision tables. Below, the example is expanded to load rules from a http URL location, and an Excel decision table from the classpath.
Example 4.10. ChangeSet XML with resource configuration
<change-set xmlns='http://drools.org/drools-5.0/change-set'
xmlns:xs='http://www.w3.org/2001/XMLSchema-instance'
xs:schemaLocation='http://drools.org/drools-5.0/change-set.xsd http://anonsvn.jboss.org/repos/labs/labs/jbossrules/trunk/drools-api/src/main/resources/change-set-1.0.0.xsd' >
<add>
<resource source='http:org/domain/myrules.drl' type='DRL' />
<resource source='classpath:data/IntegrationExampleTest.xls' type="DTABLE">
<decisiontable-conf input-type="XLS" worksheet-name="Tables_2" />
</resource>
</add>
</change-set>
The ChangeSet is especially useful when working with a Knowledge Agent, as it allows for change notification and automatic rebuilding of the Knowledge Base, which is covered in more detail in the section on the Knowledge Agent, under Deploying.
Directories can also be specified, to add all resources in that folder. Currently it is expected that all resources in that folder are of the same type. If you use the Knowledge Agent it will provide a continous scanning for added, modified or removed resources and rebuild the cached Knowledge Base. The KnowledgeAgent provides more information on this.
Example 4.11. ChangeSet XML which adds a directory's contents
<change-set xmlns='http://drools.org/drools-5.0/change-set'
xmlns:xs='http://www.w3.org/2001/XMLSchema-instance'
xs:schemaLocation='http://drools.org/drools-5.0/change-set.xsd http://anonsvn.jboss.org/repos/labs/labs/jbossrules/trunk/drools-api/src/main/resources/change-set-1.0.0.xsd' >
<add>
<resource source='file:/projects/myproject/myrules' type='DRL' />
</add>
</change-set>
A Knowledge Package is a collection of Knowledge Definitions, such as rules and processes. It is created by the Knowledge Builder, as described in the chapter "Building". Knowledge Packages are self-contained and serializable, and they currently form the basic deployment unit.
Knowledge Packages are added to the Knowledge Base. However, a Knowledge Package instance cannot be reused once it's added to the Knowledge Base. If you need to add it to another Knowledge Base, try serializing it first and using the "cloned" result. We hope to fix this limitation in future versions of Drools.
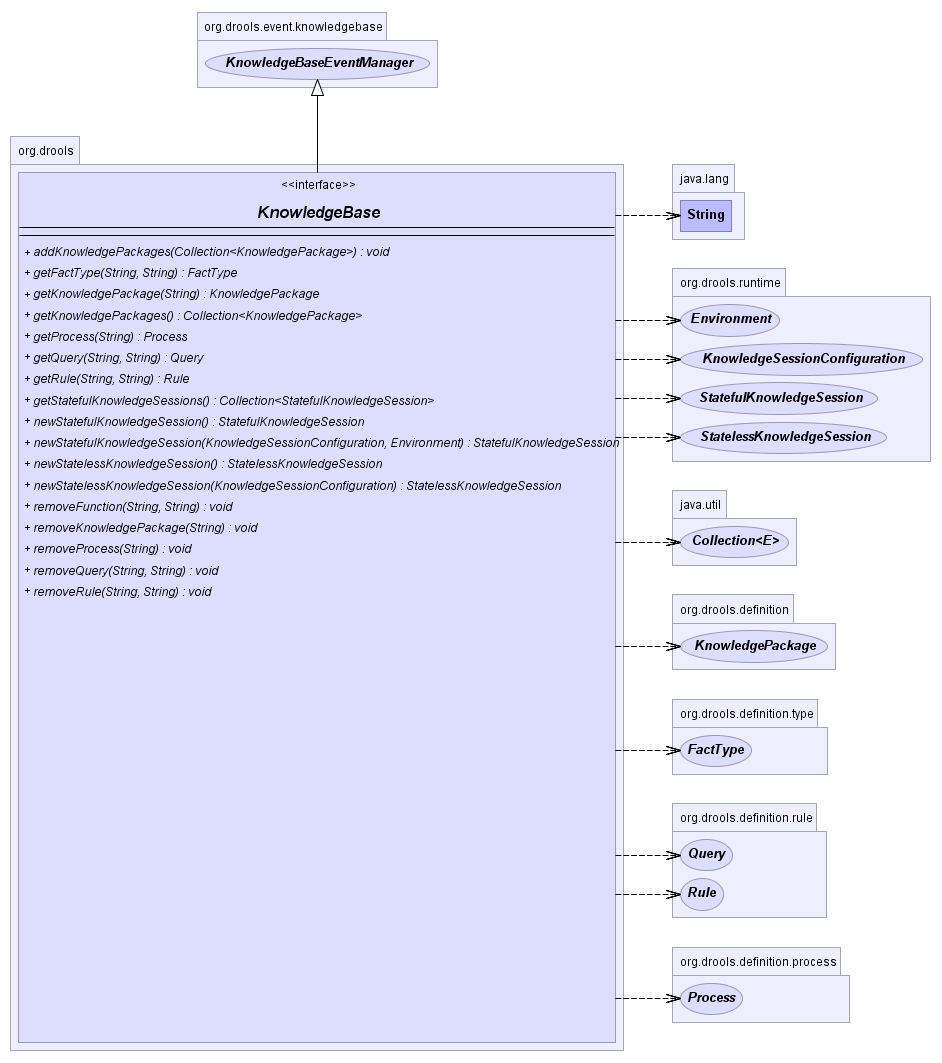
The Knowlege Base is a repository of all the application's knowledge definitions. It may contain rules, processes, functions, and type models. The Knowledge Base itself does not contain instance data, known as facts; instead, sessions are created from the Knowledge Base into which data can be inserted and where process instances may be started. Creating the Knowlege Base can be heavy, whereas session creation is very light, so it is recommended that Knowledge Bases be cached where possible to allow for repeated session creation.
A KnowledgeBase object is also serializable, and some people
may prefer to build and then store a KnowledgeBase, treating it also
as a unit of deployment, instead of the Knowledge Packages.
The KnowlegeBase is created using the KnowledgeBaseFactory.
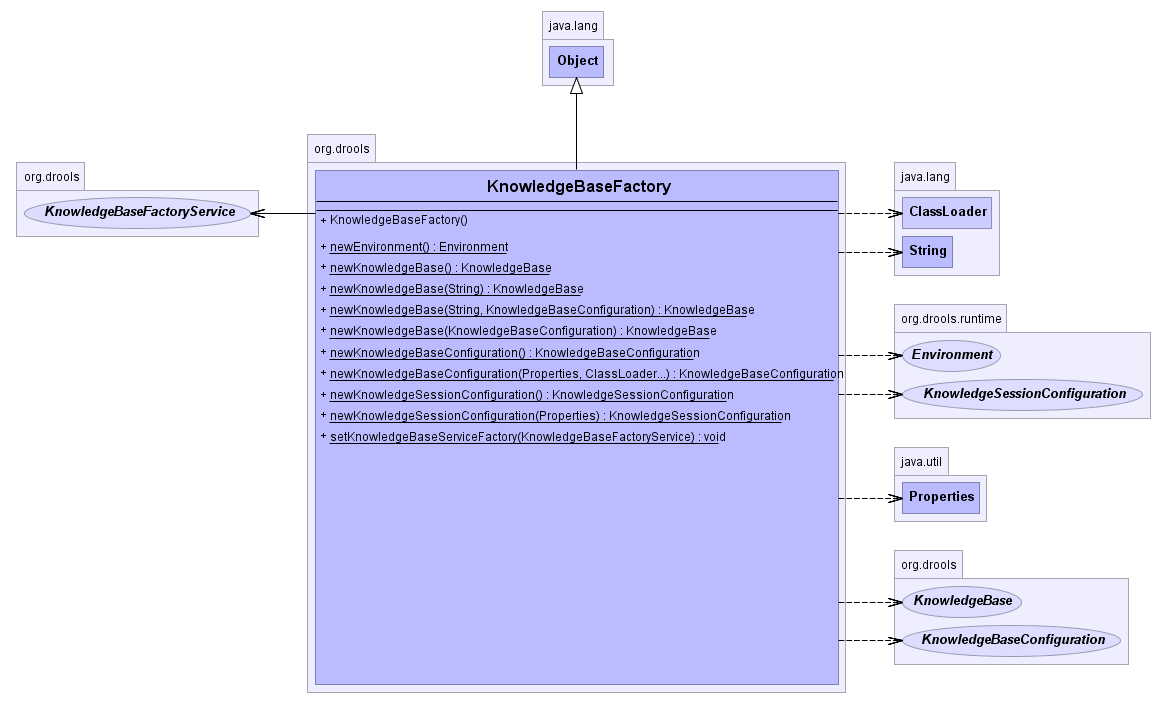
A KnowledgeBase can be created using the default configuration.
Example 4.12. Creating a new KnowledgeBase
KnowledgeBase kbase = KnowledgeBaseFactory.newKnowledgeBase();
If a custom class loader was used with the KnowledgeBuilder to
resolve types not in the default class loader, then that must also be set
on the KnowledgeBase. The technique for this is the same as with the
KnowledgeBuilder.
Example 4.13. Creating a new KnowledgeBase with a custom ClassLoader
KnowledgeBaseConfiguration kbaseConf =
KnowledgeBaseFactory.createKnowledgeBaseConfiguration( null, cl );
KnowledgeBase kbase = KnowledgeBaseFactory.newKnowledgeBase( kbaseConf );
This is the simplest form of deployment. It compiles the knowledge definitions and adds them to the Knowledge Base in the same JVM. This approach requires drools-core.jar and drools-compiler.jar to be on the classpath.
Example 4.14. Add KnowledgePackages to a KnowledgeBase
Collection<KnowledgePackage> kpkgs = kbuilder.getKnowledgePackages();
KnowledgeBase kbase = KnowledgeBaseFactory.newKnowledgeBase();
kbase.addKnowledgePackages( kpkgs );
Note that the addKnowledgePackages(kpkgs) method can be called
iteratively to add additional knowledge.
Both the KnowledgeBase and the KnowledgePackage
are units of
deployment and serializable. This means you can have one machine do any
necessary building, requiring drools-compiler.jar, and
have another machine deploy and execute everything, needing only
drools-core.jar.
Although serialization is standard Java, we present an example of how one machine might write out the deployment unit and how another machine might read in and use that deployment unit.
Example 4.15. Writing the KnowledgePackage to an OutputStream
ObjectOutputStream out = new ObjectOutputStream( new FileOutputStream( fileName ) );
out.writeObject( kpkgs );
out.close();
Example 4.16. Reading the KnowledgePackage from an InputStream
ObjectInputStream in = new ObjectInputStream( new FileInputStream( fileName ) );
// The input stream might contain an individual
// package or a collection.
@SuppressWarnings( "unchecked" )
Collection<KnowledgePackage> kpkgs =
()in.readObject( Collection<KnowledgePackage> );
in.close();
KnowledgeBase kbase = KnowledgeBaseFactory.newKnowledgeBase();
kbase.addKnowledgePackages( kpkgs );
The KnowledgeBase is also serializable and some people may prefer
to build and then store the KnowledgeBase itself, instead of the
Knowledge Packages.
Drools Guvnor, our server side management system, uses this deployment approach. After Guvnor has compiled and published serialized Knowledge Packages on a URL, Drools can use the URL resource type to load them.
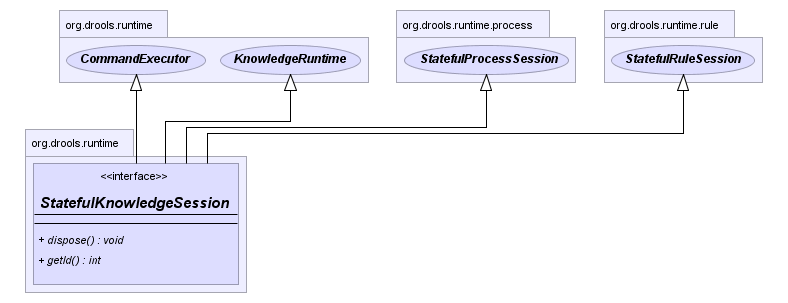
Stateful Knowledge Sessions will be discussed in more detail in
section "Running". The KnowledgeBase creates and returns
StatefulKnowledgeSession objects, and it may optionally
keep references to those.
When KnowledgeBase modifications occur those modifications are applied
against the data in the sessions. This reference is a weak reference and it
is also optional, which is controlled by a boolean flag.
The KnowlegeAgent provides automatic loading, caching and
re-loading of resources and is configured from a properties files. The
Knowledge Agent can update or rebuild this Knowlege Base as the
resources it uses are changed. The strategy for this is determined by the configuration
given to the factory, but it is typically pull-based using regular
polling. We hope to add push-based updates and rebuilds in future
versions. The Knowledge Agent will continuously scan all the added
resources, using a default polling interval of 60 seconds. If their
date of the last modification is updated it will rebuild the cached
Knowledge Base using the new resources.
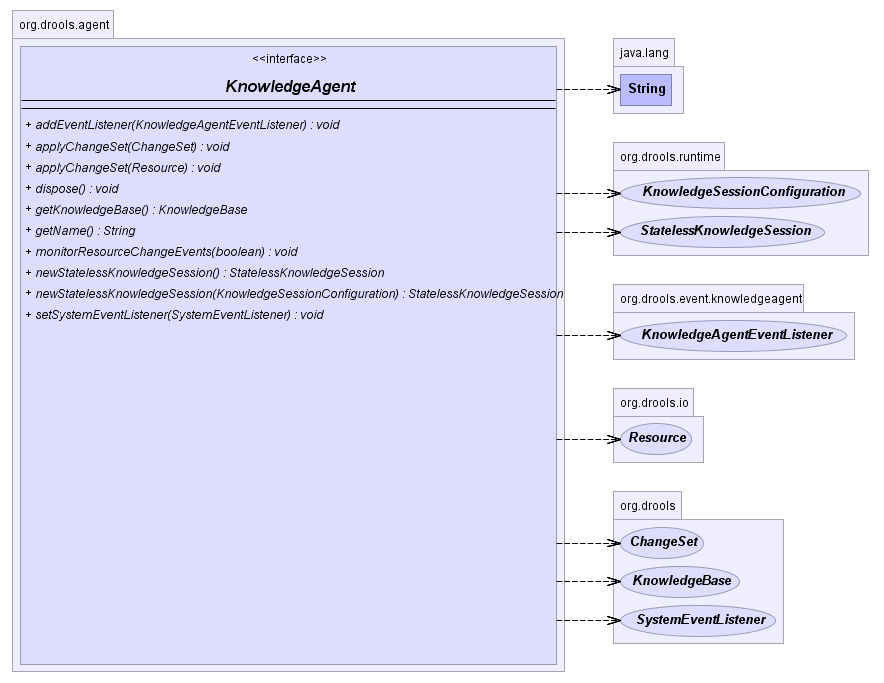
The KnowlegeBuilder is created using a
KnowledgeBuilderFactory object.
The agent must specify a name, which is used in the log files to associate
a log entry with the corresponding agent.
Example 4.17. Creating the KnowledgeAgent
KnowledgeAgent kagent = KnowledgeAgentFactory.newKnowledgeAgent( "MyAgent" );
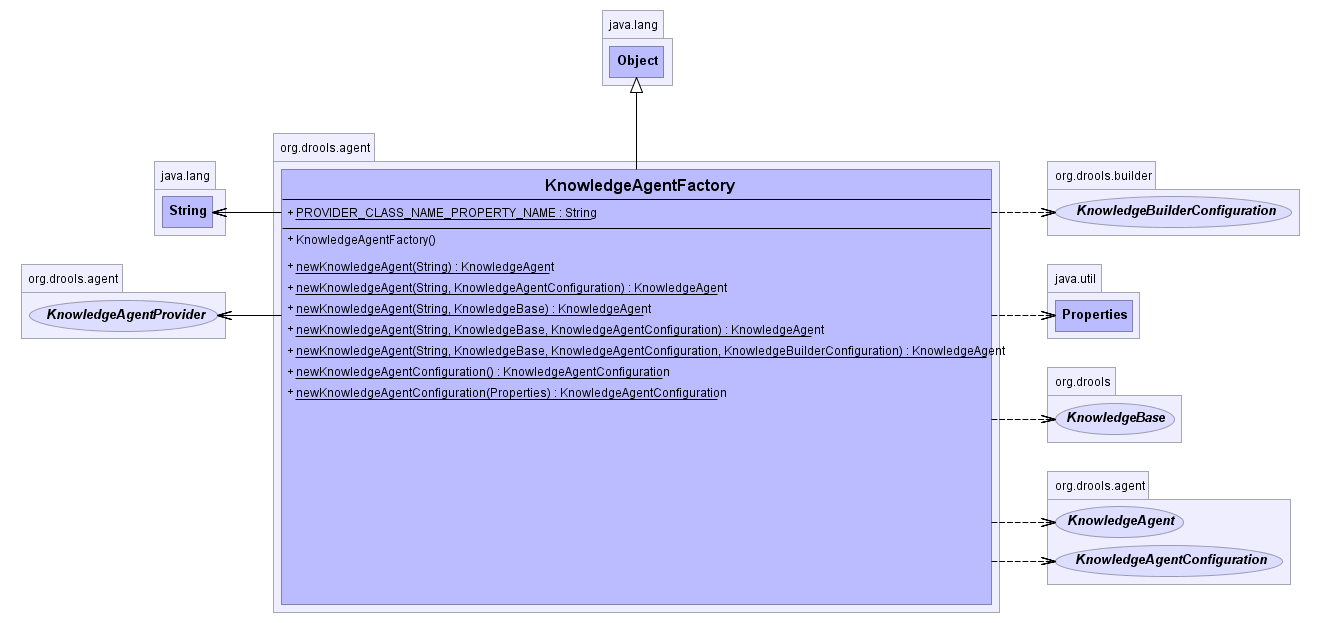
The following example constructs an agent that will build a new KnowledgeBase from the specified ChangeSet. (See section "Building" for more details on the ChangeSet format.) Note that the method can be called iteratively to add new resources over time. The Knowledge Agent polls the resources added from the ChangeSet every 60 seconds, the default interval, to see if they are updated. Whenever changes are found it will construct a new Knowledge Base or apply the modifications to the existing Knowledge Base according to its configuration. If the change set specifies a resource that is a directory its contents will be scanned for changes, too.
Example 4.18. Writing the KnowledgePackage to an OutputStream
KnowledgeAgent kagent = KnowledgeAgentFactory.newKnowledgeAgent( "MyAgent" );
kagent.applyChangeSet( ResourceFactory.newUrlResource( url ) );
KnowledgeBase kbase = kagent.getKnowledgeBase();
Resource scanning is not on by default, it's a service and must be started, and the same is true for notification. Both can be done via the ResourceFactory.
Example 4.19. Starting the Scanning and Notification Services
ResourceFactory.getResourceChangeNotifierService().start();
ResourceFactory.getResourceChangeScannerService().start();
The default resource scanning period may be changed via the
ResourceChangeScannerService. A suitably updated
ResourceChangeScannerConfiguration object is passed to the service's
configure() method, which allows for the service to be reconfigured on
demand.
Example 4.20. Changing the Scanning Intervals
ResourceChangeScannerConfiguration sconf =
ResourceFactory.getResourceChangeScannerService().newResourceChangeScannerConfiguration();
// Set the disk scanning interval to 30s, default is 60s.
sconf.setProperty( "drools.resource.scanner.interval", "30" );
ResourceFactory.getResourceChangeScannerService().configure( sconf );
Knowledge Agents can take an empty Knowledge Base or a populated one.
If a populated Knowledge Base is provided, the Knowledge Agent will
run an iterator from Knowledge Base and subscribe to the resources that
it finds. While it is
possible for the Knowledge Builder to build all resources found in a
directory, that information is lost by the Knowledge Builder so that those
directories will not be continuously scanned. Only directories specified
as part of the applyChangeSet(Resource) method are monitored.
One of the advantages of providing KnowledgeBase as the starting
point is that you can provide it with a KnowledgeBaseConfiguration. When
resource changes are detected and a new KnowledgeBase object is
instantiated, it will use the KnowledgeBaseConfiguration of the previous
KnowledgeBase object.
Example 4.21. Using an existing KnowledgeBase
KnowledgeBaseConfiguration kbaseConf =
KnowledgeBaseFactory.createKnowledgeBaseConfiguration( null, cl );
KnowledgeBase kbase KnowledgeBaseFactory.newKnowledgeBase( kbaseConf );
// Populate kbase with resources here.
KnowledgeAgent kagent =
KnowledgeAgentFactory.newKnowledgeAgent( "MyAgent", kbase );
KnowledgeBase kbase = kagent.getKnowledgeBase();
In the above example getKnowledgeBase() will return the same
provided kbase instance until resource changes are detected and a new
Knowledge Base is built. When the new Knowledge Base is built, it will be
done with the KnowledgeBaseConfiguration that was provided to
the previous KnowledgeBase.
As mentioned previously, a ChangeSet XML can specify a directory and
all of its contents will be added. If this ChangeSet XML is used with the
applyChangeSet() method it will also add any directories to the scanning
process. When the directory scan detects an additional file, it will be
added to the Knowledge Base; any removed file is removed from the
Knowledge Base, and modified files will be removed from the Knowledge Base.
Example 4.22. ChangeSet XML which adds a directories contents
<change-set xmlns='http://drools.org/drools-5.0/change-set'
xmlns:xs='http://www.w3.org/2001/XMLSchema-instance'
xs:schemaLocation='http://drools.org/drools-5.0/change-set.xsd' >
<add>
<resource source='file:/projects/myproject/myrules' type='PKG' />
</add>
</change-set>
Note that for the resource type PKG the drools-compiler dependency is not needed as the Knowledge Agent is able to handle those with just drools-core.
The KnowledgeAgentConfiguration can be used to modify a
Knowledge Agent's default behavior. You could use this to load
the resources from a directory, while inhibiting the continuous scan
for changes of that directory.
Example 4.23. Change the Scanning Behavior
KnowledgeBase kbase = KnowledgeBaseFactory.newKnowledgeBase();
KnowledgeAgentConfiguration kaconf =
KnowledgeAgentFactory.newKnowledgeAgentConfiguation();
// Do not scan directories, just files.
kaconf.setProperty( "drools.agent.scanDirectories", "false" );
KnowledgeAgent kagent =
KnowledgeAgentFactory.newKnowledgeAgent( "test agent", kaconf );
Previously we mentioned Drools Guvnor and how it can build and publish serialized Knowledge Packages on a URL, and that the ChangeSet XML can handle URLs and Packages. Taken together, this forms an importanty deployment scenario for the Knowledge Agent.
The KnowlegeBase is a repository of all the
application's knowledge definitions. It will contain rules, processes,
functions, and type models. The Knowledge Base itself does not contain
data; instead, sessions are created from the KnowledgeBase
into which data can be inserted and from which process instances may be
started. Creating the KnowlegeBase can be heavy, whereas
session creation is very light, so it is recommended that Knowle Bases be
cached where possible to allow for repeated session creation.
Example 4.24. Creating a new KnowledgeBase
KnowledgeBase kbase = KnowledgeBaseFactory.newKnowledgeBase();
The StatefulKnowledgeSession stores and executes on the
runtime data. It is created from the KnowledgeBase.
Example 4.25. Create a StatefulKnowledgeSession from a KnowledgeBase
StatefulKnowledgeSession ksession = kbase.newStatefulKnowledgeSession();
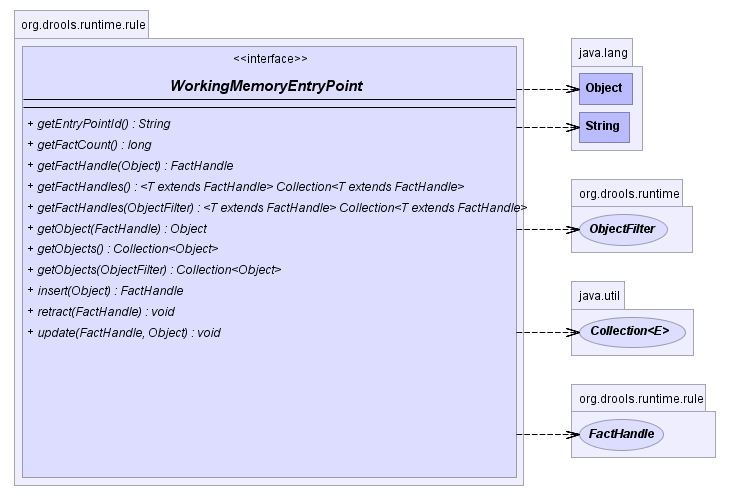
The WorkingMemoryEntryPoint provides the methods
around inserting, updating and retrieving facts. The term "entry point"
is related to the fact that we have multiple partitions in a Working
Memory and you can choose which one you are inserting into, although
this use case is aimed at event processing and covered in more detail in
the Fusion manual. Most rule based applications will work with the
default entry point alone.
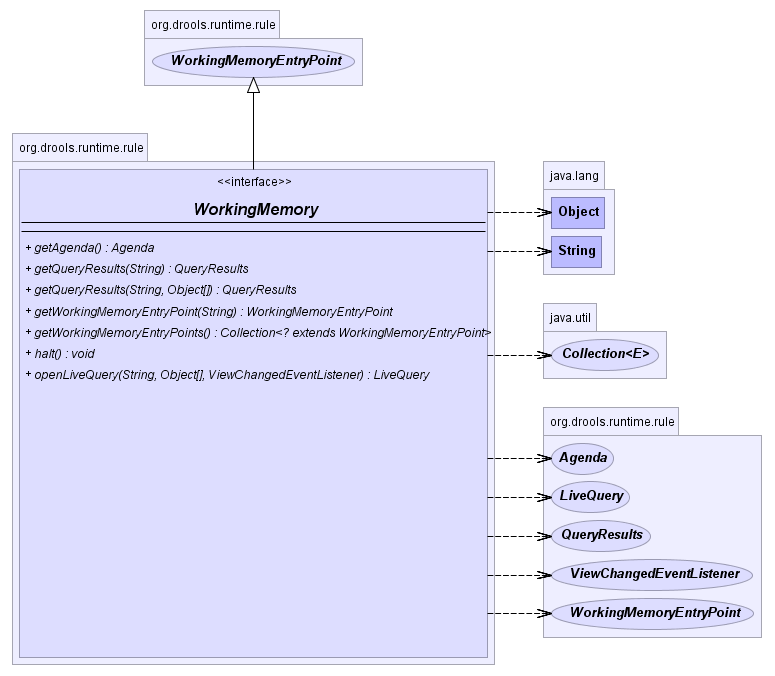
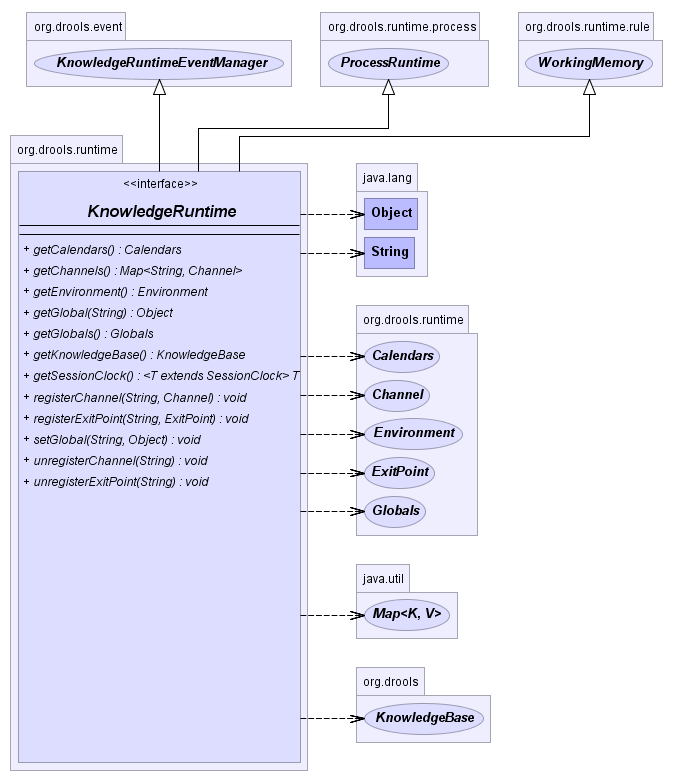
The KnowledgeRuntime interface provides the main
interaction with the engine. It is available in rule consequences and
process actions. In this manual the focus is on the methods and
interfaces related to rules, and the methods pertaining to processes
will be ignored for now. But you'll notice that the
KnowledgeRuntime inherits methods from both the
WorkingMemory and the ProcessRuntime, thereby
providing a unified API to work with processes and rules. When working
with rules, three interfaces form the KnowledgeRuntime:
WorkingMemoryEntryPoint, WorkingMemory and the
KnowledgeRuntime itself.
Insertion is the act of telling the WorkingMemory
about a fact, which you do by
ksession.insert(yourObject), for example. When you insert
a fact, it is examined for matches against the rules. This means
all of the work for deciding about firing or not
firing a rule is done during insertion; no rule, however, is executed
until you call fireAllRules(), which you call after you
have finished inserting your facts. It is a common misunderstanding
for people to think the condition evaluation happens when you call
fireAllRules(). Expert systems typically use the term
assert or assertion to refer
to facts made available to the system. However, due to "assert" being
a keyword in most languages, we have decided to use the
insert keyword; so expect to hear the two used
interchangeably.
When an Object is inserted it returns a FactHandle.
This FactHandle is the token used to represent your
inserted object within the WorkingMemory. It is also used
for interactions with the WorkingMemory when you wish to
retract or modify an object.
Cheese stilton = new Cheese("stilton");
FactHandle stiltonHandle = ksession.insert( stilton );
As mentioned in the Knowledge Base section, a Working Memory may operate in two assertion modes, i.e., equality or identity, with identity being the default.
Identity means that the Working Memory uses
an IdentityHashMap to store all asserted objects. New
instance assertions always result in the return of a new
FactHandle, but if an instance is asserted again then it
returns the original fact handle, i.e., it ignores repeated insertions
for the same fact.
Equality means that the Working Memory uses
a HashMap to store all asserted Objects. New instance
assertions will only return a new FactHandle if no equal
objects have been asserted.
Retraction is the removal of a fact from Working Memory, which
means that it will no longer track and match that fact, and any rules
that are activated and dependent on that fact will be cancelled. Note
that it is possible to have rules that depend on the nonexistence of a
fact, in which case retracting a fact may cause a rule to activate.
(See the not and exist keywords.) Retraction
is done using the FactHandle that was returned by the
insert call.
Cheese stilton = new Cheese("stilton");
FactHandle stiltonHandle = ksession.insert( stilton );
....
ksession.retract( stiltonHandle );
The Rule Engine must be notified of modified facts, so that they
can be reprocessed. Internally, modification is actually a retract
followed by an insert; the Rule Engine removes the fact from the
WorkingMemory and inserts it again. You must use the
update() method to notify the WorkingMemory
of changed objects for those objects that are not able to notify the
WorkingMemory themselves. Notice that
update() always takes the modified object as a second
parameter, which allows you to specify new instances for immutable
objects. The update() method can only be used with
objects that have shadow proxies turned on. The update method is only
available within Java code. On the right hand side of a rule, also the
modify statement is supported, providing simplified
calls to the object's setters.
Cheese stilton = new Cheese("stilton");
FactHandle stiltonHandle = workingMemory.insert( stilton );
...
stilton.setPrice( 100 );
workingMemory.update( stiltonHandle, stilton );
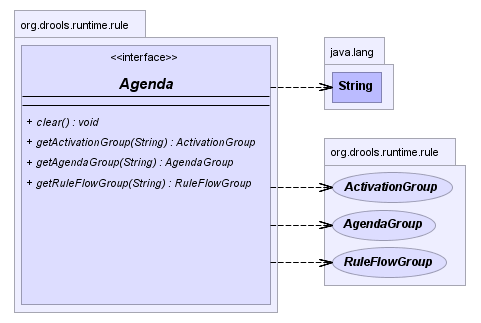
The WorkingMemory provides access to the Agenda, permits query executions, and lets you access named Enty Points.
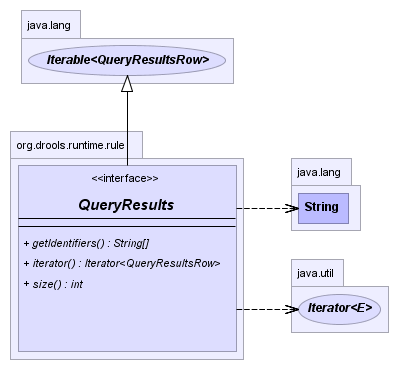
Queries are used to retrieve fact sets based on patterns, as they are used in rules. Patterns may make use of optional parameters. Queries can be defined in the Knowlege Base, from where they are called up to return the matching results. While iterating over the result collection, any bound identifier in the query can be accessed using the get(String identifier) method and any FactHandle for that identifier can be retrieved using getFactHandle(String identifier).
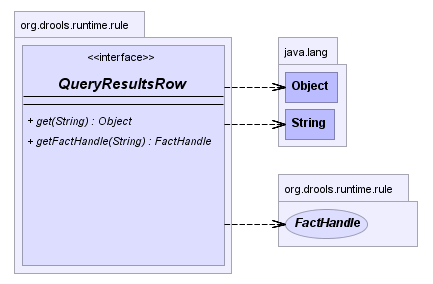
Example 4.26. Simple Query Example
QueryResults results =
ksession.getQueryResults( "my query", new Object[] { "string" } );
for ( QueryResultsRow row : results ) {
System.out.println( row.get( "varName" ) );
}
Drools has always had query support, but the result was returned as an iterable set; this makes it hard to monitor changes over time.
We have now complimented this with Live Querries, which has a listener attached instead of returning an iterable result set. These live querries stay open creating a view and publish change events for the contents of this view. So now you can execute your query, with parameters and listen to changes in the resulting view.
Example 4.27. Implementing ViewChangedEventListener
final List updated = new ArrayList();
final List removed = new ArrayList();
final List added = new ArrayList();
ViewChangedEventListener listener = new ViewChangedEventListener() {
public void rowUpdated(Row row) {
updated.add( row.get( "$price" ) );
}
public void rowRemoved(Row row) {
removed.add( row.get( "$price" ) );
}
public void rowAdded(Row row) {
added.add( row.get( "$price" ) );
}
};
// Open the LiveQuery
LiveQuery query = ksession.openLiveQuery( "cheeses",
new Object[] { "cheddar", "stilton" },
listener );
...
...
query.dispose() // make sure you call dispose when you want the query to close
A Drools blog article contains an example of Glazed Lists integration for live queries,
http://blog.athico.com/2010/07/glazed-lists-examples-for-drools-live.html
The KnowledgeRuntime provides further methods that
are applicable to both rules and processes, such as setting globals and
registering Channels (previously exit points, some
references may remain in docs for a while).
Globals are named objects that can be passed to the rule engine, without needing to insert them. Most often these are used for static information, or for services that are used in the RHS of a rule, or perhaps as a means to return objects from the rule engine. If you use a global on the LHS of a rule, make sure it is immutable. A global must first be declared in a rules file before it can be set on the session.
global java.util.List list
With the Knowledge Base now aware of the global identifier and
its type, it is now possible to call ksession.setGlobal()
for any session. Failure to declare the global type and identifier
first will result in an exception being thrown. To set the global on
the session use ksession.setGlobal(identifier,
value):
List list = new ArrayList();
ksession.setGlobal("list", list);
If a rule evaluates on a global before you set it you will get a
NullPointerException.
The StatefulRuleSession is inherited by the
StatefulKnowledgeSession and provides the rule related
methods that are relevant from outside of the engine.
AgendaFilter objects are optional implementations
of the filter interface which are used to allow or deny the firing of
an activation. What you filter on is entirely up to the
implementation. Drools 4.0 used to supply some out of the box filters,
which have not be exposed in drools 5.0 knowledge-api, but they are
simple to implement and the Drools 4.0 code base can be referred
to.
To use a filter specify it while calling
fireAllRules(). The following example permits only rules
ending in the string "Test". All others will be filtered
out.
ksession.fireAllRules( new RuleNameEndsWithAgendaFilter( "Test" ) );
The Agenda is a Rete feature. During actions on
the WorkingMemory, rules may become fully matched and
eligible for execution; a single Working Memory Action can result in
multiple eligible rules. When a rule is fully matched an Activation is
created, referencing the rule and the matched facts, and placed onto the
Agenda. The Agenda controls the execution order of these Activations using
a Conflict Resolution strategy.
The engine cycles repeatedly through two phases:
Working Memory Actions. This is where most of the work takes place, either in the Consequence (the RHS itself) or the main Java application process. Once the Consequence has finished or the main Java application process calls
fireAllRules()the engine switches to the Agenda Evaluation phase.Agenda Evaluation. This attempts to select a rule to fire. If no rule is found it exits, otherwise it fires the found rule, switching the phase back to Working Memory Actions.
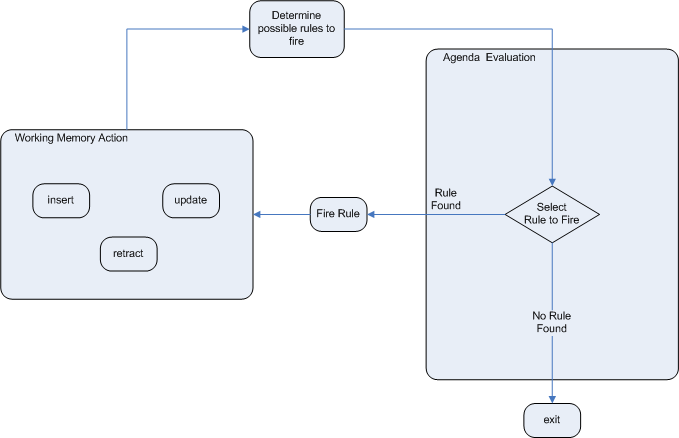
The process repeats until the agenda is clear, in which case control returns to the calling application. When Working Memory Actions are taking place, no rules are being fired.
Conflict resolution is required when there are multiple rules on the agenda. (The basics to this are covered in chapter "Quick Start".) As firing a rule may have side effects on the working memory, the rule engine needs to know in what order the rules should fire (for instance, firing ruleA may cause ruleB to be removed from the agenda).
The default conflict resolution strategies employed by Drools are: Salience and LIFO (last in, first out).
The most visible one is salience (or priority), in which case a user can specify that a certain rule has a higher priority (by giving it a higher number) than other rules. In that case, the rule with higher salience will be preferred. LIFO priorities are based on the assigned Working Memory Action counter value, with all rules created during the same action receiving the same value. The execution order of a set of firings with the same priority value is arbitrary.
As a general rule, it is a good idea not to count on rules firing in any particular order, and to author the rules without worrying about a "flow".
Drools 4.0 supported custom conflict resolution strategies; while this capability still exists in Drools it has not yet been exposed to the end user via knowledge-api in Drools 5.0.
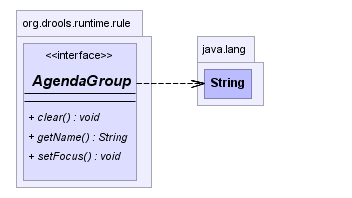
Agenda groups are a way to partition rules (activations, actually) on the agenda. At any one time, only one group has "focus" which means that activations for rules in that group only will take effect. You can also have rules with "auto focus" which means that the focus is taken for its agenda group when that rule's conditions are true.
Agenda groups are known as "modules" in CLIPS terminology. They provide a handy way to create a "flow" between grouped rules. You can switch the group which has focus either from within the rule engine, or via the API. If your rules have a clear need for multiple "phases" or "sequences" of processing, consider using agenda-groups for this purpose.
Each time setFocus() is called it pushes that Agenda
Group onto a stack. When the focus group is empty it is popped from the
stack and the focus group that is now on top evaluates. An Agenda Group
can appear in multiple locations on the stack. The default Agenda Group
is "MAIN", with all rules which do not specify an Agenda Group being in
this group. It is also always the first group on the stack, given focus
initially, by default.
ksession.getAgenda().getAgendaGroup( "Group A" ).setFocus();
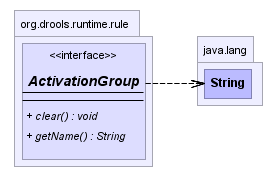
An activation group is a set of rules bound together by the same
"activation-group" rule attribute. In this group only one rule can fire,
and after that rule has fired all the other rules are cancelled from the
agenda. The clear() method can be called at any time, which
cancels all of the activations before one has had a chance to
fire.
ksession.getAgenda().getActivationGroup( "Group B" ).clear();
A rule flow group is a group of rules associated by the
"ruleflow-group" rule attribute. These rules can only fire when the
group is activate. The group itself can only become active when the
elaboration of the ruleflow diagram reaches the node representing the
group. Here too, the clear() method can be called at any
time to cancels all activations still remaining on the Agenda.
ksession.getAgenda().getRuleFlowGroup( "Group C" ).clear();
The event package provides means to be notified of rule engine events, including rules firing, objects being asserted, etc. This allows you, for instance, to separate logging and auditing activities from the main part of your application (and the rules).
The KnowlegeRuntimeEventManager interface is
implemented by the KnowledgeRuntime which provides two
interfaces, WorkingMemoryEventManager and
ProcessEventManager. We will only cover the
WorkingMemoryEventManager here.
The WorkingMemoryEventManager allows for listeners to
be added and removed, so that events for the working memory and the agenda
can be listened to.
The following code snippet shows how a simple agenda listener is declared and attached to a session. It will print activations after they have fired.
Example 4.28. Adding an AgendaEventListener
ksession.addEventListener( new DefaultAgendaEventListener() {
public void afterActivationFired(AfterActivationFiredEvent event) {
super.afterActivationFired( event );
System.out.println( event );
}
});
Drools also provides DebugWorkingMemoryEventListener
and DebugAgendaEventListener which implement each method with
a debug print statement. To print all Working Memory events, you add a
listener like this:
Example 4.29. Creating a new KnowledgeBuilder
ksession.addEventListener( new DebugWorkingMemoryEventListener() );
All emitted events implement the KnowlegeRuntimeEvent
interface which can be used to retrieve the actual
KnowlegeRuntime the event originated from.
The events currently supported are:
ActivationCreatedEvent
ActivationCancelledEvent
BeforeActivationFiredEvent
AfterActivationFiredEvent
AgendaGroupPushedEvent
AgendaGroupPoppedEvent
ObjectInsertEvent
ObjectRetractedEvent
ObjectUpdatedEvent
ProcessCompletedEvent
ProcessNodeLeftEvent
ProcessNodeTriggeredEvent
ProcessStartEvent
The KnowledgeRuntimeLogger uses the comprehensive event system in Drools to create an audit log that can be used to log the execution of an application for later inspection, using tools such as the Eclipse audit viewer.

Example 4.30. FileLogger
KnowledgeRuntimeLogger logger =
KnowledgeRuntimeLoggerFactory.newFileLogger(ksession, "logdir/mylogfile");
...
logger.close();
The StatelessKnowledgeSession wraps the
StatefulKnowledgeSession, instead of extending it. Its main
focus is on decision service type scenarios. It avoids the need to call
dispose(). Stateless sessions do not support iterative
insertions and the method call fireAllRules() from Java code;
the act of calling execute() is a single-shot method that
will internally instantiate a StatefulKnowledgeSession, add
all the user data and execute user commands, call
fireAllRules(), and then call dispose(). While
the main way to work with this class is via the
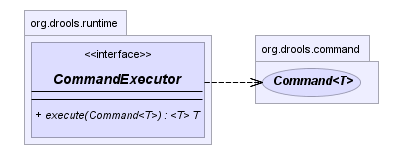
BatchExecution (a subinterface of Command) as
supported by the CommandExecutor interface, two convenience
methods are provided for when simple object insertion is all that's
required. The CommandExecutor and BatchExecution
are talked about in detail in their own section.
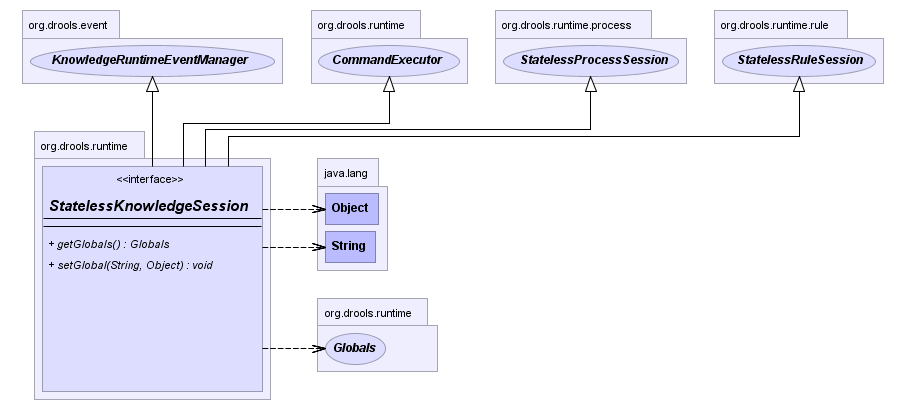
Our simple example shows a stateless session executing a given collection of Java objects using the convenience API. It will iterate the collection, inserting each element in turn.
Example 4.31. Simple StatelessKnowledgeSession execution with a Collection
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory.newKnowledgeBuilder();
kbuilder.add( ResourceFactory.newFileSystemResource( fileName ), ResourceType.DRL );
if (kbuilder.hasErrors() ) {
System.out.println( kbuilder.getErrors() );
} else {
KnowledgeBase kbase = KnowledgeBaseFactory.newKnowledgeBase();
kbase.addKnowledgePackages( kbuilder.getKnowledgePackages() );
StatelessKnowledgeSession ksession = kbase.newStatelessKnowledgeSession();
ksession.execute( collection );
}
If this was done as a single Command it would be as follows:
Example 4.32. Simple StatelessKnowledgeSession execution with InsertElements Command
ksession.execute( CommandFactory.newInsertElements( collection ) );
If you wanted to insert the collection itself, and the collection's
individual elements, then
CommandFactory.newInsert(collection) would do the job.
Methods of the CommandFactory create the supported
commands, all of which can be marshalled using XStream and the
BatchExecutionHelper. BatchExecutionHelper
provides details on the XML format as well as how to use Drools Pipeline
to automate the marshalling of BatchExecution and
ExecutionResults.
StatelessKnowledgeSession supports globals, scoped in a
number of ways. I'll cover the non-command way first, as commands are
scoped to a specific execution call. Globals can be resolved in three
ways.
The Stateless Knowledge Session method
getGlobals()returns a Globals instance which provides access to the session's globals. These are shared for all execution calls. Exercise caution regarding mutable globals because execution calls can be executing simultaneously in different threads.Example 4.33. Session scoped global
StatelessKnowledgeSession ksession = kbase.newStatelessKnowledgeSession();
// Set a global hbnSession, that can be used for DB interactions in the rules.
ksession.setGlobal( "hbnSession", hibernateSession );
// Execute while being able to resolve the "hbnSession" identifier.
ksession.execute( collection );Using a delegate is another way of global resolution. Assigning a value to a global (with
setGlobal(String, Object)) results in the value being stored in an internal collection mapping identifiers to values. Identifiers in this internal collection will have priority over any supplied delegate. Only if an identifier cannot be found in this internal collection, the delegate global (if any) will be used.The third way of resolving globals is to have execution scoped globals. Here, a
Commandto set a global is passed to theCommandExecutor.
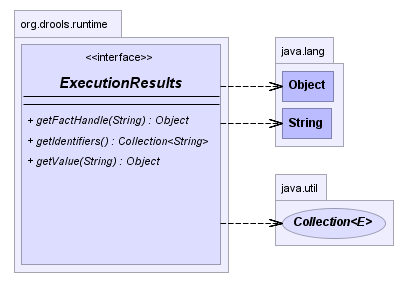
The CommandExecutor interface also offers the ability
to export data via "out" parameters. Inserted facts, globals and query
results can all be returned.
Example 4.34. Out identifiers
// Set up a list of commands
List cmds = new ArrayList();
cmds.add( CommandFactory.newSetGlobal( "list1", new ArrayList(), true ) );
cmds.add( CommandFactory.newInsert( new Person( "jon", 102 ), "person" ) );
cmds.add( CommandFactory.newQuery( "Get People" "getPeople" );
// Execute the list
ExecutionResults results =
ksession.execute( CommandFactory.newBatchExecution( cmds ) );
// Retrieve the ArrayList
results.getValue( "list1" );
// Retrieve the inserted Person fact
results.getValue( "person" );
// Retrieve the query as a QueryResults instance.
results.getValue( "Get People" );
With Rete you have a stateful session where objects can be asserted and modified over time, and where rules can also be added and removed. Now what happens if we assume a stateless session, where after the initial data set no more data can be asserted or modified and rules cannot be added or removed? Certainly it won't be necessary to re-evaluate rules, and the engine will be able to operate in a simplified way.
Order the Rules by salience and position in the ruleset (by setting a sequence attribute on the rule terminal node).
Create an array, one element for each possible rule activation; element position indicates firing order.
Turn off all node memories, except the right-input Object memory.
Disconnect the Left Input Adapter Node propagation, and let the Object plus the Node be referenced in a Command object, which is added to a list on the Working Memory for later execution.
Assert all objects, and, when all assertions are finished and thus right-input node memories are populated, check the Command list and execute each in turn.
All resulting Activations should be placed in the array, based upon the determined sequence number of the Rule. Record the first and last populated elements, to reduce the iteration range.
Iterate the array of Activations, executing populated element in turn.
If we have a maximum number of allowed rule executions, we can exit our network evaluations early to fire all the rules in the array.
The LeftInputAdapterNode no longer creates a Tuple,
adding the Object, and then propagate the Tuple – instead a Command
object is created and added to a list in the Working Memory. This
Command object holds a reference to the
LeftInputAdapterNode and the propagated object. This stops
any left-input propagations at insertion time, so that we know that a
right-input propagation will never need to attempt a join with the
left-inputs (removing the need for left-input memory). All nodes have
their memory turned off, including the left-input Tuple memory but
excluding the right-input object memory, which means that the only node
remembering an insertion propagation is the right-input object memory.
Once all the assertions are finished and all right-input memories
populated, we can then iterate the list of
LeftInputAdatperNode Command objects calling each in turn.
They will propagate down the network attempting to join with the
right-input objects, but they won't be remembered in the left input as
we know there will be no further object assertions and thus propagations
into the right-input memory.
There is no longer an Agenda, with a priority queue to schedule
the Tuples; instead, there is simply an array for the number of rules.
The sequence number of the RuleTerminalNode indicates the
element within the array where to place the Activation. Once all Command
objects have finished we can iterate our array, checking each element in
turn, and firing the Activations if they exist. To improve performance,
we remember the first and the last populated cell in the array. The
network is constructed, with each RuleTerminalNode being
given a sequence number based on a salience number and its order of
being added to the network.
Typically the right-input node memories are Hash Maps, for fast object retraction; here, as we know there will be no object retractions, we can use a list when the values of the object are not indexed. For larger numbers of objects indexed Hash Maps provide a performance increase; if we know an object type has only a few instances, indexing is probably not advantageous, and a list can be used.
Sequential mode can only be used with a Stateless Session and is
off by default. To turn it on, either call
RuleBaseConfiguration.setSequential(true), or set the
rulebase configuration property drools.sequential to true.
Sequential mode can fall back to a dynamic agenda by calling
setSequentialAgenda with
SequentialAgenda.DYNAMIC. You may also set the
"drools.sequential.agenda" property to "sequential" or "dynamic".
Drools has the concept of stateful or stateless sessions. We've already covered stateful sessions, which use the standard working memory that can be worked with iteratively over time. Stateless is a one-off execution of a working memory with a provided data set. It may return some results, with the session being disposed at the end, prohibiting further iterative interactions. You can think of stateless as treating a rule engine like a function call with optional return results.
In Drools 4 we supported these two paradigms but the way the user
interacted with them was different. StatelessSession used an execute(...)
method which would insert a collection of objects as facts.
StatefulSession didn't have this method, and insert used the more
traditional insert(...) method. The other issue was that the
StatelessSession did not return any results, so that users themselves had
to map globals to get results, and it wasn't possible to do anything
besides inserting objects; users could not start processes or execute
queries.
Drools 5.0 addresses all of these issues and more. The foundation
for this is the CommandExecutor interface, which both the
stateful and stateless interfaces extend, creating consistency and
ExecutionResults:
The CommandFactory allows for commands to be executed
on those sessions, the only difference being that the Stateless Knowledge
Session executes fireAllRules() at the end before disposing
the session. The currently supported commands are:
FireAllRules
GetGlobal
SetGlobal
InsertObject
InsertElements
Query
StartProcess
BatchExecution
InsertObject will insert a single object, with an
optional "out" identifier. InsertElements will iterate an
Iterable, inserting each of the elements. What this means is that a
Stateless Knowledge Session is no longer limited to just inserting
objects, it can now start processes or execute queries, and do this in any
order.
Example 4.35. Insert Command
StatelessKnowledgeSession ksession = kbase.newStatelessKnowledgeSession();
ExecutionResults bresults =
ksession.execute( CommandFactory.newInsert( new Cheese( "stilton" ), "stilton_id" ) );
Stilton stilton = bresults.getValue( "stilton_id" );
The execute method always returns an ExecutionResults
instance, which allows access to any command results if they specify an
out identifier such as the "stilton_id" above.
Example 4.36. InsertElements Command
StatelessKnowledgeSession ksession = kbase.newStatelessKnowledgeSession();
Command cmd = CommandFactory.newInsertElements( Arrays.asList( Object[] {
new Cheese( "stilton" ),
new Cheese( "brie" ),
new Cheese( "cheddar" ),
});
ExecutionResults bresults = ksession.execute( cmd );
The execute method only allows for a single command. That's where
BatchExecution comes in, which represents a composite
command, created from a list of commands. Now, execute will iterate over
the list and execute each command in turn. This means you can insert some
objects, start a process, call fireAllRules and execute a query, all in a
single execute(...) call, which is quite powerful.
As mentioned previosly, the Stateless Knowledge Session will execute
fireAllRules() automatically at the end. However the
keen-eyed reader probably has already noticed the
FireAllRules command and wondered how that works with a
StatelessKnowledgeSession. The FireAllRules command is
allowed, and using it will disable the automatic execution at the end;
think of using it as a sort of manual override function.
Commands support out identifiers. Any command that has an out identifier set on it will add its results to the returned ExecutionResults instance. Let's look at a simple example to see how this works.
Example 4.37. BatchExecution Command
StatelessKnowledgeSession ksession = kbase.newStatelessKnowledgeSession();
List cmds = new ArrayList();
cmds.add( CommandFactory.newInsertObject( new Cheese( "stilton", 1), "stilton") );
cmds.add( CommandFactory.newStartProcess( "process cheeses" ) );
cmds.add( CommandFactory.newQuery( "cheeses" ) );
ExecutionResults bresults = ksession.execute( CommandFactory.newBatchExecution( cmds ) );
Cheese stilton = ( Cheese ) bresults.getValue( "stilton" );
QueryResults qresults = ( QueryResults ) bresults.getValue( "cheeses" );
In the above example multiple commands are executed, two of which
populate the ExecutionResults. The query command defaults to
use the same identifier as the query name, but it can also be mapped to a
different identifier.
A custom XStream marshaller can be used with the Drools Pipeline to
achieve XML scripting, which is perfect for services. Here are two simple
XML samples, one for the BatchExecution and one for the
ExecutionResults.
Example 4.38. Simple BatchExecution XML
<batch-execution>
<insert out-identifier='outStilton'>
<org.drools.Cheese>
<type>stilton</type>
<price>25</price>
<oldPrice>0</oldPrice>
</org.drools.Cheese>
</insert>
</batch-execution>
Example 4.39. Simple ExecutionResults XML
<execution-results>
<result identifier='outStilton'>
<org.drools.Cheese>
<type>stilton</type>
<oldPrice>25</oldPrice>
<price>30</price>
</org.drools.Cheese>
</result>
</execution-results>
Spring and Camel, covered in the integrations book, facilitate declarative services.
Example 4.40. BatchExecution Marshalled to XML
<batch-execution>
<insert out-identifier="stilton">
<org.drools.Cheese>
<type>stilton</type>
<price>1</price>
<oldPrice>0</oldPrice>
</org.drools.Cheese>
</insert>
<query out-identifier='cheeses2' name='cheesesWithParams'>
<string>stilton</string>
<string>cheddar</string>
</query>
</batch-execution>
The CommandExecutor returns an
ExecutionResults, and this is handled by the pipeline code
snippet as well. A similar output for the <batch-execution> XML
sample above would be:
Example 4.41. ExecutionResults Marshalled to XML
<execution-results>
<result identifier="stilton">
<org.drools.Cheese>
<type>stilton</type>
<price>2</price>
</org.drools.Cheese>
</result>
<result identifier='cheeses2'>
<query-results>
<identifiers>
<identifier>cheese</identifier>
</identifiers>
<row>
<org.drools.Cheese>
<type>cheddar</type>
<price>2</price>
<oldPrice>0</oldPrice>
</org.drools.Cheese>
</row>
<row>
<org.drools.Cheese>
<type>cheddar</type>
<price>1</price>
<oldPrice>0</oldPrice>
</org.drools.Cheese>
</row>
</query-results>
</result>
</execution-results>
The BatchExecutionHelper provides a configured XStream
instance to support the marshalling of Batch Executions, where the
resulting XML can be used as a message format, as shown above. Configured
converters only exist for the commands supported via the Command Factory.
The user may add other converters for their user objects. This is very
useful for scripting stateless or stateful knowledge sessions, especially
when services are involved.
There is currently no XML schema to support schema validation. The
basic format is outlined here, and the drools-pipeline module
has an illustrative unit test in the
XStreamBatchExecutionTest unit test. The root element is
<batch-execution> and it can contain zero or more commands
elements.
This contains a list of elements that represent commands, the supported commands is limited to those Commands provided by the Command Factory. The most basic of these is the <insert> element, which inserts objects. The contents of the insert element is the user object, as dictated by XStream.
Example 4.43. Insert
<batch-execution>
<insert>
...<!-- any user object -->
</insert>
</batch-execution>
The insert element features an "out-identifier" attribute, demanding that the inserted object will also be returned as part of the result payload.
Example 4.44. Insert with Out Identifier Command
<batch-execution>
<insert out-identifier='userVar'>
...
</insert>
</batch-execution>
It's also possible to insert a collection of objects using the
<insert-elements> element. This command does not support an
out-identifier. The org.domain.UserClass is just an
illustrative user object that XStream would serialize.
Example 4.45. Insert Elements command
<batch-execution>
<insert-elements>
<org.domain.UserClass>
...
</org.domain.UserClass>
<org.domain.UserClass>
...
</org.domain.UserClass>
<org.domain.UserClass>
...
</org.domain.UserClass>
</insert-elements>
</batch-execution>
Next, there is the <set-global> element, which
sets a global for the session.
Example 4.46. Insert Elements command
<batch-execution>
<set-global identifier='userVar'>
<org.domain.UserClass>
...
</org.domain.UserClass>
</set-global>
</batch-execution>
<set-global> also supports two other optional
attributes, out and out-identifier.
A true value for the boolean out will add the global to
the <batch-execution-results> payload, using the name
from the identifier attribute.
out-identifier works like out but
additionally allows you to override the identifier used in the
<batch-execution-results> payload.
Example 4.47. Set Global Command
<batch-execution>
<set-global identifier='userVar1' out='true'>
<org.domain.UserClass>
...
</org.domain.UserClass>
</set-global>
<set-global identifier='userVar2' out-identifier='alternativeUserVar2'>
<org.domain.UserClass>
...
</org.domain.UserClass>
</set-global>
</batch-execution>
There is also a <get-global> element, without
contents, with just an out-identifier attribute. (There
is no need for an out attribute because retrieving the
value is the sole purpose of a <get-global>
element.
Example 4.48. Get Global Command
<batch-execution>
<get-global identifier='userVar1' />
<get-global identifier='userVar2' out-identifier='alternativeUserVar2'/>
</batch-execution>
While the out attribute is useful in returning
specific instances as a result payload, we often wish to run actual
queries. Both parameter and parameterless queries are supported. The
name attribute is the name of the query to be called,
and the out-identifier is the identifier to be used for
the query results in the <execution-results>
payload.
Example 4.49. Query Command
<batch-execution>
<query out-identifier='cheeses' name='cheeses'/>
<query out-identifier='cheeses2' name='cheesesWithParams'>
<string>stilton</string>
<string>cheddar</string>
</query>
</batch-execution>
The <start-process> command accepts optional
parameters. Other process related methods will be added later, like
interacting with work items.
Example 4.50. Start Process Command
<batch-execution>
<startProcess processId='org.drools.actions'>
<parameter identifier='person'>
<org.drools.TestVariable>
<name>John Doe</name>
</org.drools.TestVariable>
</parameter>
</startProcess>
</batch-execution
Example 4.51. Signal Event Command
<signal-event process-instance-id='1' event-type='MyEvent'>
<string>MyValue</string>
</signal-event>
Example 4.52. Complete Work Item Command
<complete-work-item id='" + workItem.getId() + "' >
<result identifier='Result'>
<string>SomeOtherString</string>
</result>
</complete-work-item>
Support for more commands will be added over time.
The MarshallerFactory is used to marshal and unmarshal
Stateful Knowledge Sessions.
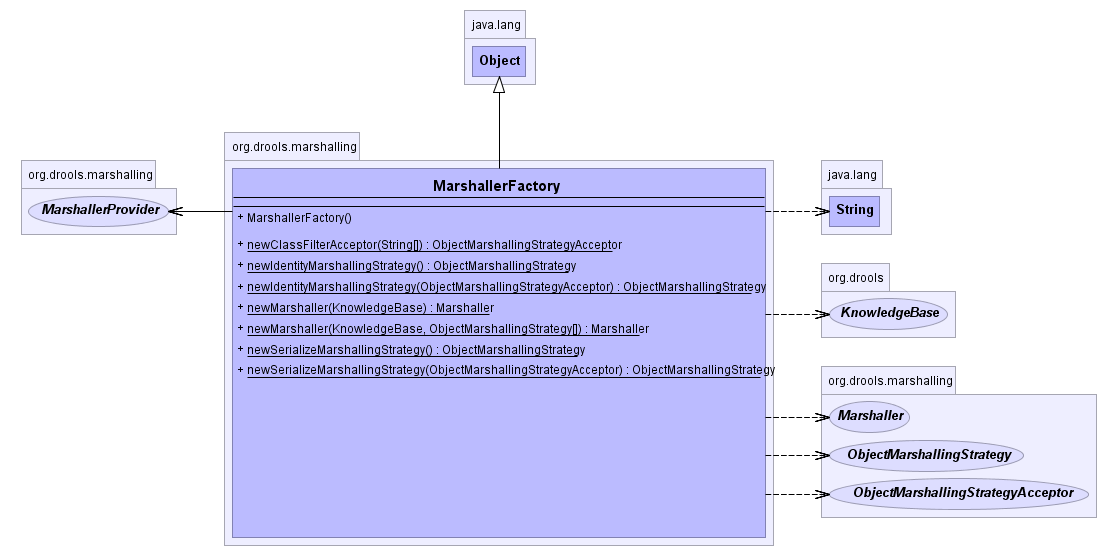
At the simplest the MarshallerFactory can be used as
follows:
Example 4.54. Simple Marshaller Example
// ksession is the StatefulKnowledgeSession
// kbase is the KnowledgeBase
ByteArrayOutputStream baos = new ByteArrayOutputStream();
Marshaller marshaller = MarshallerFactory.newMarshaller( kbase );
marshaller.marshall( baos, ksession );
baos.close();
However, with marshalling you need more flexibility when dealing
with referenced user data. To achieve this we have the
ObjectMarshallingStrategy interface. Two implementations are
provided, but users can implement their own. The two supplied strategies
are IdentityMarshallingStrategy and
SerializeMarshallingStrategy.
SerializeMarshallingStrategy is the default, as used in the
example above, and it just calls the Serializable or
Externalizable methods on a user instance.
IdentityMarshallingStrategy instead creates an integer id for
each user object and stores them in a Map, while the id is written to the
stream. When unmarshalling it accesses the
IdentityMarshallingStrategy map to retrieve the instance.
This means that if you use the IdentityMarshallingStrategy,
it is stateful for the life of the Marshaller instance and will create ids
and keep references to all objects that it attempts to marshal. Below is
he code to use an Identity Marshalling Strategy.
Example 4.55. IdentityMarshallingStrategy
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectMarshallingStrategy oms = MarshallerFactory.newIdentityMarshallingStrategy()
Marshaller marshaller =
MarshallerFactory.newMarshaller( kbase, new ObjectMarshallingStrategy[]{ oms } );
marshaller.marshall( baos, ksession );
baos.close();
For added flexability we can't assume that a single strategy is
suitable. Therefore we have added the
ObjectMarshallingStrategyAcceptor interface that each Object
Marshalling Strategy contains. The Marshaller has a chain of strategies,
and when it attempts to read or write a user object it iterates the
strategies asking if they accept responsability for marshalling the user
object. One of the provided implementations is
ClassFilterAcceptor. This allows strings and wild cards to be
used to match class names. The default is "*.*", so in the above example
the Identity Marshalling Strategy is used which has a default "*.*"
acceptor.
Assuming that we want to serialize all classes except for one given package, where we will use identity lookup, we could do the following:
Example 4.56. IdentityMarshallingStrategy with Acceptor
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectMarshallingStrategyAcceptor identityAcceptor =
MarshallerFactory.newClassFilterAcceptor( new String[] { "org.domain.pkg1.*" } );
ObjectMarshallingStrategy identityStrategy =
MarshallerFactory.newIdentityMarshallingStrategy( identityAcceptor );
ObjectMarshallingStrategy sms = MarshallerFactory.newSerializeMarshallingStrategy();
Marshaller marshaller =
MarshallerFactory.newMarshaller( kbase,
new ObjectMarshallingStrategy[]{ identityStrategy, sms } );
marshaller.marshall( baos, ksession );
baos.close();
Note that the acceptance checking order is in the natural order of the supplied array.
Longterm out of the box persistence with Java Persistence API (JPA) is possible with Drools. You will need to have some implementation of the Java Transaction API (JTA) installed. For development purposes we recommend the Bitronix Transaction Manager, as it's simple to set up and works embedded, but for production use JBoss Transactions is recommended.
Example 4.57. Simple example using transactions
Environment env = KnowledgeBaseFactory.newEnvironment();
env.set( EnvironmentName.ENTITY_MANAGER_FACTORY,
Persistence.createEntityManagerFactory( "emf-name" ) );
env.set( EnvironmentName.TRANSACTION_MANAGER,
TransactionManagerServices.getTransactionManager() );
// KnowledgeSessionConfiguration may be null, and a default will be used
StatefulKnowledgeSession ksession =
JPAKnowledgeService.newStatefulKnowledgeSession( kbase, null, env );
int sessionId = ksession.getId();
UserTransaction ut =
(UserTransaction) new InitialContext().lookup( "java:comp/UserTransaction" );
ut.begin();
ksession.insert( data1 );
ksession.insert( data2 );
ksession.startProcess( "process1" );
ut.commit();
To use a JPA, the Environment must be set with both the
EntityManagerFactory and the TransactionManager.
If rollback occurs the ksession state is also rolled back, so you can
continue to use it after a rollback. To load a previously persisted
Stateful Knowledge Session you'll need the id, as shown below:
Example 4.58. Loading a StatefulKnowledgeSession
StatefulKnowledgeSession ksession =
JPAKnowledgeService.loadStatefulKnowledgeSession( sessionId, kbase, null, env );
To enable persistence several classes must be added to your persistence.xml, as in the example below:
Example 4.59. Configuring JPA
<persistence-unit name="org.drools.persistence.jpa" transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>jdbc/BitronixJTADataSource</jta-data-source>
<class>org.drools.persistence.session.SessionInfo</class>
<class>org.drools.persistence.processinstance.ProcessInstanceInfo</class>
<class>org.drools.persistence.processinstance.ProcessInstanceEventInfo</class>
<class>org.drools.persistence.processinstance.WorkItemInfo</class>
<properties>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<property name="hibernate.max_fetch_depth" value="3"/>
<property name="hibernate.hbm2ddl.auto" value="update" />
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.transaction.manager_lookup_class"
value="org.hibernate.transaction.BTMTransactionManagerLookup" />
</properties>
</persistence-unit>
The jdbc JTA data source would have to be configured first. Bitronix provides a number of ways of doing this, and its documentation should be contsulted for details. For a quick start, here is the programmatic approach:
Example 4.60. Configuring JTA DataSource
PoolingDataSource ds = new PoolingDataSource();
ds.setUniqueName( "jdbc/BitronixJTADataSource" );
ds.setClassName( "org.h2.jdbcx.JdbcDataSource" );
ds.setMaxPoolSize( 3 );
ds.setAllowLocalTransactions( true );
ds.getDriverProperties().put( "user", "sa" );
ds.getDriverProperties().put( "password", "sasa" );
ds.getDriverProperties().put( "URL", "jdbc:h2:mem:mydb" );
ds.init();
Bitronix also provides a simple embedded JNDI service, ideal for testing. To use it add a jndi.properties file to your META-INF and add the following line to it:
Example 4.61. JNDI properties
java.naming.factory.initial=bitronix.tm.jndi.BitronixInitialContextFactory
Drools Clips is an alpha level research project to provide a Clips like front end ot Drools.
Deftemplates are working, the knowledge base handles multiple name spaces and you can attach the knoweldge base to the session for interative building, to provide a more "shell" like environment suitable for Clips.
deftemplate
defrule
deffunction
and/or/not/exists/test conditional elements
Literal, Variable, Return Value and Predicate field constarints

This project is very early stages and in need of love. If you want to help, open up eclipse import api, core, compiler and clips and you should be good to go. The unit tests should be self explanatory.