After regular inserts you have to retract facts explicitly. With logical assertions, the fact that was asserted will be automatically retracted when the conditions that asserted it in the first place are no longer true. Actually, it's even cleverer then that, because it will be retracted only if there isn't any single condition that supports the logical assertion.
Normal insertions are said to be stated, i.e.,
just like the intuitive meaning of "stating a fact" implies. Using a
HashMap and a counter, we track how many times a particular
equality is stated; this means we count how many
different instances are equal.
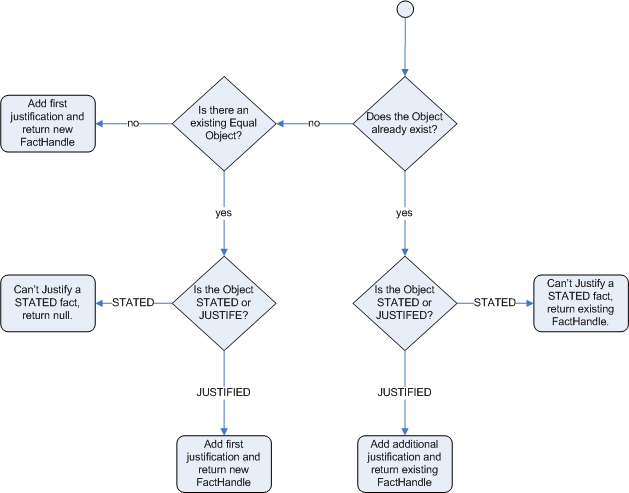
When we logically insert an object during a RHS execution we are said to justify it, and it is considered to be justified by the firing rule. For each logical insertion there can only be one equal object, and each subsequent equal logical insertion increases the justification counter for this logical assertion. A justification is removed by the LHS of the creating rule becoming untrue, and the counter is decreased accordingly. As soon as we have no more justifications the logical object is automatically retracted.
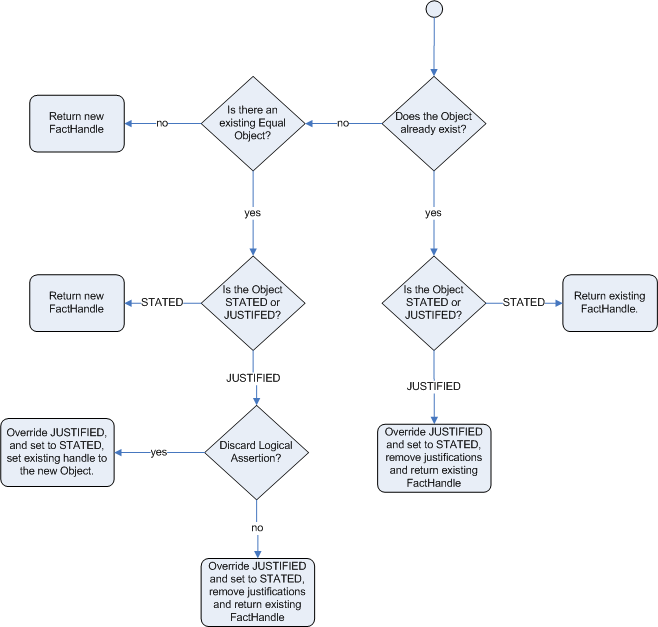
If we try to logically insert an object when
there is an equal stated object, this will fail and
return null. If we state an object that has an
existing equal object that is justified we override
the Fact; how this override works depends on the configuration setting
WM_BEHAVIOR_PRESERVE. When the property is set to discard we
use the existing handle and replace the existing instance with the new
Object, which is the default behavior; otherwise we override it to
stated but we create an new
FactHandle.
This can be confusing on a first read, so hopefully the flow charts
below help. When it says that it returns a new FactHandle,
this also indicates the Object was propagated through the
network.
An example may make things clearer. Imagine a credit card processing application, processing transactions for a given account and we have a working memory accumulating knowledge about a single account transaction. The rule engine is doing its best to decide whether transactions are possibly fraudulent or not. Imagine that this rule base basically has rules that kick in when there is "reason to be suspicious" and when "everything is normal".
Of course there are many rules that operate no matter what, performing standard calculations, etc. Now there are possibly many reasons as to what could trigger a "reason to be suspicious": someone notifying the bank, a sequence of large transactions, transactions for geographically disparate locations, or even reports of credit card theft. Rather then smattering all the little conditions in lots of rules, imagine there is a fact class called "SuspiciousAccount".
Then there can be a series of rules whose job is to look for things that may raise suspicion, and if they fire, they logically insert a new SuspiciousAccount() instance. All the other rules just have conditions like "not SuspiciousAccount()" or "SuspiciousAccount()" depending on their needs. Note that this has the advantage of allowing there to be many rules around raising suspicion, without touching the other rules. After all the facts causing the SuspiciousAccount() insertion are removed, the account handling reverts to a normal mode of operation where, for instance, a rule with "not SuspiciousAccount()" may kick in, which flushes through any blocked transactions.
If you have followed this far, you will note that truth maintenance, like logical assertions, allows rules to behave a little like a human would, and can certainly make the rules more manageable.
You no longer need to enable or disable truth maintenance, via the kbase configuration. It is now handled automatically and turned on only when needed. This was done along with the code changes so that all entry points use the same code, previous to this the default entry point and named entry points used different code, to avoid TMS overhead for event processing.
It is important to note that for Truth Maintenance (and logical assertions) to work at all, your Fact objects (which may be JavaBeans) must override equals and hashCode methods (from java.lang.Object) correctly. As the truth maintenance system needs to know when two different physical objects are equal in value, both equals and hashCode must be overridden correctly, as per the Java standard.
Two objects are equal if and only if their equals methods return true for each other and if their hashCode methods return the same values. See the Java API for more details (but do keep in mind you MUST override both equals and hashCode).
The Rete algorithm was invented by Dr. Charles Forgy and documented in his PhD thesis in 1978-79. A simplified version of the paper was published in 1982 (http://citeseer.ist.psu.edu/context/505087/0). The latin word "rete" means "net" or "network". The Rete algorithm can be broken into 2 parts: rule compilation and runtime execution.
The compilation algorithm describes how the Rules in the Production Memory are processed to generate an efficient discrimination network. In non-technical terms, a discrimination network is used to filter data as it propagates through the network. The nodes at the top of the network would have many matches, and as we go down the network, there would be fewer matches. At the very bottom of the network are the terminal nodes. In Dr. Forgy's 1982 paper, he described 4 basic nodes: root, 1-input, 2-input and terminal.
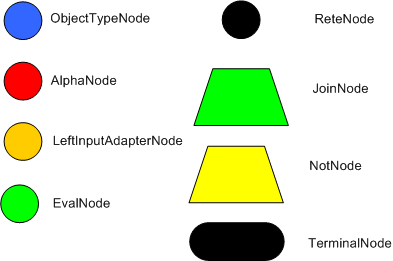
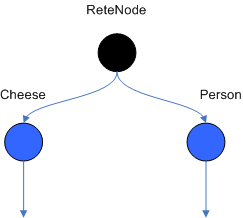
The root node is where all objects enter the network. From there, it
immediately goes to the ObjectTypeNode. The purpose of the ObjectTypeNode
is to make sure the engine doesn't do more work than it needs to. For
example, say we have 2 objects: Account and Order. If the rule engine
tried to evaluate every single node against every object, it would waste a
lot of cycles. To make things efficient, the engine should only pass the
object to the nodes that match the object type. The easiest way to do this
is to create an ObjectTypeNode and have all 1-input and 2-input nodes
descend from it. This way, if an application asserts a new Account, it
won't propagate to the nodes for the Order object. In Drools when an
object is asserted it retrieves a list of valid ObjectTypesNodes via a
lookup in a HashMap from the object's Class; if this list doesn't exist it
scans all the ObjectTypeNodes finding valid matches which it caches in the
list. This enables Drools to match against any Class type that matches
with an instanceof check.
ObjectTypeNodes can propagate to AlphaNodes, LeftInputAdapterNodes
and BetaNodes. AlphaNodes are used to evaluate literal conditions.
Although the 1982 paper only covers equality conditions, many RETE
implementations support other operations. For example, Account.name
== "Mr Trout" is a literal condition. When a rule has multiple
literal conditions for a single object type, they are linked together.
This means that if an application asserts an Account object, it must first
satisfy the first literal condition before it can proceed to the next
AlphaNode. In Dr. Forgy's paper, he refers to these as IntraElement
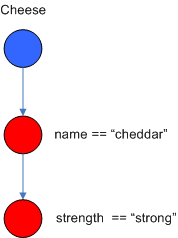
conditions. The following diagram shows the AlphaNode combinations for
Cheese( name == "cheddar", strength == "strong" ):
Drools extends Rete by optimizing the propagation from ObjectTypeNode to AlphaNode using hashing. Each time an AlphaNode is added to an ObjectTypeNode it adds the literal value as a key to the HashMap with the AlphaNode as the value. When a new instance enters the ObjectType node, rather than propagating to each AlphaNode, it can instead retrieve the correct AlphaNode from the HashMap,thereby avoiding unnecessary literal checks.
There are two two-input nodes, JoinNode and NotNode, and both are types of BetaNodes. BetaNodes are used to compare 2 objects, and their fields, to each other. The objects may be the same or different types. By convention we refer to the two inputs as left and right. The left input for a BetaNode is generally a list of objects; in Drools this is a Tuple. The right input is a single object. Two Nodes can be used to implement 'exists' checks. BetaNodes also have memory. The left input is called the Beta Memory and remembers all incoming tuples. The right input is called the Alpha Memory and remembers all incoming objects. Drools extends Rete by performing indexing on the BetaNodes. For instance, if we know that a BetaNode is performing a check on a String field, as each object enters we can do a hash lookup on that String value. This means when facts enter from the opposite side, instead of iterating over all the facts to find valid joins, we do a lookup returning potentially valid candidates. At any point a valid join is found the Tuple is joined with the Object; which is referred to as a partial match; and then propagated to the next node.
To enable the first Object, in the above case Cheese, to enter the network we use a LeftInputNodeAdapter - this takes an Object as an input and propagates a single Object Tuple.
Terminal nodes are used to indicate a single rule having matched all its conditions; at this point we say the rule has a full match. A rule with an 'or' conditional disjunctive connective results in subrule generation for each possible logically branch; thus one rule can have multiple terminal nodes.
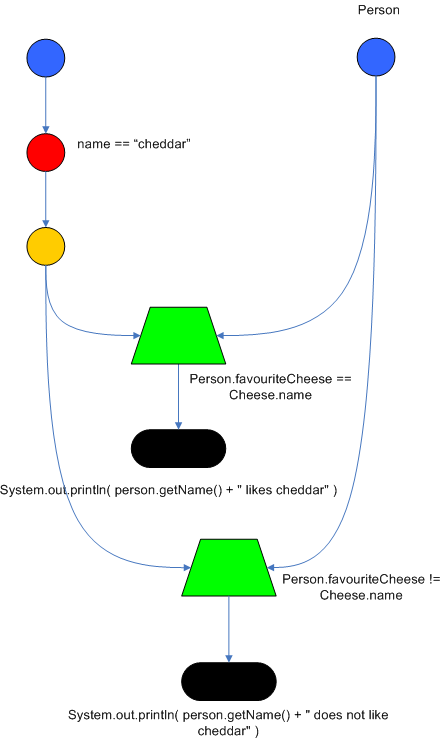
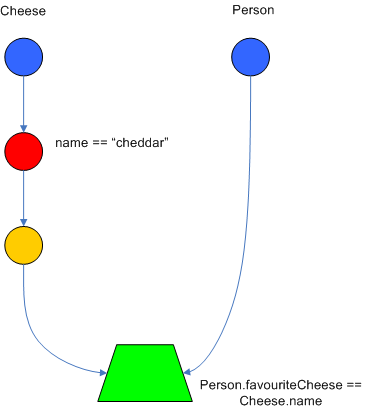
Drools also performs node sharing. Many rules repeat the same patterns, and node sharing allows us to collapse those patterns so that they don't have to be re-evaluated for every single instance. The following two rules share the first pattern, but not the last:
rule
when
Cheese( $chedddar : name == "cheddar" )
$person : Person( favouriteCheese == $cheddar )
then
System.out.println( $person.getName() + " likes cheddar" );
end
rule
when
Cheese( $chedddar : name == "cheddar" )
$person : Person( favouriteCheese != $cheddar )
then
System.out.println( $person.getName() + " does not like cheddar" );
end
As you can see below, the compiled Rete network shows that the alpha node is shared, but the beta nodes are not. Each beta node has its own TerminalNode. Had the second pattern been the same it would have also been shared.