Drools Planner supports several solver types, but you're probably wondering which is the best one? Although some solver types generally perform better then others, it really depends on your problem domain. Most solver types also have settings which can be tweaked. Those settings can influence the results of a solver a lot, although most settings perform pretty good out-of-the-box.
Luckily, Drools Planner includes a benchmarker, which allows you to play out different solver types and different settings against each other, so you can pick the best configuration for your problem domain.
The Benchmarker is current in the drools-planner-core modules, but it requires an extra dependency on the JFreeChart library.
If you use maven, add a dependency in your pom.xml file:
<dependency>
<groupId>jfree</groupId>
<artifactId>jfreechart</artifactId>
<version>1.0.13</version>
</dependency>This is similar for gradle, ivy and buildr.
If you use ANT, you've probably already copied the required jars from the download zip's
binaries directory.
You can build a Benchmarker instance with theXmlSolverBenchmarker.
Configure it with a benchmarker configuration xml file:
XmlSolverBenchmarker benchmarker = new XmlSolverBenchmarker();
benchmarker.configure("/org/drools/planner/examples/nqueens/benchmark/nqueensSolverBenchmarkConfig.xml");
benchmarker.benchmark();
benchmarker.writeResults(resultFile);
A basic benchmarker configuration file looks something like this:
<?xml version="1.0" encoding="UTF-8"?>
<solverBenchmarkSuite>
<benchmarkDirectory>local/data/nqueens</benchmarkDirectory>
<solverStatisticType>BEST_SOLUTION_CHANGED</solverStatisticType>
<warmUpSecondsSpend>30</warmUpSecondsSpend>
<inheritedSolverBenchmark>
<unsolvedSolutionFile>data/nqueens/unsolved/unsolvedNQueens32.xml</unsolvedSolutionFile>
<unsolvedSolutionFile>data/nqueens/unsolved/unsolvedNQueens64.xml</unsolvedSolutionFile>
<solver>
<solutionClass>org.drools.planner.examples.nqueens.domain.NQueens</solutionClass>
<planningEntityClass>org.drools.planner.examples.nqueens.domain.Queen</planningEntityClass>
<scoreDrl>/org/drools/planner/examples/nqueens/solver/nQueensScoreRules.drl</scoreDrl>
<scoreDefinition>
<scoreDefinitionType>SIMPLE</scoreDefinitionType>
</scoreDefinition>
<termination>
<maximumSecondsSpend>20</maximumSecondsSpend>
</termination>
<constructionHeuristic>
<constructionHeuristicType>FIRST_FIT_DECREASING</constructionHeuristicType>
<constructionHeuristicPickEarlyType>FIRST_LAST_STEP_SCORE_EQUAL_OR_IMPROVING</constructionHeuristicPickEarlyType>
</constructionHeuristic>
</solver>
</inheritedSolverBenchmark>
<solverBenchmark>
<name>Solution tabu</name>
<solver>
<localSearch>
<selector>
<moveFactoryClass>org.drools.planner.examples.nqueens.solver.move.factory.RowChangeMoveFactory</moveFactoryClass>
</selector>
<acceptor>
<completeSolutionTabuSize>1000</completeSolutionTabuSize>
</acceptor>
<forager>
<pickEarlyType>NEVER</pickEarlyType>
</forager>
</localSearch>
</solver>
</solverBenchmark>
<solverBenchmark>
<name>Move tabu</name>
<solver>
<localSearch>
<selector>
<moveFactoryClass>org.drools.planner.examples.nqueens.solver.move.factory.RowChangeMoveFactory</moveFactoryClass>
</selector>
<acceptor>
<completeMoveTabuSize>5</completeMoveTabuSize>
</acceptor>
<forager>
<pickEarlyType>NEVER</pickEarlyType>
</forager>
</localSearch>
</solver>
</solverBenchmark>
<solverBenchmark>
<name>Property tabu</name>
<solver>
<localSearch>
<selector>
<moveFactoryClass>org.drools.planner.examples.nqueens.solver.move.factory.RowChangeMoveFactory</moveFactoryClass>
</selector>
<acceptor>
<completePropertyTabuSize>5</completePropertyTabuSize>
</acceptor>
<forager>
<pickEarlyType>NEVER</pickEarlyType>
</forager>
</localSearch>
</solver>
</solverBenchmark>
</solverBenchmarkSuite>
This benchmarker will try 3 configurations (1 solution tabu, 1 move tabu and 1 property tabu) on 2 data sets (32 and 64 queens), so it will run 6 solvers.
Every solverBenchmark entity contains a solver configuration (for example a local search
solver) and one or more unsolvedSolutionFile entities. It will run the solver configuration on
each of those unsolved solution files. A name is optional and generated if absent.
The common part of multiple solverBenchmark entities can be extracted to the
inheritedSolverBenchmark entity, but that can still be overwritten per
solverBenchmark entity. Note that inherited solver phases such as
<constructionHeuristic> or <localSearch> are not overwritten but
instead are added to the head of the solver phases list.
You need to specify a benchmarkDirectory (relative to the working directory). The best
solution of each solver run and a handy overview HTML webpage will be written in that directory.
Without a warmup, the results of the first (or first few) benchmarks are not reliable, because they will have lost CPU time on hotspot JIT compilation (and possibly DRL compilation too).
The avoid that distortion, the benchmarker can run some of the benchmarks for a specified amount of time, before running the real benchmarks. Generally, a warm up of 30 seconds suffices:
<solverBenchmarkSuite> ... <warmUpSecondsSpend>30</warmUpSecondsSpend> ... </solverBenchmarkSuite>
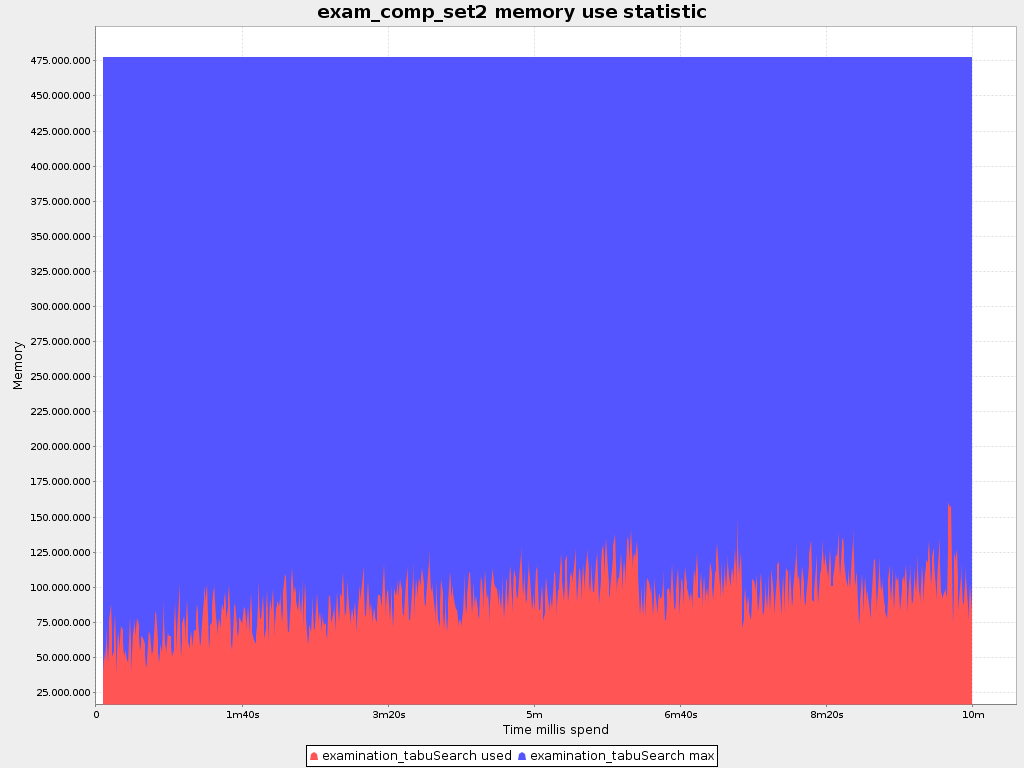
The benchmarker supports outputting statistics as graphs and CSV (comma separated values) files to the
benchmarkDirectory.
To configure graph and CSV output of a statistic, just add a solverStatisticType
line:
<solverBenchmarkSuite>
<benchmarkDirectory>local/data/nqueens/solved</benchmarkDirectory>
<solverStatisticType>BEST_SOLUTION_CHANGED</solverStatisticType>
...
</solverBenchmarkSuite>
Multiple solverStatisticType entries are allowed. Some statistic types might influence
performance noticeably. The following types are are supported:
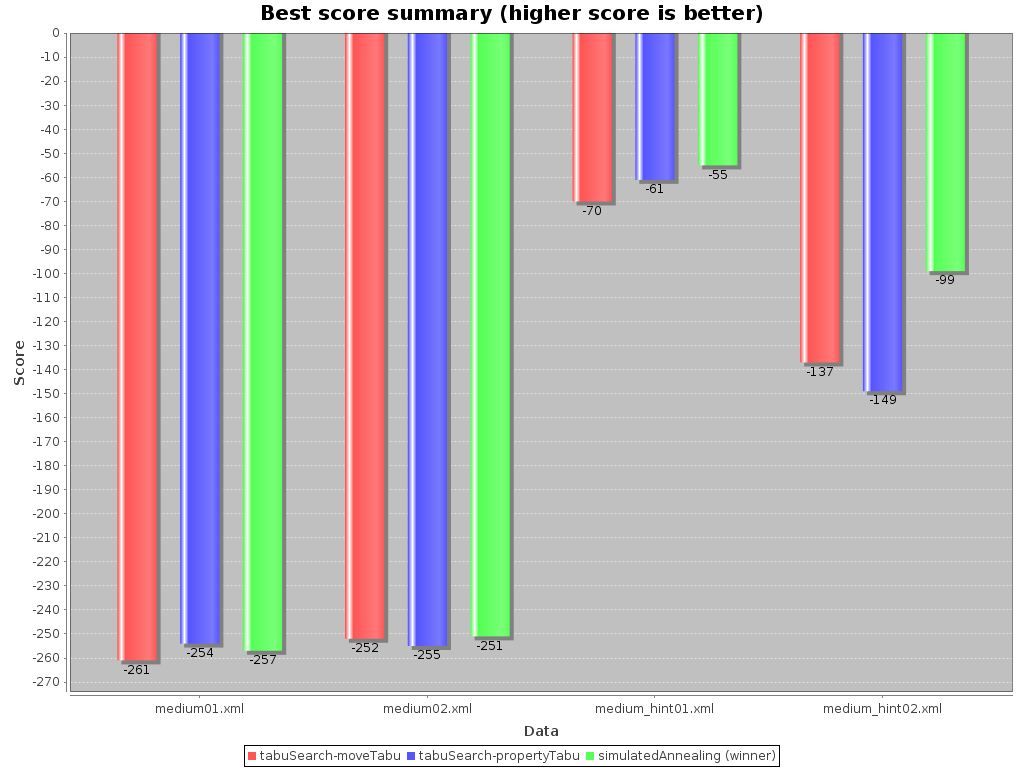
To see how the best score evolves over time, add BEST_SOLUTION_CHANGED as a
solverStatisticType.
Note
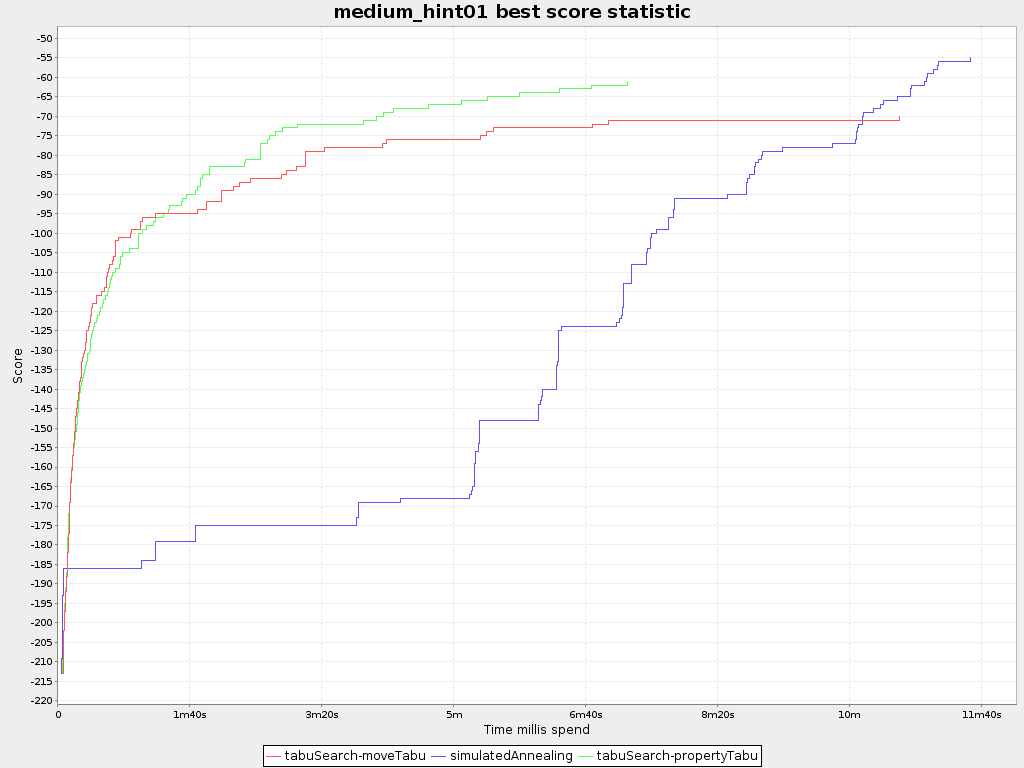
Don't be fooled by the simulated annealing line in this graph. If you give simulated annealing only 5 minutes, it might still be better than 5 minutes of tabu search. That's because this simulated annealing implementation automatically determines it's velocity based on the amount of time that can be spend. On the other hand, for the tabu search, what you see is what you'd get.
To see how fast the scores are calculated, add CALCULATE_COUNT_PER_SECOND as a
solverStatisticType.
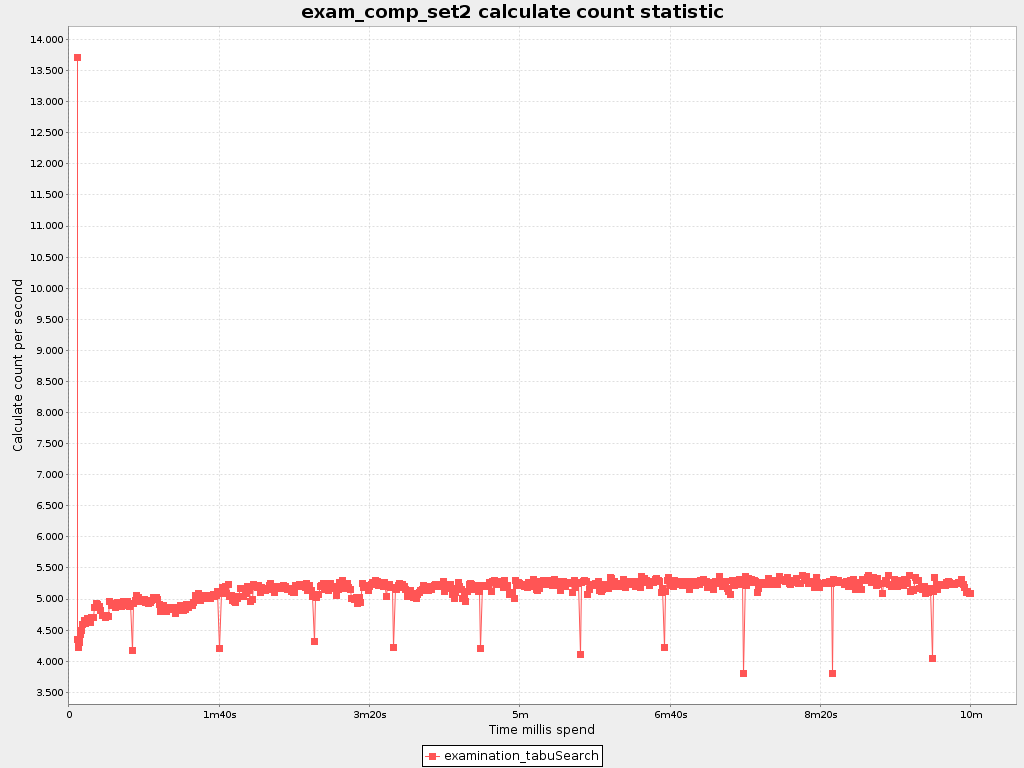
Note
The initial high calculate count is typical during solution initialization. In this example, it's far easier to calculate the score of a solution if only a handful exams have been added, in contrast to all of them. After those few seconds of initialization, the calculate count is relatively stable, apart from an occasional stop-the-world garbage collector disruption.