A Move is a change (or set of changes) from a solution A to a solution B. For example,
the move below changes queen C from row 0 to row
2:
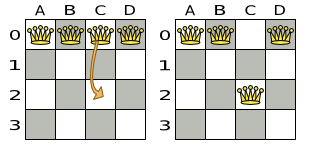
The new solution is called a neighbor of the original solution, because it can be
reached in a single Move. Although a single move can change multiple queens, the neighbors of a
solution should always be a very small subset of all possible solutions. For example, on that original solution,
these are all possible changeMove's:
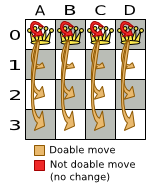
If we ignore the 4 changeMove's that have not impact and are therefore not doable, we can
see that number of moves is n * (n - 1) = 12. This is far less than the number of possible
solutions, which is n ^ n = 256. As the problem scales out, the number of possible moves
increases far less than the number of possible solutions.
Yet, in 4 changeMove's or less we can reach any solution. For example we can reach a very
different solution in 3 changeMove's:
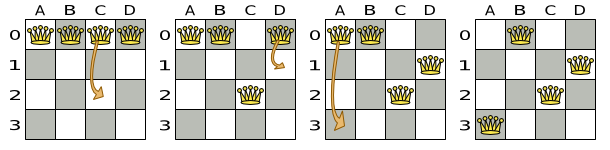
Note
There are many other types of moves besides changeMove's. Many move types are included
out-of-the-box, but you can also implement custom moves.
A Move can affect multiple entities or even create/delete entities. But it must not
change the problem facts.
All optimization algorithms use Move's to transition from one solution to a neighbor
solution. Therefor, all the optimization algorithms are confronted with Move selection: the
craft of creating and iterating moves efficiently and the art of finding the most promising subset of random moves
to evaluate first.
A MoveSelector's main function is to create Iterator<Move> when
needed. An optimization algorithm will iterate through a subset of those moves.
Here's an example how to configure a changeMoveSelector for the optimization algorithm
Local Search:
<localSearch>
<changeMoveSelector/>
...
</localSearch>
Out of the box, this works and all properties of the changeMoveSelector are defaulted
sensibly (unless that fails fast due to ambiguity). On the other hand, the configuration can be customized
significantly for specific use cases. For example: you want want to configure a filter to discard pointless
moves.
To create a Move, we need to select 1 or more planning entities and/or planning values to
move. Just like MoveSelectors, EntitySelectors and
ValueSelectors need to support a similar feature set (such as scalable just-in-time selection).
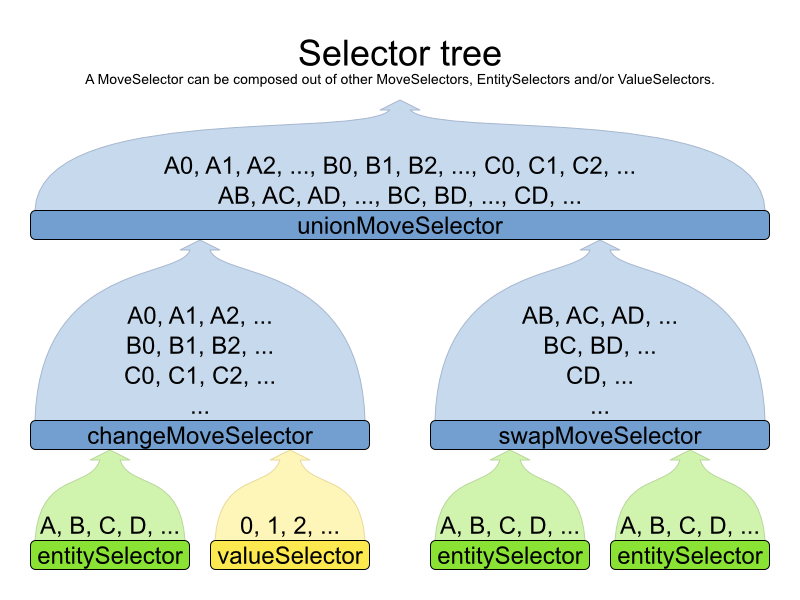
Therefor, they implement a common interface Selector and they are configured similarly.
A MoveSelector is often composed out of EntitySelectors,
ValueSelectors or even other MoveSelectors, which can be configured
individually if desired:
<unionMoveSelector>
<changeMoveSelector>
<entitySelector>
...
</entitySelector>
<valueSelector>
...
</valueSelector>
...
</changeMoveSelector>
...
</unionMoveSelector>
Together, this structure forms a Selector tree:
The root of this tree is a MoveSelector which is injected into the optimization algorithm
implementation to be (partially) iterated in every step.
A Selector's cacheType determines when a selection (such as a
Move, an entity, a value, ...) is created and how long it lives.
Almost every Selector supports setting a cacheType:
<changeMoveSelector>
<cacheType>PHASE</cacheType>
...
</changeMoveSelector>
The following cacheTypes are supported:
JUST_IN_TIME(default): Not cached. Construct each selection (Move, ...) just before it's used. This scales up well in memory footprint.STEP: Cached. Create each selection (Move, ...) at the beginning of a step and cache them in a list for the remainder of the step. This scales up badly in memory footprint.PHASE: Cached. Create each selection (Move, ...) at the beginning of aSolverPhaseand cache them in a list for the remainder of theSolverPhase. Some selections cannot be phase cached because the list changes every step. This scales up badly in memory footprint, but has a slight performance gain.SOLVER: Cached. Create each selection (Move, ...) at the beginning of aSolverand cache them in a list for the remainder of theSolver. Some selections cannot be solver cached because the list changes every step. This scales up badly in memory footprint, but has a slight performance gain.
A cacheType can be set on composite selectors too:
<unionMoveSelector>
<cacheType>PHASE</cacheType>
<changeMoveSelector/>
<swapMoveSelector/>
...
</unionMoveSelector>
Nested selectors of a cached selector cannot be configured to be cached themselves, unless it's a higher
cacheType. For example: a STEP cached unionMoveSelector
can hold a PHASE cached changeMoveSelector, but not a
STEP cached changeMoveSelector.
A Selector's selectionOrder determines the order in which the
selections (such as Moves, entities, values, ...) are iterated. An optimization algorithm will
usually only iterate through a subset of its MoveSelector's selections, starting from the
start, so the selectionOrder is critical to decide which Moves are actually
evaluated.
Almost every Selector supports setting a selectionOrder:
<changeMoveSelector>
...
<selectionOrder>RANDOM</selectionOrder>
...
</changeMoveSelector>
The following selectionOrders are supported:
ORIGINAL: Select the selections (Moves, entities, values, ...) in default order. Each selection will be selected only once.For example: A0, A1, A2, A3, ..., B0, B1, B2, B3, ..., C0, C1, C2, C3, ...
SORTED: Select the selections (
Moves, entities, values, ...) in sorted order. Each selection will be selected only once. RequirescacheType >= STEP. Mostly used on anentitySelectororvalueSelectorfor construction heuristics. See sorted selection.For example: A0, B0, C0, ..., A2, B2, C2, ..., A1, B1, C1, ...
RANDOM (default): Select the selections (
Moves, entities, values, ...) in non-shuffled random order. A selection might be selected multiple times. This scales up well in performance because it does not require caching.For example: C2, A3, B1, C2, A0, C0, ...
SHUFFLED: Select the selections (
Moves, entities, values, ...) in shuffled random order. Each selection will be selected only once. RequirescacheType >= STEP. This scales up badly in performance, not just because it requires caching, but also because a random number is generated for each element, even if it's not selected (which is the grand majority when scaling up).For example: C2, A3, B1, A0, C0, ...
PROBABILISTIC: Select the selections (
Moves, entities, values, ...) in random order, based on the selection probability of each element. A selection with a higher probability has a higher chance to be selected than elements with a lower probability. A selection might be selected multiple times. RequirescacheType >= STEP. Mostly used on anentitySelectororvalueSelector. See probabilistic selection.For example: B1, B1, A1, B2, B1, C2, B1, B1, ...
A selectionOrder can be set on composite selectors too.
Note
When a Selector is cached, all of its nested Selectors will
naturally default to selectionOrder ORIGINAL. Avoid overwriting the
selectionOrder of those nested Selectors.
This combination is great for big use cases (10 000 entities or more), as it scales up well in memory
footprint and performance. Other combinations are often not even viable on such sizes. It works for smaller use
cases too, so it's a good way to start out. It's the default, so this explicit configuration of
cacheType and selectionOrder is actually obsolete:
<unionMoveSelector>
<cacheType>JUST_IN_TIME</cacheType>
<selectionOrder>RANDOM</selectionOrder>
<changeMoveSelector/>
<swapMoveSelector/>
</unionMoveSelector>
Here's how it works. When Iterator<Move>.next() is called, a child
MoveSelector is randomly selected (1), which creates a random Move is
created (2, 3, 4) and is then returned (5):
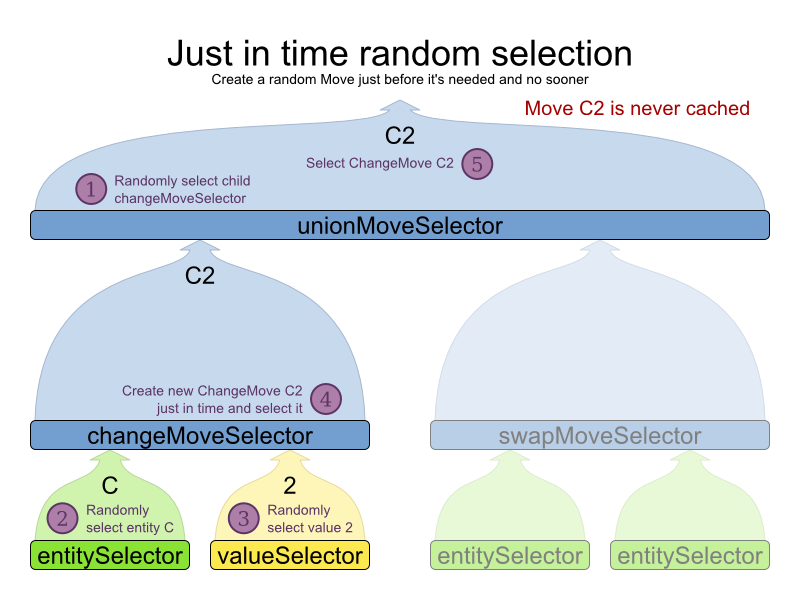
Notice that it never creates a list of Moves and it
generates random numbers only for Moves that are actually selected.
This combination often wins for small and medium use cases (5000 entities or less). Beyond that size, it scales up badly in memory footprint and performance.
<unionMoveSelector>
<cacheType>PHASE</cacheType>
<selectionOrder>SHUFFLED</selectionOrder>
<changeMoveSelector/>
<swapMoveSelector/>
</unionMoveSelector>
Here's how it works: At the start of the phase (or step depending on the cacheType),
all moves are created (1) and cached (2). When MoveSelector.iterator() is called, the moves
are shuffled (3). When Iterator<Move>.next() is called, the next element in the
shuffled list is returned (4):
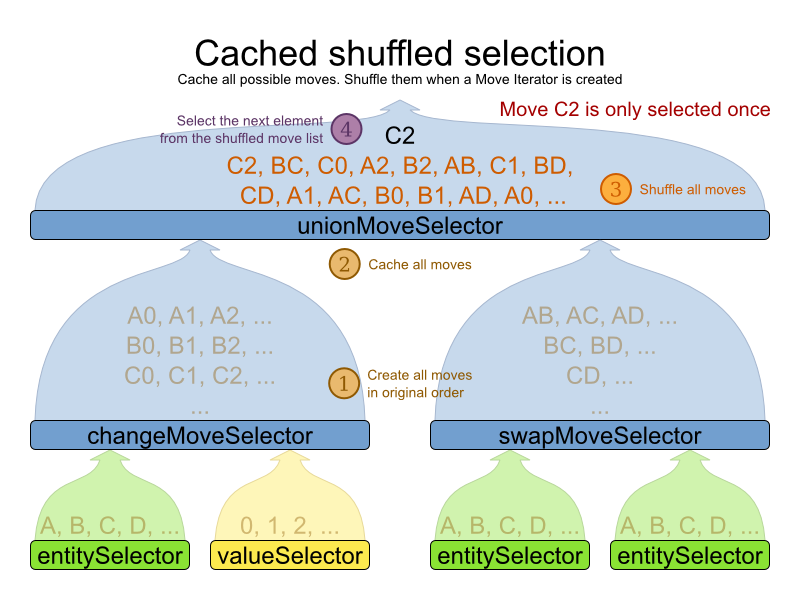
Notice that each Move will only be selected once, even
though they are selected in random order.
Use cacheType PHASE if none of the (possibly nested) Selectors require STEP. Otherwise,
do something like this:
<unionMoveSelector>
<cacheType>STEP</cacheType>
<selectionOrder>SHUFFLED</selectionOrder>
<changeMoveSelector>
<cacheType>PHASE</cacheType>
</changeMoveSelector>
<swapMoveSelector/>
<cacheType>PHASE</cacheType>
</swapMoveSelector>
<pillarSwapMoveSelector/><!-- Does not support cacheType PHASE -->
</unionMoveSelector>
This combination is often a worthy competitor for medium use cases, especially with fast stepping optimization algorithms (such as simulated annealing). Unlike cached shuffled selection, it doesn't waste time shuffling the move list at the beginning of every step.
<unionMoveSelector>
<cacheType>PHASE</cacheType>
<selectionOrder>RANDOM</selectionOrder>
<changeMoveSelector/>
<swapMoveSelector/>
</unionMoveSelector>
There are certain moves that you don't want to select, because:
The move is pointless and would only waste CPU time. For example, swapping 2 lectures of the same course will result in the same score and the same schedule because all lectures of 1 course are interchangeable (same teacher, same students, same topic).
Doing the move would break a build-in hard constraint, so the solution would be infeasible but the score function doesn't check build-in hard constraints (for performance gain). For example, don't change a gym lecture to a room which is not a gym room.
Note that any build-in hard constraint must usually be filtered on every move type. For example, don't swap the room of a gym lecture with another lecture if the other lecture's original room isn't a gym room.
Filtered selection can happen on any Selector in the selector tree, including any
MoveSelector, EntitySelector or ValueSelector. It works
with any kind of cacheType and selectionOrder.
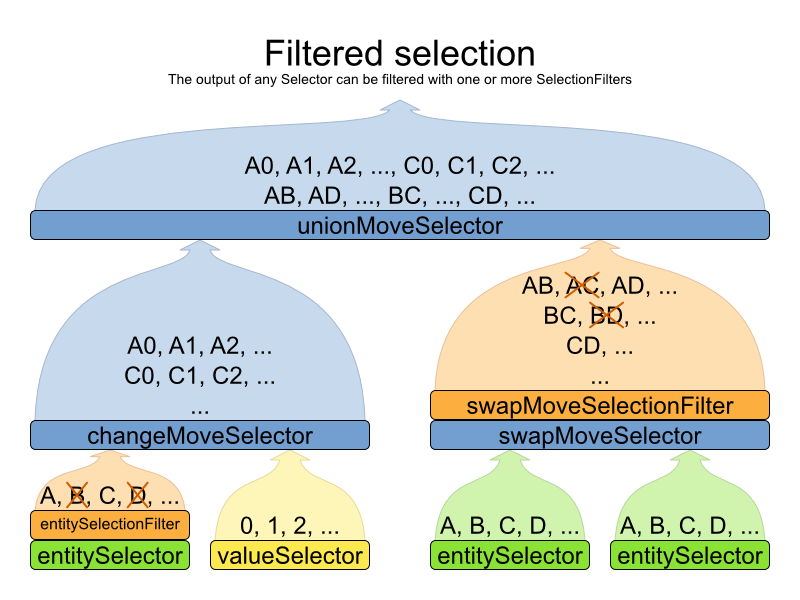
Filtering uses the interface SelectionFilter:
public interface SelectionFilter<T> {
boolean accept(ScoreDirector scoreDirector, T selection);
}
Implement the method accept to return false on a discarded
selection. Unaccepted moves will not be selected and will therefore never have their method
doMove called.
public class DifferentCourseSwapMoveFilter implements SelectionFilter<SwapMove> {
public boolean accept(ScoreDirector scoreDirector, SwapMove move) {
Lecture leftLecture = (Lecture) move.getLeftEntity();
Lecture rightLecture = (Lecture) move.getRightEntity();
return !leftLecture.getCourse().equals(rightLecture.getCourse());
}
}
Apply the filter on the lowest level possible. In most cases, you 'll need to know both the entity and the
value involved and you'll have to apply a filterClass on the
moveSelector:
<swapMoveSelector>
<filterClass>org.optaplanner.examples.curriculumcourse.solver.move.DifferentCourseSwapMoveFilter</filterClass>
</swapMoveSelector>
But if possible, apply it on a lower levels, such as a filterClass on the
entitySelector or valueSelector:
<changeMoveSelector>
<entitySelector>
<filterClass>...EntityFilter</filterClass>
</entitySelector>
</changeMoveSelector>
You can configure multiple filterClass elements on a single selector.
Sorted selection can happen on any Selector in the selector tree, including any
MoveSelector, EntitySelector or ValueSelector. It does
not work with cacheType JUST_IN_TIME and it only works with
selectionOrder SORTED.
It's mostly used in construction heuristics.
The easiest way to sort a Selector is with a plain old
Comparator:
public class CloudProcessDifficultyComparator implements Comparator<CloudProcess> {
public int compare(CloudProcess a, CloudProcess b) {
return new CompareToBuilder()
.append(a.getRequiredMultiplicand(), b.getRequiredMultiplicand())
.append(a.getId(), b.getId())
.toComparison();
}
}
You 'll also need to configure it (unless it's annotated applied for this optimization algorithm):
<entitySelector>
<cacheType>PHASE</cacheType>
<selectionOrder>SORTED</selectionOrder>
<sorterComparatorClass>...CloudProcessDifficultyComparator</sorterComparatorClass>
<sorterOrder>DESCENDING</sorterOrder>
</entitySelector>
If you need the entire Solution to sort a Selector, use a
SelectionSorterWeightFactory instead:
public interface SelectionSorterWeightFactory<Sol extends Solution, T> {
Comparable createSorterWeight(Sol solution, T selection);
}
public class QueenDifficultyWeightFactory implements SelectionSorterWeightFactory<NQueens, Queen> {
public Comparable createSorterWeight(NQueens nQueens, Queen queen) {
int distanceFromMiddle = calculateDistanceFromMiddle(nQueens.getN(), queen.getColumnIndex());
return new QueenDifficultyWeight(queen, distanceFromMiddle);
}
// ...
public static class QueenDifficultyWeight implements Comparable<QueenDifficultyWeight> {
private final Queen queen;
private final int distanceFromMiddle;
public QueenDifficultyWeight(Queen queen, int distanceFromMiddle) {
this.queen = queen;
this.distanceFromMiddle = distanceFromMiddle;
}
public int compareTo(QueenDifficultyWeight other) {
return new CompareToBuilder()
// The more difficult queens have a lower distance to the middle
.append(other.distanceFromMiddle, distanceFromMiddle) // Decreasing
// Tie breaker
.append(queen.getColumnIndex(), other.queen.getColumnIndex())
.toComparison();
}
}
}
You 'll also need to configure it (unless it's annotated and automatically applied for this optimization algorithm):
<entitySelector>
<cacheType>PHASE</cacheType>
<selectionOrder>SORTED</selectionOrder>
<sorterWeightFactoryClass>...QueenDifficultyWeightFactory</sorterWeightFactoryClass>
<sorterOrder>DESCENDING</sorterOrder>
</entitySelector>
Alternatively, you can also use the interface SelectionSorter directly:
public interface SelectionSorter<T> {
void sort(ScoreDirector scoreDirector, List<T> selectionList);
}
<entitySelector>
<cacheType>PHASE</cacheType>
<selectionOrder>SORTED</selectionOrder>
<sorterClass>...MyEntitySorter</sorterClass>
</entitySelector>
Probabilistic selection can happen on any Selector in the selector tree, including any
MoveSelector, EntitySelector or ValueSelector. It does
not work with cacheType JUST_IN_TIME and it only works with
selectionOrder PROBABILISTIC.
Each selection has a probabilityWeight, which determines the chance that's that selection
will be selected:
public interface SelectionProbabilityWeightFactory<T> {
double createProbabilityWeight(ScoreDirector scoreDirector, T selection);
}
<entitySelector>
<cacheType>PHASE</cacheType>
<selectionOrder>PROBABILISTIC</selectionOrder>
<probabilityWeightFactoryClass>...MyEntityProbabilityWeightFactoryClass</probabilityWeightFactoryClass>
</entitySelector>
For example, if there are 3 entities: process A (probabilityWeight 2.0), process B (probabilityWeight 0.5) and process C (probabilityWeight 0.5), then process A will be selected 4 times more than B and C.
For 1 planning variable, the ChangeMove selects 1 planning entity and 1 planning value
and assigns the entity's variable to that value.
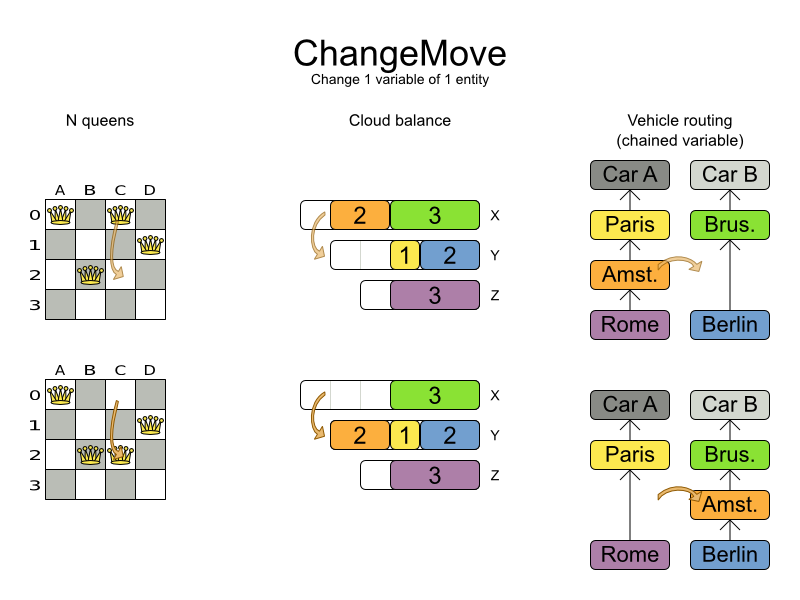
Simplest configuration:
<changeMoveSelector/>
Advanced configuration:
<changeMoveSelector>
... <!-- Normal selector properties -->
<entitySelector>
<entityClass>...Lecture</entityClass>
...
</entitySelector>
<valueSelector>
<variableName>room</variableName>
...
</valueSelector>
</changeMoveSelector>
A ChangeMove is the finest grained move.
Important
Almost every moveSelector configuration injected into a metaheuristic algorithm should
include a changeMoveSelector or a custom implementation. This guarantees that every possible
Solution can be reached through applying a number of moves in sequence (not taking score traps into account). Of course, normally it is unioned with other, more course
grained move selectors.
The SwapMove selects 2 different planning entities and swaps the planning values of all
their planning variables.
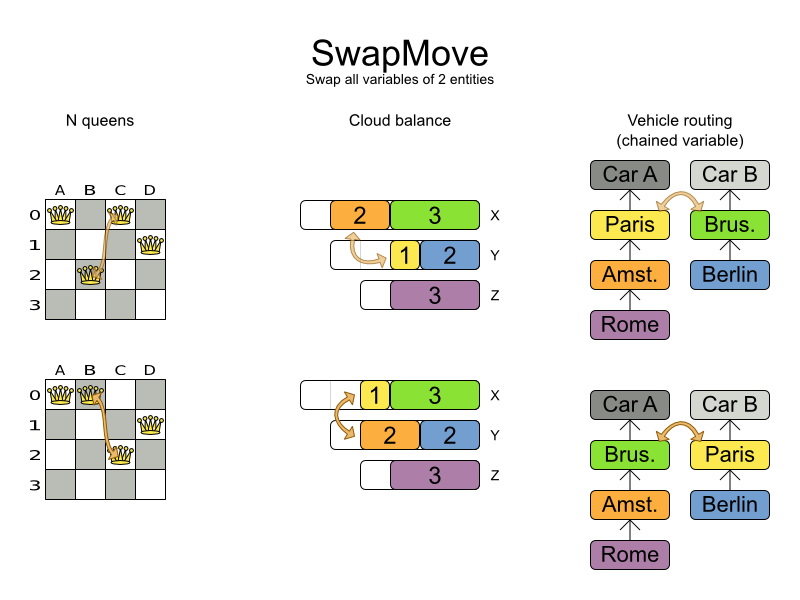
Although a SwapMove on a single variable is essentially just 2
ChangeMoves, it's often the winning step where the first of the 2
ChangeMoves would not be the winning step because it leave the solution in a state with broken
hard constraints. For example: swapping the room of 2 lectures doesn't bring the solution in a intermediate state
where both lectures are in the same room which breaks a hard constraint.
Simplest configuration:
<swapMoveSelector/>
Advanced configuration:
<swapMoveSelector>
... <!-- Normal selector properties -->
<entitySelector>
<entityClass>...Lecture</entityClass>
...
</entitySelector>
<secondaryEntitySelector>
...
</secondaryEntitySelector>
<variableNameInclude>room</variableNameInclude>
<variableNameInclude>...</variableNameInclude>
</swapMoveSelector>
The secondaryEntitySelector is rarely needed: if it is not specified, entities from the
same entitySelector are swapped.
If one or more variableNameInclude properties are specified, not all planning variables
will be swapped, but only those specified. For example for course scheduling, specifying only
variableNameInclude room will make it only swap room, not period.
A pillar is a set of planning entities which have the same planning value(s) for each
of their planning variables. The pillarSwapMove selects 2 different entity pillars and swaps
the values of all their variables for all their entities.
Simplest configuration:
<pillarSwapMoveSelector/>
Advanced configuration:
<pillarSwapMoveSelector>
... <!-- Normal selector properties -->
<pillarSelector>
<entitySelector>
<entityClass>...Lecture</entityClass>
...
</entitySelector>
</pillarSelector>
<secondaryPillarSelector>
<entitySelector>
...
</entitySelector>
</secondaryPillarSelector>
<variableNameInclude>room</variableNameInclude>
<variableNameInclude>...</variableNameInclude>
</pillarSwapMoveSelector>
The secondaryPillarSelector is rarely needed: if it is not specified, entities from the
same pillarSelector are swapped.
The other properties are explained in swapMoveSelector.
A subChain is a set of planning entities with a chained planning variable which form
part of a chain. The subChainChangeMove selects a subChain and moves it to another place in a
different or the same anchor chain.
Simplest configuration:
<subChainChangeMoveSelector/>
Advanced configuration:
<subChainChangeMoveSelector>
... <!-- Normal selector properties -->
<subChainSelector>
<entitySelector>
<entityClass>...VrpCustomer</entityClass>
...
</entitySelector>
<minimumSubChainSize>2</minimumSubChainSize>
<maximumSubChainSize>40</maximumSubChainSize>
</subChainSelector>
<valueSelector>
<variableName>previousStandstill</variableName>
...
</valueSelector>
<selectReversingMoveToo>true</selectReversingMoveToo>
</subChainChangeMoveSelector>
The subChainSelector selects a number of entities, no less than
minimumSubChainSize (defaults to 2) and no more than maximumSubChainSize
(defaults to infinity).
The property selectReversingMoveToo (defaults to true) enabled selecting the reverse of
every subchain too.
The subChainSwapMove selects 2 different subChains and moves it to another place in a
different or the same anchor chain.
Simplest configuration:
<subChainSwapMoveSelector/>
Advanced configuration:
<subChainSwapMoveSelector>
... <!-- Normal selector properties -->
<subChainSelector>
<entitySelector>
<entityClass>...VrpCustomer</entityClass>
...
</entitySelector>
<minimumSubChainSize>2</minimumSubChainSize>
<maximumSubChainSize>40</maximumSubChainSize>
</subChainSelector>
<secondarySubChainSelector>
<entitySelector>
<entityClass>...VrpCustomer</entityClass>
...
</entitySelector>
<minimumSubChainSize>2</minimumSubChainSize>
<maximumSubChainSize>40</maximumSubChainSize>
</secondarySubChainSelector>
<selectReversingMoveToo>true</selectReversingMoveToo>
</subChainSwapMoveSelector>
The secondarySubChainSelector is rarely needed: if it is not specified, entities from the
same subChainSelector are swapped.
The other properties are explained in subChainChangeMoveSelector.
A unionMoveSelector selects a Move by selecting 1 of its child
MoveSelectors to supply the next Move.
Simplest configuration:
<unionMoveSelector>
<...MoveSelector/>
<...MoveSelector/>
<...MoveSelector/>
...
</unionMoveSelector>
Advanced configuration:
<unionMoveSelector>
... <!-- Normal selector properties -->
<selectorProbabilityWeightFactoryClass>...ProbabilityWeightFactory</selectorProbabilityWeightFactoryClass>
<changeMoveSelector>
<fixedProbabilityWeight>...</fixedProbabilityWeight>
...
</changeMoveSelector>
<swapMoveSelector>
<fixedProbabilityWeight>...</fixedProbabilityWeight>
...
</swapMoveSelector>
<...MoveSelector>
<fixedProbabilityWeight>...</fixedProbabilityWeight>
...
</...MoveSelector>
...
</unionMoveSelector>
The selectorProbabilityWeightFactory determines in selectionOrder
RANDOM how often a child MoveSelector is selected to supply the next Move. By default, each
child MoveSelector has the same chance of being selected. Change the fixedProbabilityWeight of
such a child to select it more often. For example, the unionMoveSelector can return a
SwapMove twice as often as a ChangeMove:
<unionMoveSelector>
<changeMoveSelector>
<fixedProbabilityWeight>1.0</fixedProbabilityWeight>
...
</changeMoveSelector>
<swapMoveSelector>
<fixedProbabilityWeight>2.0</fixedProbabilityWeight>
...
</swapMoveSelector>
</unionMoveSelector>
The number of possible ChangeMoves is very different from the number of possible
SwapMoves and furthermore it's problem dependent. To give each individual
Move the same selection chance (as opposed to each MoveSelector), use the
FairSelectorProbabilityWeightFactory:
<unionMoveSelector>
<selectorProbabilityWeightFactoryClass>org.optaplanner.core.impl.heuristic.selector.common.decorator.FairSelectorProbabilityWeightFactory</selectorProbabilityWeightFactoryClass>
<changeMoveSelector/>
<swapMoveSelector/>
</unionMoveSelector>
A cartesianProductMoveSelector selects a new CompositeMove. It builds
that CompositeMove by selecting 1 Move per child
MoveSelector and adding it to the CompositeMove.
Simplest configuration:
<cartesianProductMoveSelector>
<...MoveSelector/>
<...MoveSelector/>
<...MoveSelector/>
...
</cartesianProductMoveSelector>
Advanced configuration:
<cartesianProductMoveSelector>
... <!-- Normal selector properties -->
<changeMoveSelector>
...
</changeMoveSelector>
<swapMoveSelector>
...
</swapMoveSelector>
<...MoveSelector>
...
</...MoveSelector>
...
</cartesianProductMoveSelector>
Simplest configuration:
<entitySelector/>
Advanced configuration:
<entitySelector>
... <!-- Normal selector properties -->
<entityClass>org.optaplanner.examples.curriculumcourse.domain.Lecture</entityClass>
</entitySelector>
The entityClass property is only required if it cannot be deduced automatically because
there are multiple entity classes.
Simplest configuration:
<valueSelector/>
Advanced configuration:
<valueSelector>
... <!-- Normal selector properties -->
<variableName>room</variableName>
</valueSelector>
The variableName property is only required if it cannot be deduced automatically because
there are multiple variables (for the related entity class).
To determine which move types might be missing in your implementation, run a benchmarker for a short amount of time and configure it to write the best solutions to disk. Take a look at such a best solution: it will likely be a local optima. Try to figure out if there's a move that could get out of that local optima faster.
If you find one, implement that course-grained move, mix it with the existing moves and benchmark it against the previous configurations to see if you want to keep it.
Instead of reusing the generic Moves (such as ChangeMove) you can also
implement your own Moves. Generic and custom MoveSelectors can be combined
as wanted.
A custom Move can be tailored to work to the advantage of your constraints. For example,
in examination scheduling, changing the period of an exam A also changes te period of all the exams that need to
coincide with exam A.
A custom Move is also slightly faster than a generic Move. However,
it's far more work to implement and much harder to avoid bugs. After implementing a custom
Move, make sure to turn on environmentMode FULL_ASSERT to
check for score corruptions.
Your custom moves must implement the Move interface:
public interface Move {
boolean isMoveDoable(ScoreDirector scoreDirector);
Move createUndoMove(ScoreDirector scoreDirector);
void doMove(ScoreDirector scoreDirector);
Collection<? extends Object> getPlanningEntities();
Collection<? extends Object> getPlanningValues();
}
Let's take a look at the Move implementation for 4 queens which moves a queen to a
different row:
public class RowChangeMove implements Move {
private Queen queen;
private Row toRow;
public RowChangeMove(Queen queen, Row toRow) {
this.queen = queen;
this.toRow = toRow;
}
// ... see below
}
An instance of RowChangeMove moves a queen from its current row to a different
row.
Planner calls the doMove(ScoreDirector) method to do a move. The Move
implementation must notify the ScoreDirector of any changes it make to planning entity's
variables:
public void doMove(ScoreDirector scoreDirector) {
scoreDirector.beforeVariableChanged(queen, "row"); // before changes are made to the queen.row
queen.setRow(toRow);
scoreDirector.afterVariableChanged(queen, "row"); // after changes are made to the queen.row
}
You need to call the methods scoreDirector.beforeVariableChanged(Object, String) and
scoreDirector.afterVariableChanged(Object, String) directly before and after modifying the
entity.
Note
You can alter multiple entities in a single move and effectively create a big move (also known as a coarse-grained move).
Warning
A Move can only change/add/remove planning entities, it must not change any of the
problem facts.
Planner automatically filters out non doable moves by calling the
isDoable(ScoreDirector) method on a move. A non doable move is:
A move that changes nothing on the current solution. For example, moving queen B0 to row 0 is not doable, because it is already there.
A move that is impossible to do on the current solution. For example, moving queen B0 to row 10 is not doable because it would move it outside the board limits.
In the n queens example, a move which moves the queen from its current row to the same row isn't doable:
public boolean isMoveDoable(ScoreDirector scoreDirector) {
return !ObjectUtils.equals(queen.getRow(), toRow);
}
Because we won't generate a move which can move a queen outside the board limits, we don't need to check it.
A move that is currently not doable could become doable on the working Solution of a later
step.
Each move has an undo move: a move (normally of the same type) which does the exact
opposite. In the example above the undo move of C0 to C2 would be the move C2 to
C0. An undo move is created from a Move, before the Move has been
done on the current solution.
public Move createUndoMove(ScoreDirector scoreDirector) {
return new RowChangeMove(queen, queen.getRow());
}
Notice that if C0 would have already been moved to C2, the undo move would create the move C2 to C2, instead of the move C2 to C0.
A solver phase might do and undo the same Move more than once. In fact, many solver
phases will iteratively do an undo a number of moves to evaluate them, before selecting one of those and doing
that move again (without undoing it this time).
A Move must implement the getPlanningEntities() and
getPlanningValues() methods. They are used by entity tabu and value tabu respectively. When
they are called, the Move has already been done.
public List<? extends Object> getPlanningEntities() {
return Collections.singletonList(queen);
}
public Collection<? extends Object> getPlanningValues() {
return Collections.singletonList(toRow);
}
If your Move changes multiple planning entities, return all of them in
getPlanningEntities() and return all their values (to which they are changing) in
getPlanningValues().
public Collection<? extends Object> getPlanningEntities() {
return Arrays.asList(leftCloudProcess, rightCloudProcess);
}
public Collection<? extends Object> getPlanningValues() {
return Arrays.asList(leftCloudProcess.getComputer(), rightCloudProcess.getComputer());
}
A Move must implement the equals() and hashCode()
methods. 2 moves which make the same change on a solution, should be equal.
public boolean equals(Object o) {
if (this == o) {
return true;
} else if (o instanceof RowChangeMove) {
RowChangeMove other = (RowChangeMove) o;
return new EqualsBuilder()
.append(queen, other.queen)
.append(toRow, other.toRow)
.isEquals();
} else {
return false;
}
}
public int hashCode() {
return new HashCodeBuilder()
.append(queen)
.append(toRow)
.toHashCode();
}
Notice that it checks if the other move is an instance of the same move type. This
instanceof check is important because a move will be compared to a move with another move type
if you're using more then 1 move type.
It's also recommended to implement the toString() method as it allows you to read
Planner's logging more easily:
public String toString() {
return queen + " => " + toRow;
}
Now that we can implement a single custom Move, let's take a look at generating such
custom moves.
The easiest way to generate custom moves is by implementing the interface
MoveListFactory:
public interface MoveListFactory {
List<Move> createMoveList(Solution solution);
}
For example:
public class RowChangeMoveFactory implements MoveListFactory {
public List<Move> createMoveList(Solution solution) {
NQueens nQueens = (NQueens) solution;
List<Move> moveList = new ArrayList<Move>();
for (Queen queen : nQueens.getQueenList()) {
for (Row toRow : nQueens.getRowList()) {
moveList.add(new RowChangeMove(queen, toRow));
}
}
return moveList;
}
}
Simple configuration (which can be nested in a unionMoveSelector just like any other
MoveSelector):
<moveListFactory>
<moveListFactoryClass>org.optaplanner.examples.nqueens.solver.move.factory.RowChangeMoveFactory</moveListFactoryClass>
</moveListFactory>
Advanced configuration:
<moveListFactory>
... <!-- Normal moveSelector properties -->
<moveListFactoryClass>org.optaplanner.examples.nqueens.solver.move.factory.RowChangeMoveFactory</moveListFactoryClass>
</moveListFactory>
Because the MoveListFactory generates all moves at once in a List<Move>, it does
not support cacheType JUST_IN_TIME. Therefore,
moveListFactory uses cacheType STEP by default and it
scales badly in memory footprint.
Use this advanced form to generate custom moves by implementing the interface
MoveIteratorFactory:
public interface MoveIteratorFactory {
long getSize(ScoreDirector scoreDirector);
Iterator<Move> createOriginalMoveIterator(ScoreDirector scoreDirector);
Iterator<Move> createRandomMoveIterator(ScoreDirector scoreDirector, Random workingRandom);
}
The method getSize() must give an estimation of the size. It doesn't need to be correct.
The method createOriginalMoveIterator is called if the selectionOrder is
ORIGINAL or if it is cached. The method createRandomMoveIterator is called
for selectionOrder RANDOM combined with cacheType
JUST_IN_TIME.
Important
Don't create a collection (list, array, map, set) of Moves when creating the
Iterator<Move>: the whole purpose of MoveIteratorFactory over
MoveListFactory is giving you the ability to create a Move just in time in
the Iterator's method next().
Simple configuration (which can be nested in a unionMoveSelector just like any other
MoveSelector):
<moveIteratorFactory>
<moveIteratorFactoryClass>...</moveIteratorFactoryClass>
</moveIteratorFactory>
Advanced configuration:
<moveIteratorFactory>
... <!-- Normal moveSelector properties -->
<moveIteratorFactoryClass>...</moveIteratorFactoryClass>
</moveIteratorFactory>