Suppose your company owns a number of cloud computers and needs to run a number of processes on those computers. Assign each process to a computer under the following 4 constraints.
Hard constraints which must be fulfilled:
Every computer must be able to handle the minimum hardware requirements of the sum of its processes:
The CPU power of a computer must be at least the sum of the CPU power required by the processes assigned to that computer.
The RAM memory of a computer must be at least the sum of the RAM memory required by the processes assigned to that computer.
The network bandwidth of a computer must be at least the sum of the network bandwidth required by the processes assigned to that computer.
Soft constraints which should be optimized:
Each computer that has one or more processes assigned, incurs a maintenance cost (which is fixed per computer).
Minimize the total maintenance cost.
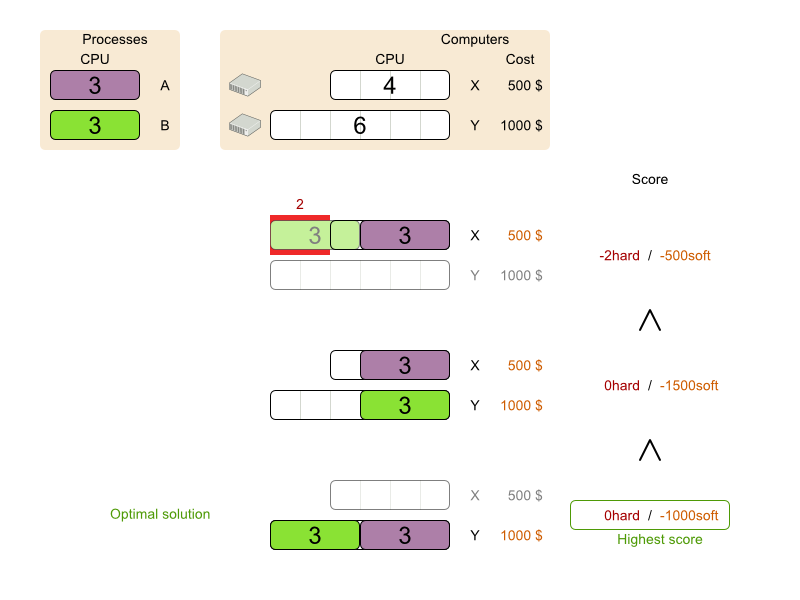
How would you do that? This problem is a form of bin packing. Here's a simplified example where we assign 4 processes to 2 computers with 2 constraints (CPU and RAM) with a simple algorithm:

The simple algorithm used here is the First Fit Decreasing algorithm, which assigns the bigger processes first and assigns the smaller processes to the remaining space. As you can see, it's not optimal, because it does not leave enough room to assign the yellow process D.
OptaPlanner does find the more optimal solution fast, by using additional, smarter algorithms. And it scales too: both in data (more processes, more computers) and constraints (more hardware requirements, other constraints). So let's take a look how we can use Planner for this.
2computers-6processes has 2 computers and 6 processes with a search space of 64. 3computers-9processes has 3 computers and 9 processes with a search space of 10^4. 4computers-012processes has 4 computers and 12 processes with a search space of 10^7. 100computers-300processes has 100 computers and 300 processes with a search space of 10^600. 200computers-600processes has 200 computers and 600 processes with a search space of 10^1380. 400computers-1200processes has 400 computers and 1200 processes with a search space of 10^3122. 800computers-2400processes has 800 computers and 2400 processes with a search space of 10^6967.
Let's start by taking a look at the domain model. It's pretty simple:
Computer: represents a computer with certain hardware (CPU power, RAM memory, network bandwidth) and maintenance cost.Process: represents a process with a demand. Needs to be assigned to aComputerby Planner.CloudBalance: represents a problem. Contains everyComputerandProcessfor a certain data set.

In the UML class diagram above, the Planner concepts are already annotated:
Planning entity: the class (or classes) that changes during planning. In this example that's the class
Process.Planning variable: the property (or properties) of a planning entity class that changes during planning. In this examples, that's the property
computeron the classProcess.Solution: the class that represents a data set and contains all planning entities. In this example that's the class
CloudBalance.
Try it yourself. Download and configure the examples in your
favorite IDE. Run org.optaplanner.examples.cloudbalancing.app.CloudBalancingHelloWorld.
By default, it is configured to run for 120 seconds. It will execute this code:
Example 2.1. CloudBalancingHelloWorld.java
public class CloudBalancingHelloWorld {
public static void main(String[] args) {
// Build the Solver
SolverFactory solverFactory = SolverFactory.createFromXmlResource(
"org/optaplanner/examples/cloudbalancing/solver/cloudBalancingSolverConfig.xml");
Solver solver = solverFactory.buildSolver();
// Load a problem with 400 computers and 1200 processes
CloudBalance unsolvedCloudBalance = new CloudBalancingGenerator().createCloudBalance(400, 1200);
// Solve the problem
solver.solve(unsolvedCloudBalance);
CloudBalance solvedCloudBalance = (CloudBalance) solver.getBestSolution();
// Display the result
System.out.println("\nSolved cloudBalance with 400 computers and 1200 processes:\n"
+ toDisplayString(solvedCloudBalance));
}
...
}
The code above does this:
Build the
Solverbased on a solver configuration (in this case an XML file from the classpath).SolverFactory solverFactory = SolverFactory.createFromXmlResource(
"org/optaplanner/examples/cloudbalancing/solver/cloudBalancingSolverConfig.xml");
Solver solver = solverFactory.buildSolver();Load the problem.
CloudBalancingGeneratorgenerates a random problem: you'll replace this with a class that loads a real problem, for example from a database.CloudBalance unsolvedCloudBalance = new CloudBalancingGenerator().createCloudBalance(400, 1200);
Solve the problem.
solver.solve(unsolvedCloudBalance);
CloudBalance solvedCloudBalance = (CloudBalance) solver.getBestSolution();Display the result.
System.out.println("\nSolved cloudBalance with 400 computers and 1200 processes:\n"
+ toDisplayString(solvedCloudBalance));
The only non-obvious part is building the Solver. Let's examine that.
Take a look at the solver configuration:
Example 2.2. cloudBalancingSolverConfig.xml
<?xml version="1.0" encoding="UTF-8"?>
<solver>
<!--<environmentMode>FAST_ASSERT</environmentMode>-->
<!-- Domain model configuration -->
<solutionClass>org.optaplanner.examples.cloudbalancing.domain.CloudBalance</solutionClass>
<entityClass>org.optaplanner.examples.cloudbalancing.domain.CloudProcess</entityClass>
<!-- Score configuration -->
<scoreDirectorFactory>
<scoreDefinitionType>HARD_SOFT</scoreDefinitionType>
<easyScoreCalculatorClass>org.optaplanner.examples.cloudbalancing.solver.score.CloudBalancingEasyScoreCalculator</easyScoreCalculatorClass>
<!--<scoreDrl>org/optaplanner/examples/cloudbalancing/solver/cloudBalancingScoreRules.drl</scoreDrl>-->
<initializingScoreTrend>ONLY_DOWN</initializingScoreTrend>
</scoreDirectorFactory>
<!-- Optimization algorithms configuration -->
<termination>
<secondsSpentLimit>120</secondsSpentLimit>
</termination>
<constructionHeuristic>
<constructionHeuristicType>FIRST_FIT_DECREASING</constructionHeuristicType>
</constructionHeuristic>
<localSearch>
<acceptor>
<entityTabuSize>7</entityTabuSize>
</acceptor>
<forager>
<acceptedCountLimit>1000</acceptedCountLimit>
</forager>
</localSearch>
</solver>
This solver configuration consists out of 3 parts:
Domain model configuration: What can Planner change? We need to make Planner aware of our domain classes:
<solutionClass>org.optaplanner.examples.cloudbalancing.domain.CloudBalance</solutionClass>
<entityClass>org.optaplanner.examples.cloudbalancing.domain.CloudProcess</entityClass>
Score configuration: How should Planner optimize the planning variables? Since we have hard and soft constraints, we use a
HardSoftScore. But we also need to tell Planner how to calculate such the score, depending on our business requirements. Further down, we 'll look into 2 alternatives to calculate the score: using a simple Java implementation or using Drools DRL.<scoreDirectorFactory>
<scoreDefinitionType>HARD_SOFT</scoreDefinitionType>
<easyScoreCalculatorClass>org.optaplanner.examples.cloudbalancing.solver.score.CloudBalancingEasyScoreCalculator</easyScoreCalculatorClass>
<!--<scoreDrl>org/optaplanner/examples/cloudbalancing/solver/cloudBalancingScoreRules.drl</scoreDrl>-->
<initializingScoreTrend>ONLY_DOWN</initializingScoreTrend>
</scoreDirectorFactory>
Optimization algorithms configuration: How should Planner optimize it? Don't worry about this for now: this is a good default configuration that works on most planning problems. It will already surpass human planners and most in-house implementations. Using the Planner benchmark toolkit, you can tweak it to get even better results.
<termination>
<secondsSpentLimit>120</secondsSpentLimit>
</termination>
<constructionHeuristic>
<constructionHeuristicType>FIRST_FIT_DECREASING</constructionHeuristicType>
</constructionHeuristic>
<localSearch>
<acceptor>
<entityTabuSize>7</entityTabuSize>
</acceptor>
<forager>
<acceptedCountLimit>1000</acceptedCountLimit>
</forager>
</localSearch>
Let's examine the domain model classes and the score configuration.
The class Computer is a POJO (Plain Old Java Object), nothing special. Usually, you'll
have more of these kind of classes.
Example 2.3. CloudComputer.java
public class CloudComputer ... {
private int cpuPower;
private int memory;
private int networkBandwidth;
private int cost;
... // getters
}
The class Process is a little bit special. We need to tell Planner that it can change
the field computer, so we annotate the class with @PlanningEntity and the
getter getComputer with @PlanningVariable:
Example 2.4. CloudProcess.java
@PlanningEntity(...)
public class CloudProcess ... {
private int requiredCpuPower;
private int requiredMemory;
private int requiredNetworkBandwidth;
private CloudComputer computer;
... // getters
@PlanningVariable(valueRangeProviderRefs = {"computerRange"})
public CloudComputer getComputer() {
return computer;
}
public void setComputer(CloudComputer computer) {
computer = computer;
}
// ************************************************************************
// Complex methods
// ************************************************************************
...
}
The values that Planner can choose from for the field computer, are retrieved from a
method on the Solution implementation: CloudBalance.getComputerList()
which returns a list of all computers in the current data set. We tell Planner about this by using the
valueRangeProviderRefs property.
The class CloudBalance implements the Solution interface. It holds
a list of all computers and processes. We need to tell Planner how to retrieve the collection of process which
it can change, so we need to annotate the getter getProcessList with
@PlanningEntityCollectionProperty.
The CloudBalance class also has a property score which is the
Score of that Solution instance in it's current state:
Example 2.5. CloudBalance.java
public class CloudBalance ... implements Solution<HardSoftScore> {
private List<CloudComputer> computerList;
private List<CloudProcess> processList;
private HardSoftScore score;
@ValueRangeProvider(id = "computerRange")
public List<CloudComputer> getComputerList() {
return computerList;
}
@PlanningEntityCollectionProperty
public List<CloudProcess> getProcessList() {
return processList;
}
...
public HardSoftScore getScore() {
return score;
}
public void setScore(HardSoftScore score) {
this.score = score;
}
// ************************************************************************
// Complex methods
// ************************************************************************
public Collection<? extends Object> getProblemFacts() {
List<Object> facts = new ArrayList<Object>();
facts.addAll(computerList);
// Do not add the planning entity's (processList) because that will be done automatically
return facts;
}
...
}
The method getProblemFacts() is only needed for score calculation with Drools. It's not
needed for the other score calculation types.
Planner will search for the Solution with the highest Score. We're
using a HardSoftScore, which means Planner will look for the solution with no hard constraints
broken (fulfill hardware requirements) and as little as possible soft constraints broken (minimize maintenance
cost).
Of course, Planner needs to be told about these domain-specific score constraints. There are several ways to implement such a score function:
Easy Java
Incremental Java
Drools
Let's take a look at 2 different implementations:
One way to define a score function is to implement the interface EasyScoreCalculator
in plain Java.
<scoreDirectorFactory>
<scoreDefinitionType>HARD_SOFT</scoreDefinitionType>
<easyScoreCalculatorClass>org.optaplanner.examples.cloudbalancing.solver.score.CloudBalancingEasyScoreCalculator</easyScoreCalculatorClass>
</scoreDirectorFactory>
Just implement the method calculateScore(Solution) to return a
HardSoftScore instance.
Example 2.6. CloudBalancingEasyScoreCalculator.java
public class CloudBalancingEasyScoreCalculator implements EasyScoreCalculator<CloudBalance> {
/**
* A very simple implementation. The double loop can easily be removed by using Maps as shown in
* {@link CloudBalancingMapBasedEasyScoreCalculator#calculateScore(CloudBalance)}.
*/
public HardSoftScore calculateScore(CloudBalance cloudBalance) {
int hardScore = 0;
int softScore = 0;
for (CloudComputer computer : cloudBalance.getComputerList()) {
int cpuPowerUsage = 0;
int memoryUsage = 0;
int networkBandwidthUsage = 0;
boolean used = false;
// Calculate usage
for (CloudProcess process : cloudBalance.getProcessList()) {
if (computer.equals(process.getComputer())) {
cpuPowerUsage += process.getRequiredCpuPower();
memoryUsage += process.getRequiredMemory();
networkBandwidthUsage += process.getRequiredNetworkBandwidth();
used = true;
}
}
// Hard constraints
int cpuPowerAvailable = computer.getCpuPower() - cpuPowerUsage;
if (cpuPowerAvailable < 0) {
hardScore += cpuPowerAvailable;
}
int memoryAvailable = computer.getMemory() - memoryUsage;
if (memoryAvailable < 0) {
hardScore += memoryAvailable;
}
int networkBandwidthAvailable = computer.getNetworkBandwidth() - networkBandwidthUsage;
if (networkBandwidthAvailable < 0) {
hardScore += networkBandwidthAvailable;
}
// Soft constraints
if (used) {
softScore -= computer.getCost();
}
}
return HardSoftScore.valueOf(hardScore, softScore);
}
}
Even if we optimize the code above to use Maps to iterate through the
processList only once, it is still slow because it doesn't
do incremental score calculation. To fix that, either use an incremental Java score function or a Drools score
function. Let's take a look at the latter.
To use the Drools rule engine as a score function, simply add a scoreDrl resource in
the classpath:
<scoreDirectorFactory>
<scoreDefinitionType>HARD_SOFT</scoreDefinitionType>
<scoreDrl>org/optaplanner/examples/cloudbalancing/solver/cloudBalancingScoreRules.drl</scoreDrl>
</scoreDirectorFactory>
First, we want to make sure that all computers have enough CPU, RAM and network bandwidth to support all their processes, so we make these hard constraints:
Example 2.7. cloudBalancingScoreRules.drl - hard constraints
...
import org.optaplanner.examples.cloudbalancing.domain.CloudBalance;
import org.optaplanner.examples.cloudbalancing.domain.CloudComputer;
import org.optaplanner.examples.cloudbalancing.domain.CloudProcess;
global HardSoftScoreHolder scoreHolder;
// ############################################################################
// Hard constraints
// ############################################################################
rule "requiredCpuPowerTotal"
when
$computer : CloudComputer($cpuPower : cpuPower)
$requiredCpuPowerTotal : Number(intValue > $cpuPower) from accumulate(
CloudProcess(
computer == $computer,
$requiredCpuPower : requiredCpuPower),
sum($requiredCpuPower)
)
then
scoreHolder.addHardConstraintMatch(kcontext, $cpuPower - $requiredCpuPowerTotal.intValue());
end
rule "requiredMemoryTotal"
...
end
rule "requiredNetworkBandwidthTotal"
...
endNext, if those constraints are met, we want to minimize the maintenance cost, so we add that as a soft constraint:
Example 2.8. cloudBalancingScoreRules.drl - soft constraints
// ############################################################################
// Soft constraints
// ############################################################################
rule "computerCost"
when
$computer : CloudComputer($cost : cost)
exists CloudProcess(computer == $computer)
then
scoreHolder.addSoftConstraintMatch(kcontext, - $cost);
endIf you use the Drools rule engine for score calculation, you can integrate with other Drools technologies, such as decision tables (XLS or web based), the KIE Workbench rule repository, ...
Now that this simple example works, try going further. Enrich the domain model and add extra constraints such as these:
Each
Processbelongs to aService. A computer can crash, so processes running the same service should be assigned to different computers.Each
Computeris located in aBuilding. A building can burn down, so processes of the same services should be assigned to computers in different buildings.