So where do we get started? There are so many use cases and so much functionality in a rule engine such as Drools that it becomes beguiling. Have no fear my intrepid adventurer, the complexity is layered and you can ease yourself in with simple use cases.
Stateless session, not utilising inference, forms the simplest use case. A stateless session can be called like a function passing it some data and then receiving some results back. Some common use cases for stateless sessions are, but not limited to:
Validation
Is this person eligible for a mortgage?
Calculation
Compute a mortgage premium.
Routing and Filtering
Filter incoming messages, such as emails, into folders.
Send incoming messages to a destination.
So let's start with a very simple example using a driving license application.
public class Applicant {
private String name;
private int age;
private boolean valid;
// getter and setter methods here
}
Now that we have our data model we can write our first rule. We assume that the application uses rules to reject invalid applications. As this is a simple validation use case we will add a single rule to disqualify any applicant younger than 18.
package com.company.license
rule "Is of valid age"
when
$a : Applicant( age < 18 )
then
$a.setValid( false );
endTo make the engine aware of data, so it can be processed against the
rules, we have to insert the data, much like with a
database. When the Applicant instance is inserted into the engine it is
evaluated against the constraints of the rules, in this case just two
constraints for one rule. We say two because the type
Applicant is the first object type constraint, and age <
18 is the second field constraint. An object type constraint plus
its zero or more field constraints is referred to as a pattern. When an
inserted instance satisfies both the object type constraint and all the
field constraints, it is said to be matched. The $a is a
binding variable which permits us to reference the matched object in the
consequence. There its properties can be updated. The dollar character
('$') is optional, but it helps to differentiate variable names from field
names. The process of matching patterns against the inserted data is, not
surprisingly, often referred to as pattern matching.
To use this rule it is necessary to put it a Drools file, just a plain
text file with .drl extension , short for "Drools Rule Language". Let's call
this file licenseApplication.drl, and store it in a Kie Project. A Kie Project
has the structure of a normal Maven project with an additional file (kmodule.xml)
defining the KieBases and KieSessions that can be created.
This file has to be placed in the resources/META-INF folder of the Maven project
while all the other Drools artifacts, such as the licenseApplication.drl
containing the former rule, must be stored in the resources folder or in any
other subfolder under it.
Since meaningful defaults have been provided for all configuration aspects, the simplest kmodule.xml file can contain just an empty kmodule tag like the following:
<?xml version="1.0" encoding="UTF-8"?>
<kmodule xmlns="http://jboss.org/kie/6.0.0/kmodule"/>
At this point it is possible to create a KieContainer that reads
the files to be built, from the classpath.
KieServices kieServices = KieServices.Factory.get();
KieContainer kContainer = kieServices.getKieClasspathContainer();
The above code snippet compiles all the DRL files found on the classpath
and put the result of this compilation, a KieModule, in the KieContainer.
If there are no errors, we are now ready to create our session from the KieContainer
and execute against some data:
StatelessKieSession kSession = kContainer.newStatelessKieSession();
Applicant applicant = new Applicant( "Mr John Smith", 16 );
assertTrue( applicant.isValid() );
ksession.execute( applicant );
assertFalse( applicant.isValid() );
The preceding code executes the data against the rules. Since the applicant is under the age of 18, the application is marked as invalid.
So far we've only used a single instance, but what if we want to use
more than one? We can execute against any object implementing Iterable,
such as a collection. Let's add another class called
Application, which has the date of the application, and we'll
also move the boolean valid field to the Application
class.
public class Applicant {
private String name;
private int age;
// getter and setter methods here
}
public class Application {
private Date dateApplied;
private boolean valid;
// getter and setter methods here
}
We will also add another rule to validate that the application was made within a period of time.
package com.company.license
rule "Is of valid age"
when
Applicant( age < 18 )
$a : Application()
then
$a.setValid( false );
end
rule "Application was made this year"
when
$a : Application( dateApplied > "01-jan-2009" )
then
$a.setValid( false );
end
Unfortunately a Java element does not implement the
Iterable interface, so we have to use the JDK converter
method Arrays.asList(...). The code shown below executes
against an iterable list, where all collection elements are inserted
before any matched rules are fired.
StatelessKieSession kSession = kContainer.newStatelessKieSession();
Applicant applicant = new Applicant( "Mr John Smith", 16 );
Application application = new Application();
assertTrue( application.isValid() );
ksession.execute( Arrays.asList( new Object[] { application, applicant } ) );
assertFalse( application.isValid() );
The two execute methods execute(Object object) and
execute(Iterable objects) are actually convenience methods
for the interface BatchExecutor's method
execute(Command command).
The KieCommands commands factory, obtainable from the KieServices
like all other factories of the KIE API, is used to create commands, so that
the following is equivalent to execute(Iterable it):
ksession.execute( kieServices.getCommands().newInsertElements( Arrays.asList( new Object[] { application, applicant } ) );
Batch Executor and Command Factory are particularly useful when working with multiple Commands and with output identifiers for obtaining results.
KieCommands kieCommands = kieServices.getCommands();
List<Command> cmds = new ArrayList<Command>();
cmds.add( kieCommands.newInsert( new Person( "Mr John Smith" ), "mrSmith", true, null ) );
cmds.add( kieCommands.newInsert( new Person( "Mr John Doe" ), "mrDoe", true, null ) );
BatchExecutionResults results = ksession.execute( kieCommands.newBatchExecution( cmds ) );
assertEquals( new Person( "Mr John Smith" ), results.getValue( "mrSmith" ) );
CommandFactory supports many other Commands that can be
used in the BatchExecutor like StartProcess,
Query, and SetGlobal.
Stateful Sessions are long lived and allow iterative changes over time. Some common use cases for Stateful Sessions are, but not limited to:
Monitoring
Stock market monitoring and analysis for semi-automatic buying.
Diagnostics
Fault finding, medical diagnostics
Logistics
Parcel tracking and delivery provisioning
Compliance
Validation of legality for market trades.
In contrast to a Stateless Session, the dispose()
method must be called afterwards to ensure there are no memory leaks, as
the KieBase contains references to Stateful Knowledge Sessions when
they are created. Since Stateful Knowledge Session is the most commonly used session type
it is just named KieSession in the KIE API. KieSession also
supports the BatchExecutor interface, like
StatelessKieSession, the only difference being that the
FireAllRules command is not automatically called at the end
for a Stateful Session.
We illustrate the monitoring use case with an example for raising a
fire alarm. Using just four classes, we represent rooms in a house, each
of which has one sprinkler. If a fire starts in a room, we represent that
with a single Fire instance.
public class Room {
private String name
// getter and setter methods here
}
public class Sprinkler {
private Room room;
private boolean on;
// getter and setter methods here
}
public class Fire {
private Room room;
// getter and setter methods here
}
public class Alarm {
}
In the previous section on Stateless Sessions the concepts of inserting and matching against data were introduced. That example assumed that only a single instance of each object type was ever inserted and thus only used literal constraints. However, a house has many rooms, so rules must express relationships between objects, such as a sprinkler being in a certain room. This is best done by using a binding variable as a constraint in a pattern. This "join" process results in what is called cross products, which are covered in the next section.
When a fire occurs an instance of the Fire class is
created, for that room, and inserted into the session. The rule uses a
binding on the room field of the Fire object to
constrain matching to the sprinkler for that room, which is currently off.
When this rule fires and the consequence is executed the sprinkler is
turned on.
rule "When there is a fire turn on the sprinkler"
when
Fire($room : room)
$sprinkler : Sprinkler( room == $room, on == false )
then
modify( $sprinkler ) { setOn( true ) };
System.out.println( "Turn on the sprinkler for room " + $room.getName() );
endWhereas the Stateless Session uses standard Java syntax to modify a
field, in the above rule we use the modify statement,
which acts as a sort of "with" statement. It may contain a series of comma
separated Java expressions, i.e., calls to setters of the object selected
by the modify statement's control expression. This
modifies the data, and makes the engine aware of those changes so it can
reason over them once more. This process is called inference, and it's
essential for the working of a Stateful Session. Stateless Sessions
typically do not use inference, so the engine does not need to be aware of
changes to data. Inference can also be turned off explicitly by using the
sequential mode.
So far we have rules that tell us when matching data exists, but
what about when it does not exist? How do we
determine that a fire has been extinguished, i.e., that there isn't a
Fire object any more? Previously the constraints have been
sentences according to Propositional Logic, where the engine is
constraining against individual instances. Drools also has support for
First Order Logic that allows you to look at sets of data. A pattern under
the keyword not matches when something does not exist.
The rule given below turns the sprinkler off as soon as the fire in that
room has disappeared.
rule "When the fire is gone turn off the sprinkler"
when
$room : Room( )
$sprinkler : Sprinkler( room == $room, on == true )
not Fire( room == $room )
then
modify( $sprinkler ) { setOn( false ) };
System.out.println( "Turn off the sprinkler for room " + $room.getName() );
endWhile there is one sprinkler per room, there is just a single alarm
for the building. An Alarm object is created when a fire
occurs, but only one Alarm is needed for the entire building,
no matter how many fires occur. Previously not was
introduced to match the absence of a fact; now we use its complement
exists which matches for one or more instances of some
category.
rule "Raise the alarm when we have one or more fires"
when
exists Fire()
then
insert( new Alarm() );
System.out.println( "Raise the alarm" );
endLikewise, when there are no fires we want to remove the alarm, so
the not keyword can be used again.
rule "Cancel the alarm when all the fires have gone"
when
not Fire()
$alarm : Alarm()
then
delete( $alarm );
System.out.println( "Cancel the alarm" );
end
Finally there is a general health status message that is printed when the application first starts and after the alarm is removed and all sprinklers have been turned off.
rule "Status output when things are ok"
when
not Alarm()
not Sprinkler( on == true )
then
System.out.println( "Everything is ok" );
endAs we did in the Stateless Session example, the above rules should be placed
in a single DRL file and saved into the resouces folder of your Maven project
or any of its subfolder. As before, we can then obtain a KieSession from
the KieContainer. The only difference is that this time we
create a Stateful Session, whereas before we created a Stateless Session.
KieServices kieServices = KieServices.Factory.get();
KieContainer kContainer = kieServices.getKieClasspathContainer();
KieSession ksession = kContainer.newKieSession();
With the session created it is now possible to iteratively work with
it over time. Four Room objects are created and inserted, as
well as one Sprinkler object for each room. At this point the
engine has done all of its matching, but no rules have fired yet. Calling
ksession.fireAllRules() allows the matched rules to fire, but
without a fire that will just produce the health message.
String[] names = new String[]{"kitchen", "bedroom", "office", "livingroom"};
Map<String,Room> name2room = new HashMap<String,Room>();
for( String name: names ){
Room room = new Room( name );
name2room.put( name, room );
ksession.insert( room );
Sprinkler sprinkler = new Sprinkler( room );
ksession.insert( sprinkler );
}
ksession.fireAllRules();
> Everything is ok
We now create two fires and insert them; this time a reference is
kept for the returned FactHandle. A Fact Handle is an
internal engine reference to the inserted instance and allows instances to
be retracted or modified at a later point in time. With the fires now in
the engine, once fireAllRules() is called, the alarm is
raised and the respective sprinklers are turned on.
Fire kitchenFire = new Fire( name2room.get( "kitchen" ) );
Fire officeFire = new Fire( name2room.get( "office" ) );
FactHandle kitchenFireHandle = ksession.insert( kitchenFire );
FactHandle officeFireHandle = ksession.insert( officeFire );
ksession.fireAllRules();
> Raise the alarm > Turn on the sprinkler for room kitchen > Turn on the sprinkler for room office
After a while the fires will be put out and the Fire
instances are retracted. This results in the sprinklers being turned off,
the alarm being cancelled, and eventually the health message is printed
again.
ksession.delete( kitchenFireHandle );
ksession.delete( officeFireHandle );
ksession.fireAllRules();
> Cancel the alarm > Turn off the sprinkler for room office > Turn off the sprinkler for room kitchen > Everything is ok
Everyone still with me? That wasn't so hard and already I'm hoping you can start to see the value and power of a declarative rule system.
People often confuse methods and rules, and new rule users often ask, "How do I call a rule?" After the last section, you are now feeling like a rule expert and the answer to that is obvious, but let's summarize the differences nonetheless.
public void helloWorld(Person person) {
if ( person.getName().equals( "Chuck" ) ) {
System.out.println( "Hello Chuck" );
}
}
Methods are called directly.
Specific instances are passed.
One call results in a single execution.
rule "Hello World" when
Person( name == "Chuck" )
then
System.out.println( "Hello Chuck" );
endRules execute by matching against any data as long it is inserted into the engine.
Rules can never be called directly.
Specific instances cannot be passed to a rule.
Depending on the matches, a rule may fire once or several times, or not at all.
Earlier the term "cross product" was mentioned, which is the result of a join. Imagine for a moment that the data from the fire alarm example were used in combination with the following rule where there are no field constraints:
rule "Show Sprinklers" when
$room : Room()
$sprinkler : Sprinkler()
then
System.out.println( "room:" + $room.getName() +
" sprinkler:" + $sprinkler.getRoom().getName() );
endIn SQL terms this would be like doing select * from Room,
Sprinkler and every row in the Room table would be joined with
every row in the Sprinkler table resulting in the following output:
room:office sprinkler:office room:office sprinkler:kitchen room:office sprinkler:livingroom room:office sprinkler:bedroom room:kitchen sprinkler:office room:kitchen sprinkler:kitchen room:kitchen sprinkler:livingroom room:kitchen sprinkler:bedroom room:livingroom sprinkler:office room:livingroom sprinkler:kitchen room:livingroom sprinkler:livingroom room:livingroom sprinkler:bedroom room:bedroom sprinkler:office room:bedroom sprinkler:kitchen room:bedroom sprinkler:livingroom room:bedroom sprinkler:bedroom
These cross products can obviously become huge, and they may very well contain spurious data. The size of cross products is often the source of performance problems for new rule authors. From this it can be seen that it's always desirable to constrain the cross products, which is done with the variable constraint.
rule
when
$room : Room()
$sprinkler : Sprinkler( room == $room )
then
System.out.println( "room:" + $room.getName() +
" sprinkler:" + $sprinkler.getRoom().getName() );
endThis results in just four rows of data, with the correct Sprinkler
for each Room. In SQL (actually HQL) the corresponding query would be
select * from Room, Sprinkler where Room ==
Sprinkler.room.
room:office sprinkler:office room:kitchen sprinkler:kitchen room:livingroom sprinkler:livingroom room:bedroom sprinkler:bedroom
The Agenda is a Rete feature. It maintains set of rules that are able to execute, its job is to schedule that execution in a deterministic order.
During actions on the RuleRuntime, rules may become fully matched and eligible for execution; a
single Rule Runtime Action can result in multiple eligible rules. When a rule is fully matched a Rule Match is
created, referencing the rule and the matched facts, and placed onto the Agenda. The Agenda controls the execution
order of these Matches using a Conflict Resolution strategy.
The engine cycles repeatedly through two phases:
Rule Runtime Actions. This is where most of the work takes place, either in the Consequence (the RHS itself) or the main Java application process. Once the Consequence has finished or the main Java application process calls
fireAllRules()the engine switches to the Agenda Evaluation phase.Agenda Evaluation. This attempts to select a rule to fire. If no rule is found it exits, otherwise it fires the found rule, switching the phase back to Rule Runtime Actions.
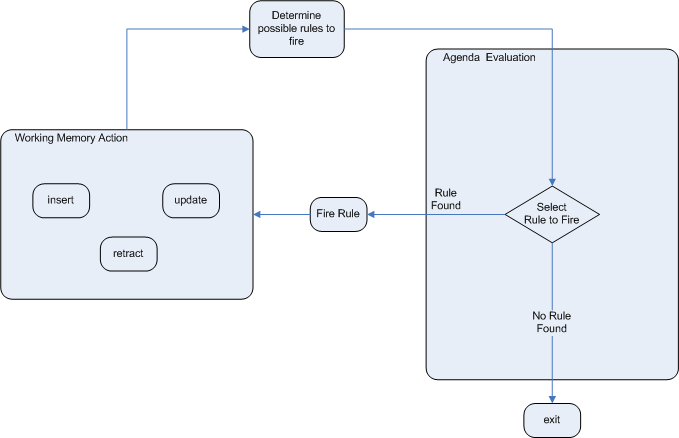
The process repeats until the agenda is clear, in which case control returns to the calling application. When Rule Runtime Actions are taking place, no rules are being fired.
So far the data and the matching process has been simple and small. To mix things up a bit a new example will be explored that handles cashflow calculations over date periods. The state of the engine will be illustratively shown at key stages to help get a better understanding of what is actually going on under the hood. Three classes will be used, as shown below. This will help us grow our understanding of pattern matching and joins further. We will then use this to illustate different techniques for execution control.
public class CashFlow {
private Date date;
private double amount;
private int type;
long accountNo;
// getter and setter methods here
}
public class Account {
private long accountNo;
private double balance;
// getter and setter methods here
}
public AccountPeriod {
private Date start;
private Date end;
// getter and setter methods here
}
By now you already know how to create KieBases and how to instantiate facts to populate the
KieSession, so tables will be used to show the state of the inserted data, as it makes things
clearer for illustration purposes. The tables below show that a single fact was inserted for the
Account. Also inserted are a series of debits and credits as CashFlow objects for
that account, extending over two quarters.
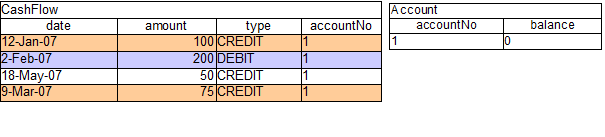
Two rules can be used to determine the debit and credit for that quarter and update the Account balance. The two rules below constrain the cashflows for an account for a given time period. Notice the "&&" which use short cut syntax to avoid repeating the field name twice.
rule "increase balance for credits"
when
ap : AccountPeriod()
acc : Account( $accountNo : accountNo )
CashFlow( type == CREDIT,
accountNo == $accountNo,
date >= ap.start && <= ap.end,
$amount : amount )
then
acc.balance += $amount;
end |
rule "decrease balance for debits"
when
ap : AccountPeriod()
acc : Account( $accountNo : accountNo )
CashFlow( type == DEBIT,
accountNo == $accountNo,
date >= ap.start && <= ap.end,
$amount : amount )
then
acc.balance -= $amount;
end |
Earlier we showed how rules would equate to SQL, which can often help people with an SQL background to understand rules. The two rules above can be represented with two views and a trigger for each view, as below:
select * from Account acc,
Cashflow cf,
AccountPeriod ap
where acc.accountNo == cf.accountNo and
cf.type == CREDIT and
cf.date >= ap.start and
cf.date <= ap.end
|
select * from Account acc,
Cashflow cf,
AccountPeriod ap
where acc.accountNo == cf.accountNo and
cf.type == DEBIT and
cf.date >= ap.start and
cf.date <= ap.end
|
trigger : acc.balance += cf.amount |
trigger : acc.balance -= cf.amount |
If the AccountPeriod is set to the first quarter we
constrain the rule "increase balance for credits" to fire on two rows of
data and "decrease balance for debits" to act on one row of data.

The two cashflow tables above represent the matched data for the two rules. The data is matched during the
insertion stage and, as you discovered in the previous chapter, does not fire straight away, but only after
fireAllRules() is called. Meanwhile, the rule plus its matched data is placed on the Agenda and
referred to as an RuIe Match or Rule Instance. The Agenda is a table of Rule Matches that are able to fire and
have their consequences executed, as soon as fireAllRules() is called. Rule Matches on the Agenda are referred
to as a conflict set and their execution is determine by a conflict resolution strategy.
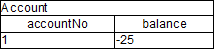
Notice that the order of execution so far is considered arbitrary.

After all of the above activations are fired, the account has a balance of -25.
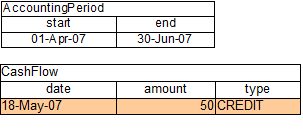
If the AccountPeriod is updated to the second quarter, we have just a single matched row of
data, and thus just a single Rule Match on the Agenda.
The firing of that Activation results in a balance of 25.

What if you don't want the order of rule execution to be arbitrary? When there is one or more Rule Match on the Agenda they are said to be in conflict, and a conflict resolution strategy is used to determine the order of execution. The Drools strategy is very simple and based around a salience value, which assigns a priority to a rule. Each rule has a default value of 0, the higher the value the higher the priority.
As a general rule, it is a good idea not to count on rules firing in any particular order, and to author the rules without worrying about a "flow". However when a flow is needed a number of possibilities exist beyond salience: agenda groups, rule flow groups, activation groups and control/semaphore facts.
As of Drools 6.0 rule definition order in the source file is used to set priority after salience.
To illustrate Salience we add a rule to print the account balance, where we want this rule to be executed after all the debits and credits have been applied for all accounts. We achieve this by assigning a negative salience to this rule so that it fires after all rules with the default salience 0.
rule "Print balance for AccountPeriod"
salience -50
when
ap : AccountPeriod()
acc : Account()
then
System.out.println( acc.accountNo + " : " + acc.balance );
end
|
The table below depicts the resulting Agenda. The three debit and credit rules are shown to be in arbitrary order, while the print rule is ranked last, to execute afterwards.

Agenda groups allow you to place rules into groups, and to place those groups onto a stack. The stack has push/pop bevaviour. Calling "setFocus" places the group onto the stack:
ksession.getAgenda().getAgendaGroup( "Group A" ).setFocus();
The agenda always evaluates the top of the stack. When all the rules have fired for a group, it is poped from the stack and the next group is evaluated.
rule "increase balance for credits"
agenda-group "calculation"
when
ap : AccountPeriod()
acc : Account( $accountNo : accountNo )
CashFlow( type == CREDIT,
accountNo == $accountNo,
date >= ap.start && <= ap.end,
$amount : amount )
then
acc.balance += $amount;
end
|
rule "Print balance for AccountPeriod"
agenda-group "report"
when
ap : AccountPeriod()
acc : Account()
then
System.out.println( acc.accountNo +
" : " + acc.balance );
end
|
First set the focus to the "report" group and then by placing the focus on "calculation" we ensure that group is evaluated first.
Agenda agenda = ksession.getAgenda();
agenda.getAgendaGroup( "report" ).setFocus();
agenda.getAgendaGroup( "calculation" ).setFocus();
ksession.fireAllRules();
Drools also features ruleflow-group attributes which allows workflow diagrams to declaratively specify when rules are allowed to fire. The screenshot below is taken from Eclipse using the Drools plugin. It has two ruleflow-group nodes which ensures that the calculation rules are executed before the reporting rules.

The use of the ruleflow-group attribute in a rule is shown below.
rule "increase balance for credits"
ruleflow-group "calculation"
when
ap : AccountPeriod()
acc : Account( $accountNo : accountNo )
CashFlow( type == CREDIT,
accountNo == $accountNo,
date >= ap.start && <= ap.end,
$amount : amount )
then
acc.balance += $amount;
end
|
rule "Print balance for AccountPeriod"
ruleflow-group "report"
when
ap : AccountPeriod()
acc : Account()
then
System.out.println( acc.accountNo +
" : " + acc.balance );
end
|
Warning
Declarative Agenda is experimental, and all aspects are highly likely to change in the future. @Eager and @Direct are temporary annotations to control the behaviour of rules, which will also change as Declarative Agenda evolves. Annotations instead of attributes where chosen, to reflect their experimental nature.
The declarative agenda allows to use rules to control which other rules can fire and when. While this will add a lot more overhead than the simple use of salience, the advantage is it is declarative and thus more readable and maintainable and should allow more use cases to be achieved in a simpler fashion.
This feature is off by default and must be explicitly enabled, that is because it is considered highly experimental for the moment and will be subject to change, but can be activated on a given KieBase by adding the declarativeAgenda='enabled' attribute in the corresponding kbase tag of the kmodule.xml file as in the following example.
Example 6.1. Enabling the Declarative Agenda
<kmodule xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://jboss.org/kie/6.0.0/kmodule">
<kbase name="DeclarativeKBase" declarativeAgenda="enabled">
<ksession name="KSession">
</kbase>
</kmodule>
The basic idea is:
All rule's Matches are inserted into WorkingMemory as facts. So you can now do pattern matching against a Match. The rule's metadata and declarations are available as fields on the Match object.
You can use the kcontext.blockMatch( Match match ) for the current rule to block the selected match. Only when that rule becomes false will the match be eligible for firing. If it is already eligible for firing and is later blocked, it will be removed from the agenda until it is unblocked.
A match may have multiple blockers and a count is kept. All blockers must became false for the counter to reach zero to enable the Match to be eligible for firing.
kcontext.unblockAllMatches( Match match ) is an over-ride rule that will remove all blockers regardless
An activation may also be cancelled, so it never fires with cancelMatch
An unblocked Match is added to the Agenda and obeys normal salience, agenda groups, ruleflow groups etc.
The @Direct annotations allows a rule to fire as soon as it's matched, this is to be used for rules that block/unblock matches, it is not desirable for these rules to have side effects that impact else where.
Example 6.2. New RuleContext methods
void blockMatch(Match match); void unblockAllMatches(Match match); void cancelMatch(Match match);
Here is a basic example that will block all matches from rules that have metadata @department('sales'). They will stay blocked until the blockerAllSalesRules rule becomes false, i.e. "go2" is retracted.
Example 6.3. Block rules based on rule metadata
rule rule1 @Eager @department('sales') when
$s : String( this == 'go1' )
then
list.add( kcontext.rule.name + ':' + $s );
end
rule rule2 @Eager @department('sales') when
$s : String( this == 'go1' )
then
list.add( kcontext.rule.name + ':' + $s );
end
rule blockerAllSalesRules @Direct @Eager when
$s : String( this == 'go2' )
$i : Match( department == 'sales' )
then
list.add( $i.rule.name + ':' + $s );
kcontext.blockMatch( $i );
endWarning
Further than annotate the blocking rule with @Direct, it is also necessary to annotate all the rules that could be potentially blocked by it with @Eager. This is because, since the Match has to be evaluated by the pattern matching of the blocking rule, the potentially blocked ones cannot be evaluated lazily, otherwise won't be any Match to be evaluated.
This example shows how you can use active property to count the number of active or inactive (already fired) matches.
Example 6.4. Count the number of active/inactive Matches
rule rule1 @Eager @department('sales') when
$s : String( this == 'go1' )
then
list.add( kcontext.rule.name + ':' + $s );
end
rule rule2 @Eager @department('sales') when
$s : String( this == 'go1' )
then
list.add( kcontext.rule.name + ':' + $s );
end
rule rule3 @Eager @department('sales') when
$s : String( this == 'go1' )
then
list.add( kcontext.rule.name + ':' + $s );
end
rule countActivateInActive @Direct @Eager when
$s : String( this == 'go2' )
$active : Number( this == 1 ) from accumulate( $a : Match( department == 'sales', active == true ), count( $a ) )
$inActive : Number( this == 2 ) from accumulate( $a : Match( department == 'sales', active == false ), count( $a ) )
then
kcontext.halt( );
end Inference has a bad name these days, as something not relevant to business use cases and just too complicated to be useful. It is true that contrived and complicated examples occur with inference, but that should not detract from the fact that simple and useful ones exist too. But more than this, correct use of inference can crate more agile and less error prone business rules, which are easier to maintain.
So what is inference? Something is inferred when we gain knowledge of something from using previous knowledge. For example, given a Person fact with an age field and a rule that provides age policy control, we can infer whether a Person is an adult or a child and act on this.
rule "Infer Adult" when $p : Person( age >= 18 ) then insert( new IsAdult( $p ) ) end
Due to the preceding rule, every Person who is 18 or over will have an instance of IsAdult inserted for them. This fact is special in that it is known as a relation. We can use this inferred relation in any rule:
$p : Person() IsAdult( person == $p )
So now we know what inference is, and have a basic example, how does this facilitate good rule design and maintenance?
Let's take a government department that are responsible for issuing ID cards when children become adults, henceforth referred to as ID department. They might have a decision table that includes logic like this, which says when an adult living in London is 18 or over, issue the card:

However the ID department does not set the policy on who an adult is. That's done at a central government level. If the central government were to change that age to 21, this would initiate a change management process. Someone would have to liaise with the ID department and make sure their systems are updated, in time for the law going live.
This change management process and communication between departments is not ideal for an agile environment, and change becomes costly and error prone. Also the card department is managing more information than it needs to be aware of with its "monolithic" approach to rules management which is "leaking" information better placed elsewhere. By this I mean that it doesn't care what explicit "age >= 18" information determines whether someone is an adult, only that they are an adult.
In contrast to this, let's pursue an approach where we split (de-couple) the authoring responsibilities, so that both the central government and the ID department maintain their own rules.
It's the central government's job to determine who is an adult. If they change the law they just update their central repository with the new rules, which others use:

The IsAdult fact, as discussed previously, is inferred from the policy rules. It encapsulates the seemingly arbitrary piece of logic "age >= 18" and provides semantic abstractions for its meaning. Now if anyone uses the above rules, they no longer need to be aware of explicit information that determines whether someone is an adult or not. They can just use the inferred fact:

While the example is very minimal and trivial it illustrates some important points. We started with a monolithic and leaky approach to our knowledge engineering. We created a single decision table that had all possible information in it and that leaks information from central government that the ID department did not care about and did not want to manage.
We first de-coupled the knowledge process so each department was responsible for only what it needed to know. We then encapsulated this leaky knowledge using an inferred fact IsAdult. The use of the term IsAdult also gave a semantic abstraction to the previously arbitrary logic "age >= 18".
So a general rule of thumb when doing your knowledge engineering is:
Bad
Monolithic
Leaky
Good
De-couple knowledge responsibilities
Encapsulate knowledge
Provide semantic abstractions for those encapsulations
After regular inserts you have to retract facts explicitly. With logical assertions, the fact that was asserted will be automatically retracted when the conditions that asserted it in the first place are no longer true. Actually, it's even cleverer then that, because it will be retracted only if there isn't any single condition that supports the logical assertion.
Normal insertions are said to be stated, i.e.,
just like the intuitive meaning of "stating a fact" implies. Using a
HashMap and a counter, we track how many times a particular
equality is stated; this means we count how many
different instances are equal.
When we logically insert an object during a RHS execution we are said to justify it, and it is considered to be justified by the firing rule. For each logical insertion there can only be one equal object, and each subsequent equal logical insertion increases the justification counter for this logical assertion. A justification is removed by the LHS of the creating rule becoming untrue, and the counter is decreased accordingly. As soon as we have no more justifications the logical object is automatically retracted.
If we try to logically insert an object when
there is an equal stated object, this will fail and
return null. If we state an object that has an
existing equal object that is justified we override
the Fact; how this override works depends on the configuration setting
WM_BEHAVIOR_PRESERVE. When the property is set to discard we
use the existing handle and replace the existing instance with the new
Object, which is the default behavior; otherwise we override it to
stated but we create an new
FactHandle.
This can be confusing on a first read, so hopefully the flow charts
below help. When it says that it returns a new FactHandle,
this also indicates the Object was propagated through the
network.
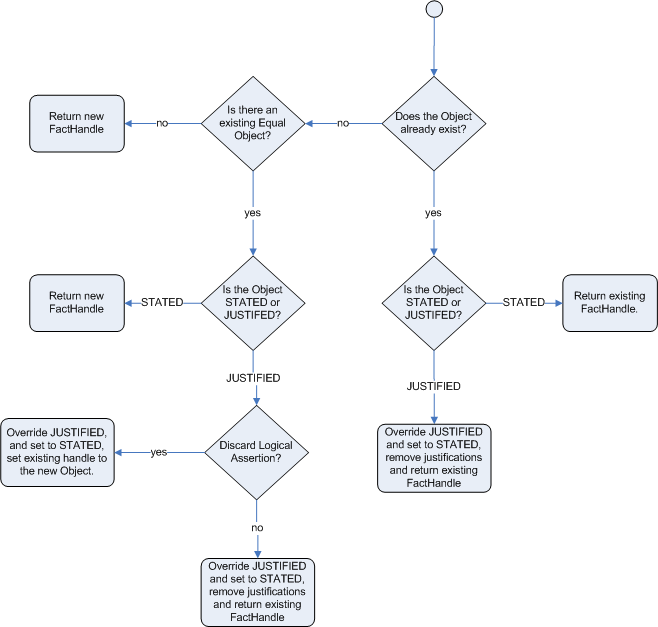
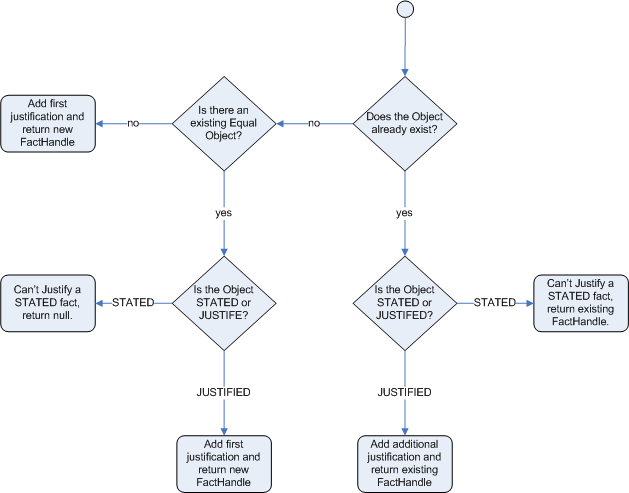
The previous example was issuing ID cards to over 18s, in this example we now issue bus passes, either a child or adult pass.
rule "Issue Child Bus Pass" when
$p : Person( age < 16 )
then
insert(new ChildBusPass( $p ) );
end
rule "Issue Adult Bus Pass" when
$p : Person( age >= 16 )
then
insert(new AdultBusPass( $p ) );
endAs before the above example is considered monolithic, leaky and providing poor separation of concerns.
As before we can provide a more robust application with a separation of concerns using inference. Notice this time we don't just insert the inferred object, we use "insertLogical":
rule "Infer Child" when
$p : Person( age < 16 )
then
insertLogical( new IsChild( $p ) )
end
rule "Infer Adult" when
$p : Person( age >= 16 )
then
insertLogical( new IsAdult( $p ) )
endA "insertLogical" is part of the Drools Truth Maintenance System (TMS). When a fact is logically inserted, this fact is dependant on the truth of the "when" clause. It means that when the rule becomes false the fact is automatically retracted. This works particularly well as the two rules are mutually exclusive. So in the above rules if the person is under 16 it inserts an IsChild fact, once the person is 16 or over the IsChild fact is automatically retracted and the IsAdult fact inserted.
Returning to the code to issue bus passes, these two rules can + logically insert the ChildBusPass and AdultBusPass facts, as the TMS + supports chaining of logical insertions for a cascading set of retracts.
rule "Issue Child Bus Pass" when
$p : Person( )
IsChild( person == $p )
then
insertLogical(new ChildBusPass( $p ) );
end
rule "Issue Adult Bus Pass" when
$p : Person( age >= 16 )
IsAdult( person =$p )
then
insertLogical(new AdultBusPass( $p ) );
endNow when a person changes from being 15 to 16, not only is the IsChild fact automatically retracted, so is the person's ChildBusPass fact. For bonus points we can combine this with the 'not' conditional element to handle notifications, in this situation, a request for the returning of the pass. So when the TMS automatically retracts the ChildBusPass object, this rule triggers and sends a request to the person:
rule "Return ChildBusPass Request "when
$p : Person( )
not( ChildBusPass( person == $p ) )
then
requestChildBusPass( $p );
endIt is important to note that for Truth Maintenance (and logical assertions) to work at all, your Fact objects (which may be JavaBeans) must override equals and hashCode methods (from java.lang.Object) correctly. As the truth maintenance system needs to know when two different physical objects are equal in value, both equals and hashCode must be overridden correctly, as per the Java standard.
Two objects are equal if and only if their equals methods return true for each other and if their hashCode methods return the same values. See the Java API for more details (but do keep in mind you MUST override both equals and hashCode).
TMS behaviour is not affected by theruntime configuration of Identity vs Equality, TMS is always equality.
Decision tables are a "precise yet compact" (ref. Wikipedia) way of representing conditional logic, and are well suited to business level rules.
Drools supports managing rules in a spreadsheet format. Supported formats are Excel (XLS), and CSV, which means that a variety of spreadsheet programs (such as Microsoft Excel, OpenOffice.org Calc amongst others) can be utilized. It is expected that web based decision table editors will be included in a near future release.
Decision tables are an old concept (in software terms) but have proven useful over the years. Very briefly speaking, in Drools decision tables are a way to generate rules driven from the data entered into a spreadsheet. All the usual features of a spreadsheet for data capture and manipulation can be taken advantage of.
Consider decision tables as a course of action if rules exist that can be expressed as rule templates and data: each row of a decision table provides data that is combined with a template to generate a rule.
Many businesses already use spreadsheets for managing data, calculations, etc. If you are happy to continue
this way, you can also manage your business rules this way. This also assumes you are happy to manage packages of
rules in .xls or .csv files. Decision tables are not recommended for rules
that do not follow a set of templates, or where there are a small number of rules (or if there is a dislike towards
software like Excel or OpenOffice.org). They are ideal in the sense that there can be control over what
parameters of rules can be edited, without exposing the rules directly.
Decision tables also provide a degree of insulation from the underlying object model.
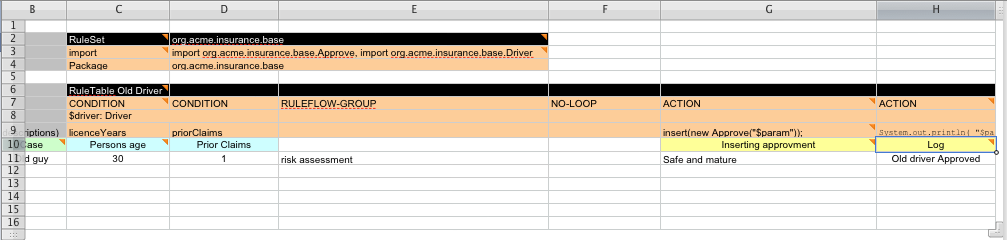
Here are some examples of real world decision tables (slightly edited to protect the innocent).
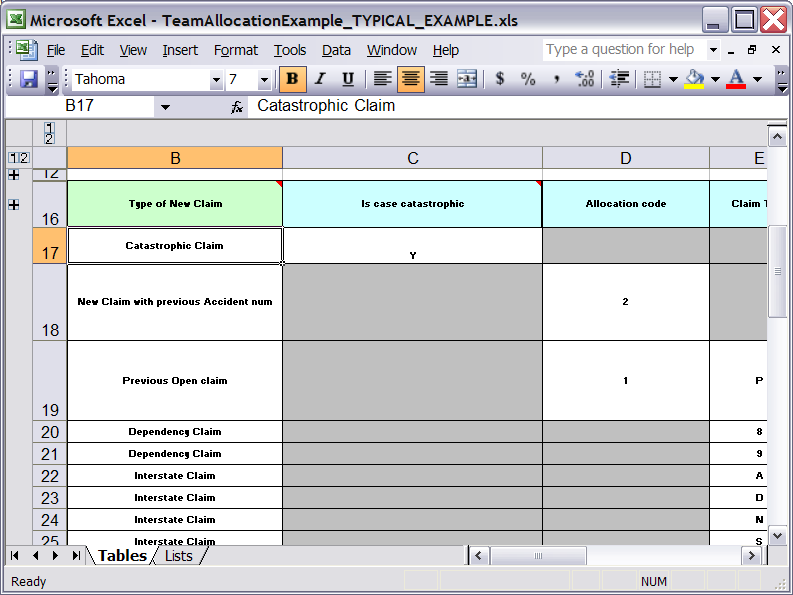
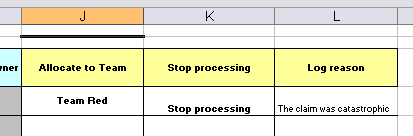
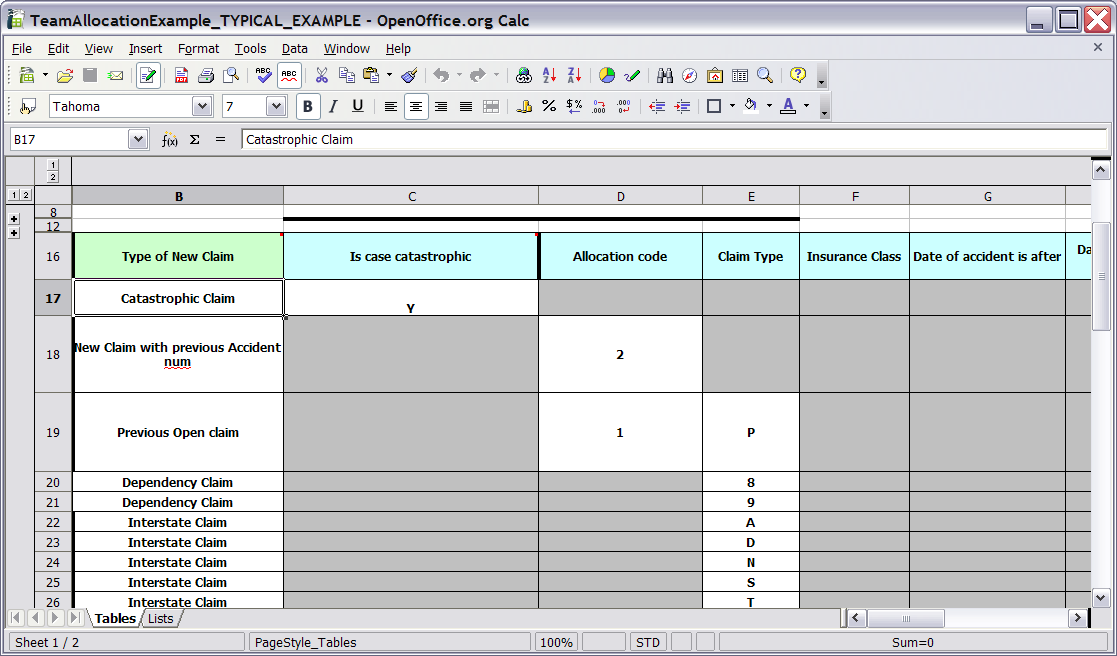
In the above examples, the technical aspects of the decision table have been collapsed away (using a standard spreadsheet feature).
The rules start from row 17, with each row resulting in a rule. The conditions are in columns C, D, E, etc., the actions being off-screen. The values in the cells are quite simple, and their meaning is indicated by the headers in Row 16. Column B is just a description. It is customary to use color to make it obvious what the different areas of the table mean.
Note
Note that although the decision tables look like they process top down, this is not necessarily the case. Ideally, rules are authored without regard for the order of rows, simply because this makes maintenance easier, as rows will not need to be shifted around all the time.
As each row is a rule, the same principles apply. As the rule engine processes the facts, any rules that match may fire. (Some people are confused by this. It is possible to clear the agenda when a rule fires and simulate a very simple decision table where only the first match effects an action.) Also note that you can have multiple tables on one spreadsheet. This way, rules can be grouped where they share common templates, yet at the end of the day they are all combined into one rule package. Decision tables are essentially a tool to generate DRL rules automatically.
The key point to keep in mind is that in a decision table each row is a rule, and each column in that row is either a condition or action for that rule.
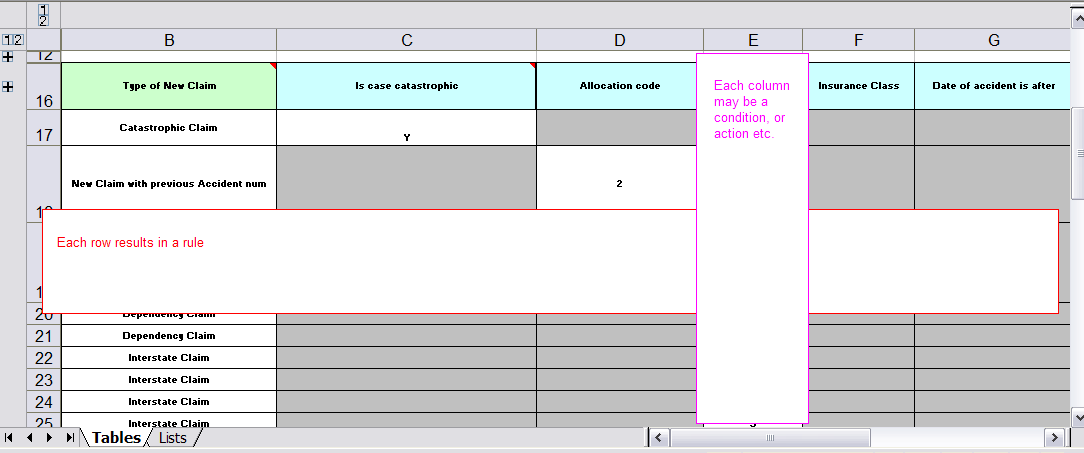
The spreadsheet looks for the RuleTable keyword to indicate the start of a rule table (both the starting row and column). Other keywords are also used to define other package level attributes (covered later). It is important to keep the keywords in one column. By convention the second column ("B") is used for this, but it can be any column (convention is to leave a margin on the left for notes). In the following diagram, C is actually the column where it starts. Everything to the left of this is ignored.
If we expand the hidden sections, it starts to make more sense how it works; note the keywords in column C.
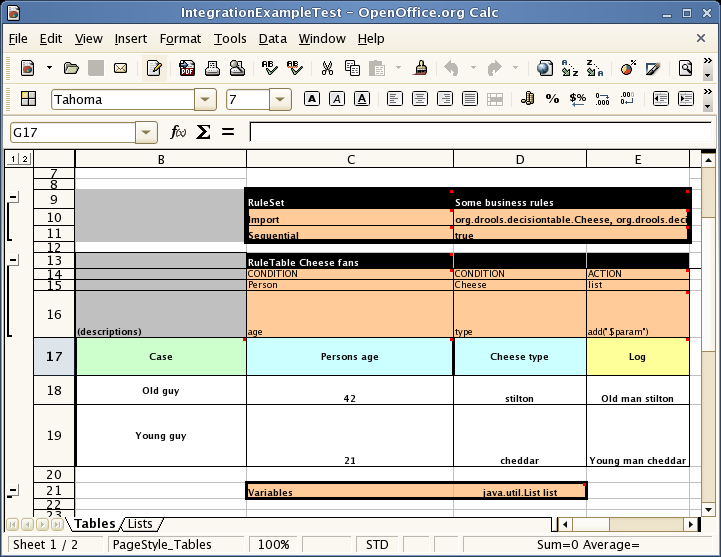
Now the hidden magic which makes it work can be seen. The RuleSet keyword indicates the name to be used in the rule package that will encompass all the rules. This name is optional, using a default, but it must have the RuleSet keyword in the cell immediately to the right.
The other keywords visible in Column C are Import and Sequential which will be covered later. The RuleTable keyword is important as it indicates that a chunk of rules will follow, based on some rule templates. After the RuleTable keyword there is a name, used to prefix the names of the generated rules. The sheet name and row numbers are appended to guarantee unique rule names.
Warning
The RuleTable name combined with the sheet name must be unique across all spreadsheet files in the same KieBase. If that's not the case, some rules might have the same name and only 1 of them will be applied. To show such ignored rules, raise the severity of such rule name conflicts.
The column of RuleTable indicates the column in which the rules start; columns to the left are ignored.
Note
In general the keywords make up name-value pairs.
Referring to row 14 (the row immediately after RuleTable), the keywords CONDITION and ACTION indicate that the data in the columns below are for either the LHS or the RHS parts of a rule. There are other attributes on the rule which can also be optionally set this way.
Row 15 contains declarations of ObjectTypes. The content in this
row is optional, but if this option is not in use, the row must be left blank; however this
option is usually found to be quite useful. When using this row, the values in the cells below
(row 16) become constraints on that object type. In the above case, it generates
Person(age=="42") and Cheese(type=="stilton"), where 42 and
"stilton" come from row 18. In the above example, the "==" is implicit; if just a field name
is given the translator assumes that it is to generate an exact match.
Note
An ObjectType declaration can span columns (via merged cells), meaning that all columns below the merged range are to be combined into one set of constraints within a single pattern matching a single fact at a time, as opposed to non-merged cells containing the same ObjectType, but resulting in different patterns, potentially matching different or identical facts.
Row 16 contains the rule templates themselves. They can use the "$param" placeholder to indicate where data from the cells below should be interpolated. (For multiple insertions, use "$1", "$2", etc., indicating parameters from a comma-separated list in a cell below.) Row 17 is ignored; it may contain textual descriptions of the column's purpose.
Rows 18 and 19 show data, which will be combined (interpolated) with the templates in row 15, to generate rules. If a cell contains no data, then its template is ignored. (This would mean that some condition or action does not apply for that rule row.) Rule rows are read until there is a blank row. Multiple RuleTables can exist in a sheet. Row 20 contains another keyword, and a value. The row positions of keywords like this do not matter (most people put them at the top) but their column should be the same one where the RuleTable or RuleSet keywords should appear. In our case column C has been chosen to be significant, but any other column could be used instead.
In the above example, rules would be rendered like the following (as it uses the "ObjectType" row):
//row 18
rule "Cheese_fans_18"
when
Person(age=="42")
Cheese(type=="stilton")
then
list.add("Old man stilton");
end
Note
The constraints age=="42" and type=="stilton" are interpreted
as single constraints, to be added to the respective ObjectType in the cell above. If the
cells above were spanned, then there could be multiple constraints on one "column".
Warning
Very large decision tables may have very large memory requirements.
There are two types of rectangular areas defining data that is used for generating a DRL file. One, marked
by a cell labelled RuleSet, defines all DRL items except rules. The other one may occur repeatedly
and is to the right and below a cell whose contents begin with RuleTable. These areas represent the
actual decision tables, each area resulting in a set of rules of similar structure.
A Rule Set area may contain cell pairs, one below the RuleSet cell and containing a keyword
designating the kind of value contained in the other one that follows in the same row.
The columns of a Rule Table area define patterns and constraints for the left hand sides of the rules
derived from it, actions for the consequences of the rules, and the values of individual rule attributes. Thus, a
Rule Table area should contain one or more columns, both for conditions and actions, and an arbitrary selection of
columns for rule attributes, at most one column for each of these. The first four rows following the row with the
cell marked with RuleTable are earmarked as header area, mostly used for the definition of code to
construct the rules. It is any additional row below these four header rows that spawns another rule, with its data
providing for variations in the code defined in the Rule Table header.
All keywords are case insensitive.
Only the first worksheet is examined for decision tables.
Entries in a Rule Set area may define DRL constructs (except rules), and specify rule attributes. While entries for constructs may be used repeatedly, each rule attribute may be given at most once, and it applies to all rules unless it is overruled by the same attribute being defined within the Rule Table area.
Entries must be given in a vertically stacked sequence of cell pairs. The first one contains a keyword and
the one to its right the value, as shown in the table below. This sequence of cell pairs may be interrupted by
blank rows or even a Rule Table, as long as the column marked by RuleSet is upheld as the one
containing the keyword.
Table 6.5. Entries in the Rule Set area
| Keyword | Value | Usage |
|---|---|---|
| RuleSet | The package name for the generated DRL file. Optional, the default is
rule_table. | Must be First entry. |
| Sequential | "true" or "false". If "true", then salience is used to ensure that rules fire from the top down. | Optional, at most once. If omitted, no firing order is imposed. |
| EscapeQuotes | "true" or "false". If "true", then quotation marks are escaped so that they appear literally in the DRL. | Optional, at most once. If omitted, quotation marks are escaped. |
| Import | A comma-separated list of Java classes to import. | Optional, may be used repeatedly. |
| Variables | Declarations of DRL globals, i.e., a type followed by a variable name. Multiple global definitions must be separated with a comma. | Optional, may be used repeatedly. |
| Functions | One or more function definitions, according to DRL syntax. | Optional, may be used repeatedly. |
| Queries | One or more query definitions, according to DRL syntax. | Optional, may be used repeatedly. |
| Declare | One or more declarative types, according to DRL syntax. | Optional, may be used repeatedly. |
Warning
In some locales, MS Office, LibreOffice and OpenOffice will encode a double quoth "
differently, which will cause a compilation error. The difference is often hard to see. For example:
“A” will fail, but "A" will work.
For defining rule attributes that apply to all rules in the generated DRL file you can use any of the entries in the following table. Notice, however, that the proper keyword must be used. Also, each of these attributes may be used only once.
Important
Rule attributes specified in a Rule Set area will affect all rule assets in the same package (not only in the spreadsheet). Unless you are sure that the spreadsheet is the only one rule asset in the package, the recommendation is to specify rule attributes not in a Rule Set area but in a Rule Table columns for each rule instead.
Table 6.6. Rule attribute entries in the Rule Set area
| Keyword | Initial | Value |
|---|---|---|
| PRIORITY | P | An integer defining the "salience" value for the rule. Overridden by the "Sequential" flag. |
| DURATION | D | A long integer value defining the "duration" value for the rule. |
| TIMER | T | A timer definition. See "Timers and Calendars". |
| ENABLED | B | A Boolean value. "true" enables the rule; "false" disables the rule. |
| CALENDARS | E | A calendars definition. See "Timers and Calendars". |
| NO-LOOP | U | A Boolean value. "true" inhibits looping of rules due to changes made by its consequence. |
| LOCK-ON-ACTIVE | L | A Boolean value. "true" inhibits additional activations of all rules with this flag set within the same ruleflow or agenda group. |
| AUTO-FOCUS | F | A Boolean value. "true" for a rule within an agenda group causes activations of the rule to automatically give the focus to the group. |
| ACTIVATION-GROUP | X | A string identifying an activation (or XOR) group. Only one rule within an activation group will fire, i.e., the first one to fire cancels any existing activations of other rules within the same group. |
| AGENDA-GROUP | G | A string identifying an agenda group, which has to be activated by giving it the "focus", which is one way of controlling the flow between groups of rules. |
| RULEFLOW-GROUP | R | A string identifying a rule-flow group. |
All Rule Tables begin with a cell containing "RuleTable", optionally followed by a string within the same cell. The string is used as the initial part of the name for all rules derived from this Rule Table, with the row number appended for distinction. (This automatic naming can be overridden by using a NAME column.) All other cells defining rules of this Rule Table are below and to the right of this cell.
The next row defines the column type, with each column resulting in a part of the condition or the consequence, or providing some rule attribute, the rule name or a comment. The table below shows which column headers are available; additional columns may be used according to the table showing rule attribute entries given in the preceding section. Note that each attribute column may be used at most once. For a column header, either use the keyword or any other word beginning with the letter given in the "Initial" column of these tables.
Table 6.7. Column Headers in the Rule Table
| Keyword | Initial | Value | Usage |
|---|---|---|---|
| NAME | N | Provides the name for the rule generated from that row. The default is constructed from the text following the RuleTable tag and the row number. | At most one column |
| DESCRIPTION | I | A text, resulting in a comment within the generated rule. | At most one column |
| CONDITION | C | Code snippet and interpolated values for constructing a constraint within a pattern in a condition. | At least one per rule table |
| ACTION | A | Code snippet and interpolated values for constructing an action for the consequence of the rule. | At least one per rule table |
| METADATA | @ | Code snippet and interpolated values for constructing a metadata entry for the rule. | Optional, any number of columns |
Given a column headed CONDITION, the cells in successive lines result in a conditional element.
Text in the first cell below CONDITION develops into a pattern for the rule condition, with the snippet in the next line becoming a constraint. If the cell is merged with one or more neighbours, a single pattern with multiple constraints is formed: all constraints are combined into a parenthesized list and appended to the text in this cell. The cell may be left blank, which means that the code snippet in the next row must result in a valid conditional element on its own.
To include a pattern without constraints, you can write the pattern in front of the text for another pattern.
The pattern may be written with or without an empty pair of parentheses. A "from" clause may be appended to the pattern.
If the pattern ends with "eval", code snippets are supposed to produce boolean expressions for inclusion into a pair of parentheses after "eval".
Text in the second cell below CONDITION is processed in two steps.
The code snippet in this cell is modified by interpolating values from cells farther down in the column. If you want to create a constraint consisting of a comparison using "==" with the value from the cells below, the field selector alone is sufficient. Any other comparison operator must be specified as the last item within the snippet, and the value from the cells below is appended. For all other constraint forms, you must mark the position for including the contents of a cell with the symbol
$param. Multiple insertions are possible by using the symbols$1,$2, etc., and a comma-separated list of values in the cells below.A text according to the pattern
forall(delimiter){snippet}is expanded by repeating the snippet once for each of the values of the comma-separated list of values in each of the cells below, inserting the value in place of the symbol$and by joining these expansions by the given delimiter. Note that the forall construct may be surrounded by other text.If the cell in the preceding row is not empty, the completed code snippet is added to the conditional element from that cell. A pair of parentheses is provided automatically, as well as a separating comma if multiple constraints are added to a pattern in a merged cell.
If the cell above is empty, the interpolated result is used as is.
Text in the third cell below CONDITION is for documentation only. It should be used to indicate the column's purpose to a human reader.
From the fourth row on, non-blank entries provide data for interpolation as described above. A blank cell results in the omission of the conditional element or constraint for this rule.
Given a column headed ACTION, the cells in successive lines result in an action statement.
Text in the first cell below ACTION is optional. If present, it is interpreted as an object reference.
Text in the second cell below ACTION is processed in two steps.
The code snippet in this cell is modified by interpolating values from cells farther down in the column. For a singular insertion, mark the position for including the contents of a cell with the symbol
$param. Multiple insertions are possible by using the symbols$1,$2, etc., and a comma-separated list of values in the cells below.A method call without interpolation can be achieved by a text without any marker symbols. In this case, use any non-blank entry in a row below to include the statement.
The forall construct is available here, too.
If the first cell is not empty, its text, followed by a period, the text in the second cell and a terminating semicolon are stringed together, resulting in a method call which is added as an action statement for the consequence.
If the cell above is empty, the interpolated result is used as is.
Text in the third cell below ACTION is for documentation only. It should be used to indicate the column's purpose to a human reader.
From the fourth row on, non-blank entries provide data for interpolation as described above. A blank cell results in the omission of the action statement for this rule.
Note
Using $1 instead of $param works in most cases, but it will fail if the
replacement text contains a comma: then, only the part preceding the first comma is inserted. Use this
"abbreviation" judiciously.
Given a column headed METADATA, the cells in successive lines result in a metadata annotation for the generated rules.
Text in the first cell below METADATA is ignored.
Text in the second cell below METADATA is subject to interpolation, as described above, using values from the cells in the rule rows. The metadata marker character
@is prefixed automatically, and thus it should not be included in the text for this cell.Text in the third cell below METADATA is for documentation only. It should be used to indicate the column's purpose to a human reader.
From the fourth row on, non-blank entries provide data for interpolation as described above. A blank cell results in the omission of the metadata annotation for this rule.
The various interpolations are illustrated in the following example.
Example 6.5. Interpolating cell data
If the template is Foo(bar == $param) and the cell is 42,
then the result is Foo(bar == 42).
If the template is Foo(bar < $1, baz == $2) and the cell contains
42,43, the result will be Foo(bar < 42, baz ==43).
The template forall(&&){bar != $} with a cell containing
42,43 results in bar != 42 && bar != 43.
The next example demonstrates the joint effect of a cell defining the pattern type and the code snippet below it.

This spreadsheet section shows how the Person type declaration
spans 2 columns, and thus both constraints will appear as Person(age == ..., type ==
...). Since only the field names are present in the snippet, they imply an equality
test.
In the following example the marker symbol $param is used.

The result of this column is the pattern Person(age == "42")).
You may have noticed that the marker and the operator "==" are redundant.
The next example illustrates that a trailing insertion marker can be omitted.

Here, appending the value from the cell is implied, resulting in
Person(age < "42")).
You can provide the definition of a binding variable, as in the example below. .

Here, the result is c: Cheese(type == "stilton"). Note that the
quotes are provided automatically. Actually, anything can be placed in the object type row.
Apart from the definition of a binding variable, it could also be an additional pattern that
is to be inserted literally.
A simple construction of an action statement with the insertion of a single value is shown below.

The cell below the ACTION header is left blank. Using this style, anything can be placed in the consequence, not just a single method call. (The same technique is applicable within a CONDITION column as well.)
Below is a comprehensive example, showing the use of various column headers. It is not an error to have no value below a column header (as in the NO-LOOP column): here, the attribute will not be applied in any of the rules.
And, finally, here is an example of Import, Variables and Functions.

Multiple package names within the same cell must be separated by a comma. Also,
the pairs of type and variable names must be comma-separated. Functions, however, must be
written as they appear in a DRL file. This should appear in the same column as the "RuleSet"
keyword; it could be above, between or below all the rule rows.
Note
It may be more convenient to use Import, Variables, Functions and Queries repeatedly rather than packing several definitions into a single cell.
The API to use spreadsheet based decision tables is in the drools-decisiontables module. There is really only
one class to look at: SpreadsheetCompiler. This class will take spreadsheets in various formats,
and generate rules in DRL (which you can then use in the normal way). The SpreadsheetCompiler can
just be used to generate partial rule files if it is wished, and assemble it into a complete rule package after the
fact (this allows the separation of technical and non-technical aspects of the rules if needed).
To get started, a sample spreadsheet can be used as a base. Alternatively, if the plug-in is being used (Rule Workbench IDE), the wizard can generate a spreadsheet from a template (to edit it an xls compatible spreadsheet editor will need to be used).
Spreadsheets are well established business tools (in use for over 25 years). Decision tables lend themselves to close collaboration between IT and domain experts, while making the business rules clear to business analysts, it is an ideal separation of concerns.
Typically, the whole process of authoring rules (coming up with a new decision table) would be something like:
Business analyst takes a template decision table (from a repository, or from IT)
Decision table business language descriptions are entered in the table(s)
Decision table rules (rows) are entered (roughly)
Decision table is handed to a technical resource, who maps the business language (descriptions) to scripts (this may involve software development of course, if it is a new application or data model)
Technical person hands back and reviews the modifications with the business analyst.
The business analyst can continue editing the rule rows as needed (moving columns around is also fine etc).
In parallel, the technical person can develop test cases for the rules (liaising with business analysts) as these test cases can be used to verify rules and rule changes once the system is running.
Features of applications like Excel can be used to provide assistance in entering data into spreadsheets, such as validating fields. Lists that are stored in other worksheets can be used to provide valid lists of values for cells, like in the following diagram.

Some applications provide a limited ability to keep a history of changes, but it is recommended to use an alternative means of revision control. When changes are being made to rules over time, older versions are archived (many open source solutions exist for this, such as Subversion or Git).
Related to decision tables (but not necessarily requiring a spreadsheet) are "Rule Templates" (in the drools-templates module). These use any tabular data source as a source of rule data - populating a template to generate many rules. This can allow both for more flexible spreadsheets, but also rules in existing databases for instance (at the cost of developing the template up front to generate the rules).
With Rule Templates the data is separated from the rule and there are no restrictions on which part of the rule is data-driven. So whilst you can do everything you could do in decision tables you can also do the following:
store your data in a database (or any other format)
conditionally generate rules based on the values in the data
use data for any part of your rules (e.g. condition operator, class name, property name)
run different templates over the same data
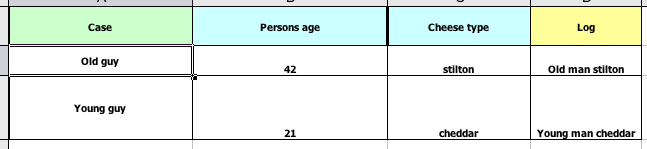
As an example, a more classic decision table is shown, but without any hidden rows for the rule meta data (so the spreadsheet only contains the raw data to generate the rules).
See the ExampleCheese.xls in the examples download for the above
spreadsheet.
If this was a regular decision table there would be hidden rows before row 1 and between rows 1 and 2 containing rule metadata. With rule templates the data is completely separate from the rules. This has two handy consequences - you can apply multiple rule templates to the same data and your data is not tied to your rules at all. So what does the template look like?
1 template header
2 age
3 type
4 log
5
6 package org.drools.examples.templates;
7
8 global java.util.List list;
9
10 template "cheesefans"
11
12 rule "Cheese fans_@{row.rowNumber}"
13 when
14 Person(age == @{age})
15 Cheese(type == "@{type}")
16 then
17 list.add("@{log}");
18 end
19
20 end template
Annotations to the preceding program listing:
Line 1: All rule templates start with
template header.Lines 2-4: Following the header is the list of columns in the order they appear in the data. In this case we are calling the first column
age, the secondtypeand the thirdlog.Line 5: An empty line signifies the end of the column definitions.
Lines 6-9: Standard rule header text. This is standard rule DRL and will appear at the top of the generated DRL. Put the package statement and any imports and global and function definitions into this section.
Line 10: The keyword
templatesignals the start of a rule template. There can be more than one template in a template file, but each template should have a unique name.Lines 11-18: The rule template - see below for details.
Line 20: The keywords
end templatesignify the end of the template.
The rule templates rely on MVEL to do substitution using the syntax @{token_name}. There is currently one built-in expression, @{row.rowNumber} which gives a unique number for each row of data and enables you to generate unique rule names. For each row of data a rule will be generated with the values in the data substituted for the tokens in the template. With the example data above the following rule file would be generated:
package org.drools.examples.templates;
global java.util.List list;
rule "Cheese fans_1"
when
Person(age == 42)
Cheese(type == "stilton")
then
list.add("Old man stilton");
end
rule "Cheese fans_2"
when
Person(age == 21)
Cheese(type == "cheddar")
then
list.add("Young man cheddar");
end
The code to run this is simple:
DecisionTableConfiguration dtableconfiguration =
KnowledgeBuilderFactory.newDecisionTableConfiguration();
dtableconfiguration.setInputType( DecisionTableInputType.XLS );
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory.newKnowledgeBuilder();
kbuilder.add( ResourceFactory.newClassPathResource( getSpreadsheetName(),
getClass() ),
ResourceType.DTABLE,
dtableconfiguration );
One way to illuminate the black box that is a rule engine, is to play with the logging level.
Everything is logged to SLF4J, which is a simple logging facade that can delegate any log to Logback, Apache Commons Logging, Log4j or java.util.logging. Add a dependency to the logging adaptor for your logging framework of choice. If you're not using any logging framework yet, you can use Logback by adding this Maven dependency:
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.x</version>
</dependency>
Note
If you're developing for an ultra light environment, use slf4j-nop or
slf4j-simple instead.
Configure the logging level on the package org.drools. For example:
In Logback, configure it in your logback.xml file:
<configuration>
<logger name="org.drools" level="debug"/>
...
<configuration>
In Log4J, configure it in your log4j.xml file:
<log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/">
<category name="org.drools">
<priority value="debug" />
</category>
...
</log4j:configuration>