Drools rule engine
The Drools rule engine stores, processes, and evaluates data to execute the business rules or decision models that you define. The basic function of the Drools rule engine is to match incoming data, or facts, to the conditions of rules and determine whether and how to execute the rules.
The Drools rule engine operates using the following basic components:
-
Rules: Business rules or DMN decisions that you define. All rules must contain at a minimum the conditions that trigger the rule and the actions that the rule dictates.
-
Facts: Data that enters or changes in the Drools rule engine that the Drools rule engine matches to rule conditions to execute applicable rules.
-
Production memory: Location where rules are stored in the Drools rule engine.
-
Working memory: Location where facts are stored in the Drools rule engine.
-
Agenda: Location where activated rules are registered and sorted (if applicable) in preparation for execution.
When a business user or an automated system adds or updates rule-related information in Drools, that information is inserted into the working memory of the Drools rule engine in the form of one or more facts. The Drools rule engine matches those facts to the conditions of the rules that are stored in the production memory to determine eligible rule executions. (This process of matching facts to rules is often referred to as pattern matching.) When rule conditions are met, the Drools rule engine activates and registers rules in the agenda, where the Drools rule engine then sorts prioritized or conflicting rules in preparation for execution.
The following diagram illustrates these basic components of the Drools rule engine:
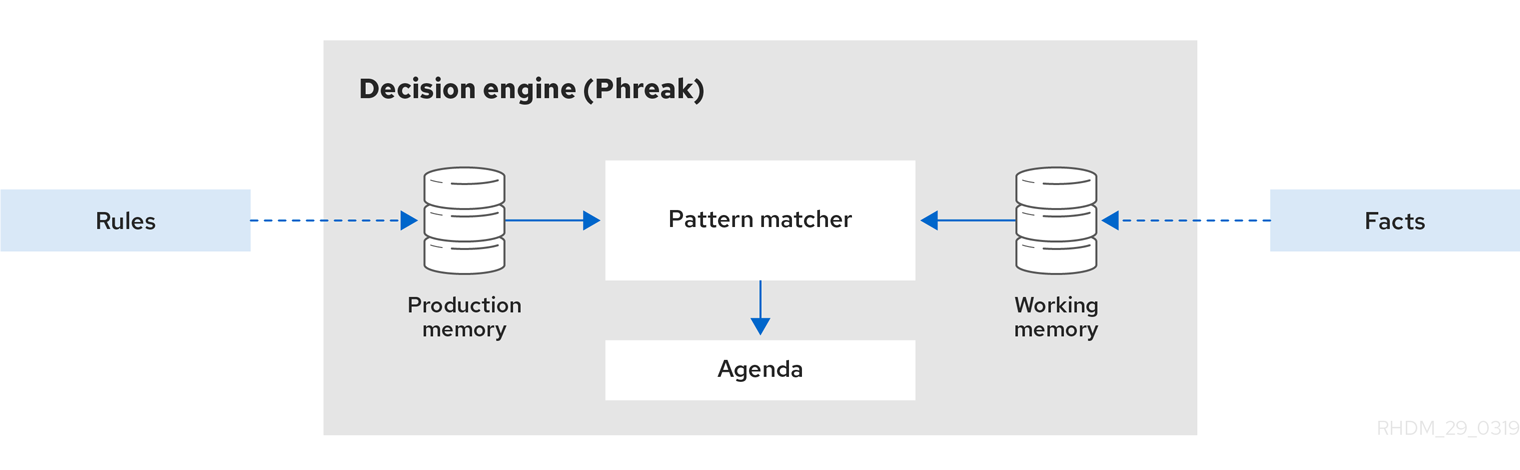
For more details and examples of rule and fact behavior in the Drools rule engine, see Inference and truth maintenance in the Drools rule engine.
These core concepts can help you to better understand other more advanced components, processes, and sub-processes of the Drools rule engine, and as a result, to design more effective business assets in Drools.
KIE sessions
In Drools, a KIE session stores and executes runtime data. The KIE session is created from a KIE base or directly from a KIE container if you have defined the KIE session in the KIE module descriptor file (kmodule.xml) for your project.
kmodule.xml file<kmodule>
...
<kbase>
...
<ksession name="KSession2_1" type="stateless" default="true" clockType="realtime">
...
</kbase>
...
</kmodule>A KIE base is a repository that you define in the KIE module descriptor file (kmodule.xml) for your project and contains all
in Drools, but does not contain any runtime data.
kmodule.xml file<kmodule>
...
<kbase name="KBase2" default="false" eventProcessingMode="stream" equalsBehavior="equality" declarativeAgenda="enabled" packages="org.domain.pkg2, org.domain.pkg3" includes="KBase1">
...
</kbase>
...
</kmodule>A KIE session can be stateless or stateful. In a stateless KIE session, data from a previous invocation of the KIE session (the previous session state) is discarded between session invocations. In a stateful KIE session, that data is retained. The type of KIE session you use depends on your project requirements and how you want data from different asset invocations to be persisted.
Stateless KIE sessions
A stateless KIE session is a session that does not use inference to make iterative changes to facts over time. In a stateless KIE session, data from a previous invocation of the KIE session (the previous session state) is discarded between session invocations, whereas in a stateful KIE session, that data is retained. A stateless KIE session behaves similarly to a function in that the results that it produces are determined by the contents of the KIE base and by the data that is passed into the KIE session for execution at a specific point in time. The KIE session has no memory of any data that was passed into the KIE session previously.
Stateless KIE sessions are commonly used for the following use cases:
-
Validation, such as validating that a person is eligible for a mortgage
-
Calculation, such as computing a mortgage premium
-
Routing and filtering, such as sorting incoming emails into folders or sending incoming emails to a destination
For example, consider the following driver’s license data model and sample DRL rule:
public class Applicant {
private String name;
private int age;
private boolean valid;
// Getter and setter methods
}package com.company.license
rule "Is of valid age"
when
$a : Applicant(age < 18)
then
$a.setValid(false);
endThe Is of valid age rule disqualifies any applicant younger than 18 years old. When the Applicant object is inserted into the Drools rule engine, the Drools rule engine evaluates the constraints for each rule and searches for a match. The "objectType" constraint is always implied, after which any number of explicit field constraints are evaluated. The variable $a is a binding variable that references the matched object in the rule consequence.
|
The dollar sign ( |
In this example, the sample rule and all other files in the ~/resources folder of the Drools project are built with the following code:
KieServices kieServices = KieServices.Factory.get();
KieContainer kContainer = kieServices.getKieClasspathContainer();This code compiles all the rule files found on the class path and adds the result of this compilation, a KieModule object, in the KieContainer.
Finally, the StatelessKieSession object is instantiated from the KieContainer and is executed against specified data:
StatelessKieSession kSession = kContainer.newStatelessKieSession();
Applicant applicant = new Applicant("Mr John Smith", 16);
assertTrue(applicant.isValid());
ksession.execute(applicant);
assertFalse(applicant.isValid());In a stateless KIE session configuration, the execute() call acts as a combination method that instantiates the KieSession object, adds all the user data and executes user commands, calls fireAllRules(), and then calls dispose(). Therefore, with a stateless KIE session, you do not need to call fireAllRules() or call dispose() after session invocation as you do with a stateful KIE session.
In this case, the specified applicant is under the age of 18, so the application is declined.
For a more complex use case, see the following example. This example uses a stateless KIE session and executes rules against an iterable list of objects, such as a collection.
public class Applicant {
private String name;
private int age;
// Getter and setter methods
}
public class Application {
private Date dateApplied;
private boolean valid;
// Getter and setter methods
}package com.company.license
rule "Is of valid age"
when
Applicant(age < 18)
$a : Application()
then
$a.setValid(false);
end
rule "Application was made this year"
when
$a : Application(dateApplied > "01-jan-2009")
then
$a.setValid(false);
endStatelessKieSession ksession = kbase.newStatelessKnowledgeSession();
Applicant applicant = new Applicant("Mr John Smith", 16);
Application application = new Application();
assertTrue(application.isValid());
ksession.execute(Arrays.asList(new Object[] { application, applicant })); (1)
assertFalse(application.isValid());
ksession.execute
(CommandFactory.newInsertIterable(new Object[] { application, applicant })); (2)
List<Command> cmds = new ArrayList<Command>(); (3)
cmds.add(CommandFactory.newInsert(new Person("Mr John Smith"), "mrSmith"));
cmds.add(CommandFactory.newInsert(new Person("Mr John Doe"), "mrDoe"));
BatchExecutionResults results = ksession.execute(CommandFactory.newBatchExecution(cmds));
assertEquals(new Person("Mr John Smith"), results.getValue("mrSmith"));| 1 | Method for executing rules against an iterable collection of objects produced by the Arrays.asList() method. Every collection element is inserted before any matched rules are executed. The execute(Object object) and execute(Iterable objects) methods are wrappers around the execute(Command command) method that comes from the BatchExecutor interface. |
| 2 | Execution of the iterable collection of objects using the CommandFactory interface. |
| 3 | BatchExecutor and CommandFactory configurations for working with many different commands or result output identifiers. The CommandFactory interface supports other commands that you can use in the BatchExecutor, such as StartProcess, Query, and SetGlobal. |
Global variables in stateless KIE sessions
The StatelessKieSession object supports global variables (globals) that you can configure to be resolved as session-scoped globals, delegate globals, or execution-scoped globals.
-
Session-scoped globals: For session-scoped globals, you can use the method
getGlobals()to return aGlobalsinstance that provides access to the KIE session globals. These globals are used for all execution calls. Use caution with mutable globals because execution calls can be executing simultaneously in different threads.Session-scoped globalimport org.kie.api.runtime.StatelessKieSession; StatelessKieSession ksession = kbase.newStatelessKieSession(); // Set a global `myGlobal` that can be used in the rules. ksession.setGlobal("myGlobal", "I am a global"); // Execute while resolving the `myGlobal` identifier. ksession.execute(collection); -
Delegate globals: For delegate globals, you can assign a value to a global (with
setGlobal(String, Object)) so that the value is stored in an internal collection that maps identifiers to values. Identifiers in this internal collection have priority over any supplied delegate. If an identifier cannot be found in this internal collection, the delegate global (if any) is used. -
Execution-scoped globals: For execution-scoped globals, you can use the
Commandobject to set a global that is passed to theCommandExecutorinterface for execution-specific global resolution.
The CommandExecutor interface also enables you to export data using out identifiers for globals, inserted facts, and query results:
import org.kie.api.runtime.ExecutionResults;
// Set up a list of commands.
List cmds = new ArrayList();
cmds.add(CommandFactory.newSetGlobal("list1", new ArrayList(), true));
cmds.add(CommandFactory.newInsert(new Person("jon", 102), "person"));
cmds.add(CommandFactory.newQuery("Get People" "getPeople"));
// Execute the list.
ExecutionResults results = ksession.execute(CommandFactory.newBatchExecution(cmds));
// Retrieve the `ArrayList`.
results.getValue("list1");
// Retrieve the inserted `Person` fact.
results.getValue("person");
// Retrieve the query as a `QueryResults` instance.
results.getValue("Get People");Stateful KIE sessions
A stateful KIE session is a session that uses inference to make iterative changes to facts over time. In a stateful KIE session, data from a previous invocation of the KIE session (the previous session state) is retained between session invocations, whereas in a stateless KIE session, that data is discarded.
Ensure that you call the dispose() method after running a stateful KIE session so that no memory leaks occur between session invocations.
|
Stateful KIE sessions are commonly used for the following use cases:
-
Monitoring, such as monitoring a stock market and automating the buying process
-
Diagnostics, such as running fault-finding processes or medical diagnostic processes
-
Logistics, such as parcel tracking and delivery provisioning
-
Ensuring compliance, such as verifying the legality of market trades
For example, consider the following fire alarm data model and sample DRL rules:
public class Room {
private String name;
// Getter and setter methods
}
public class Sprinkler {
private Room room;
private boolean on;
// Getter and setter methods
}
public class Fire {
private Room room;
// Getter and setter methods
}
public class Alarm { }rule "When there is a fire turn on the sprinkler"
when
Fire($room : room)
$sprinkler : Sprinkler(room == $room, on == false)
then
modify($sprinkler) { setOn(true) };
System.out.println("Turn on the sprinkler for room "+$room.getName());
end
rule "Raise the alarm when we have one or more fires"
when
exists Fire()
then
insert( new Alarm() );
System.out.println( "Raise the alarm" );
end
rule "Cancel the alarm when all the fires have gone"
when
not Fire()
$alarm : Alarm()
then
delete( $alarm );
System.out.println( "Cancel the alarm" );
end
rule "Status output when things are ok"
when
not Alarm()
not Sprinkler( on == true )
then
System.out.println( "Everything is ok" );
endFor the When there is a fire turn on the sprinkler rule, when a fire occurs, the instances of the Fire class are created for that room and inserted into the KIE session. The rule adds a constraint for the specific room matched in the Fire instance so that only the sprinkler for that room is checked. When this rule is executed, the sprinkler activates. The other sample rules determine when the alarm is activated or deactivated accordingly.
Whereas a stateless KIE session relies on standard Java syntax to modify a field, a stateful KIE session relies on the modify statement in rules to notify the Drools rule engine of changes. The Drools rule engine then reasons over the changes and assesses impact on subsequent rule executions. This process is part of the Drools rule engine ability to use inference and truth maintenance and is essential in stateful KIE sessions.
In this example, the sample rules and all other files in the ~/resources folder of the Drools project are built with the following code:
KieServices kieServices = KieServices.Factory.get();
KieContainer kContainer = kieServices.getKieClasspathContainer();This code compiles all the rule files found on the class path and adds the result of this compilation, a KieModule object, in the KieContainer.
Finally, the KieSession object is instantiated from the KieContainer and is executed against specified data:
KieSession ksession = kContainer.newKieSession();
String[] names = new String[]{"kitchen", "bedroom", "office", "livingroom"};
Map<String,Room> name2room = new HashMap<String,Room>();
for( String name: names ){
Room room = new Room( name );
name2room.put( name, room );
ksession.insert( room );
Sprinkler sprinkler = new Sprinkler( room );
ksession.insert( sprinkler );
}
ksession.fireAllRules();> Everything is okWith the data added, the Drools rule engine completes all pattern matching but no rules have been executed, so the configured verification message appears. As new data triggers rule conditions, the Drools rule engine executes rules to activate the alarm and later to cancel the alarm that has been activated:
Fire kitchenFire = new Fire( name2room.get( "kitchen" ) );
Fire officeFire = new Fire( name2room.get( "office" ) );
FactHandle kitchenFireHandle = ksession.insert( kitchenFire );
FactHandle officeFireHandle = ksession.insert( officeFire );
ksession.fireAllRules();> Raise the alarm
> Turn on the sprinkler for room kitchen
> Turn on the sprinkler for room officeksession.delete( kitchenFireHandle );
ksession.delete( officeFireHandle );
ksession.fireAllRules();> Cancel the alarm
> Turn off the sprinkler for room office
> Turn off the sprinkler for room kitchen
> Everything is okIn this case, a reference is kept for the returned FactHandle object. A fact handle is an internal engine reference to the inserted instance and enables instances to be retracted or modified later.
As this example illustrates, the data and results from previous stateful KIE sessions (the activated alarm) affect the invocation of subsequent sessions (alarm cancellation).
KIE session pools
In use cases with large amounts of KIE runtime data and high system activity, KIE sessions might be created and disposed very frequently. A high turnover of KIE sessions is not always time consuming, but when the turnover is repeated millions of times, the process can become a bottleneck and require substantial clean-up effort.
For these high-volume cases, you can use KIE session pools instead of many individual KIE sessions. To use a KIE session pool, you obtain a KIE session pool from a KIE container, define the initial number of KIE sessions in the pool, and create the KIE sessions from that pool as usual:
// Obtain a KIE session pool from the KIE container
KieContainerSessionsPool pool = kContainer.newKieSessionsPool(10);
// Create KIE sessions from the KIE session pool
KieSession kSession = pool.newKieSession();In this example, the KIE session pool starts with 10 KIE sessions in it, but you can specify the number of KIE sessions that you need. This integer value is the number of KIE sessions that are only initially created in the pool. If required by the running application, the number of KIE sessions in the pool can dynamically grow beyond that value.
After you define a KIE session pool, the next time you use the KIE session as usual and call dispose() on it, the KIE session is reset and pushed back into the pool instead of being destroyed.
KIE session pools typically apply to stateful KIE sessions, but KIE session pools can also affect stateless KIE sessions that you reuse with multiple execute() calls. When you create a stateless KIE session directly from a KIE container, the KIE session continues to internally create a new KIE session for each execute() invocation. Conversely, when you create a stateless KIE session from a KIE session pool, the KIE session internally uses only the specific KIE sessions provided by the pool.
When you finish using a KIE session pool, you can call the shutdown() method on it to avoid memory leaks. Alternatively, you can call dispose() on the KIE container to shut down all the pools created from the KIE container.
Inference and truth maintenance in the Drools rule engine
The basic function of the Drools rule engine is to match data to business rules and determine whether and how to execute rules. To ensure that relevant data is applied to the appropriate rules, the Drools rule engine makes inferences based on existing knowledge and performs the actions based on the inferred information.
For example, the following DRL rule determines the age requirements for adults, such as in a bus pass policy:
rule "Infer Adult"
when
$p : Person(age >= 18)
then
insert(new IsAdult($p))
endBased on this rule, the Drools rule engine infers whether a person is an adult or a child and performs the specified action (the then consequence). Every person who is 18 years old or older has an instance of IsAdult inserted for them in the working memory. This inferred relation of age and bus pass can then be invoked in any rule, such as in the following rule segment:
$p : Person()
IsAdult(person == $p)In many cases, new data in a rule system is the result of other rule executions, and this new data can affect the execution of other rules. If the Drools rule engine asserts data as a result of executing a rule, the Drools rule engine uses truth maintenance to justify the assertion and enforce truthfulness when applying inferred information to other rules. Truth maintenance also helps to identify inconsistencies and to handle contradictions. For example, if two rules are executed and result in a contradictory action, the Drools rule engine chooses the action based on assumptions from previously calculated conclusions.
The Drools rule engine inserts facts using either stated or logical insertions:
-
Stated insertions: Defined with
insert(). After stated insertions, facts are generally retracted explicitly. (The term insertion, when used generically, refers to stated insertion.) -
Logical insertions: Defined with
insertLogical(). After logical insertions, the facts that were inserted are automatically retracted when the conditions in the rules that inserted the facts are no longer true. The facts are retracted when no condition supports the logical insertion. A fact that is logically inserted is considered to be justified by the Drools rule engine.
For example, the following sample DRL rules use stated fact insertion to determine the age requirements for issuing a child bus pass or an adult bus pass:
rule "Issue Child Bus Pass"
when
$p : Person(age < 18)
then
insert(new ChildBusPass($p));
end
rule "Issue Adult Bus Pass"
when
$p : Person(age >= 18)
then
insert(new AdultBusPass($p));
endThese rules are not easily maintained in the Drools rule engine as bus riders increase in age and move from child to adult bus pass. As an alternative, these rules can be separated into rules for bus rider age and rules for bus pass type using logical fact insertion. The logical insertion of the fact makes the fact dependent on the truth of the when clause.
The following DRL rules use logical insertion to determine the age requirements for children and adults:
rule "Infer Child"
when
$p : Person(age < 18)
then
insertLogical(new IsChild($p))
end
rule "Infer Adult"
when
$p : Person(age >= 18)
then
insertLogical(new IsAdult($p))
end
For logical insertions, your fact objects must override the equals and hashCode methods from the java.lang.Object object according to the Java standard. Two objects are equal if their equals methods return true for each other and if their hashCode methods return the same values. For more information, see the Java API documentation for your Java version.
|
When the condition in the rule is false, the fact is automatically retracted. This behavior is helpful in this example because the two rules are mutually exclusive. In this example, if the person is younger than 18 years old, the rule logically inserts an IsChild fact. After the person is 18 years old or older, the IsChild fact is automatically retracted and the IsAdult fact is inserted.
The following DRL rules then determine whether to issue a child bus pass or an adult bus pass and logically insert the ChildBusPass and AdultBusPass facts. This rule configuration is possible because the truth maintenance system in the Drools rule engine supports chaining of logical insertions for a cascading set of retracts.
rule "Issue Child Bus Pass"
when
$p : Person()
IsChild(person == $p)
then
insertLogical(new ChildBusPass($p));
end
rule "Issue Adult Bus Pass"
when
$p : Person()
IsAdult(person =$p)
then
insertLogical(new AdultBusPass($p));
endWhen a person turns 18 years old, the IsChild fact and the person’s ChildBusPass fact is retracted. To these set of conditions, you can relate another rule that states that a person must return the child pass after turning 18 years old. When the Drools rule engine automatically retracts the ChildBusPass object, the following rule is executed to send a request to the person:
rule "Return ChildBusPass Request"
when
$p : Person()
not(ChildBusPass(person == $p))
then
requestChildBusPass($p);
endThe following flowcharts illustrate the life cycle of stated and logical insertions:
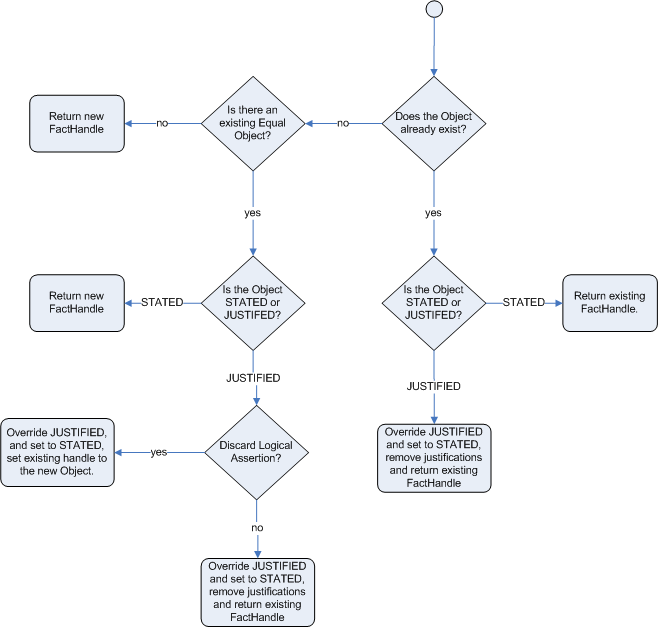
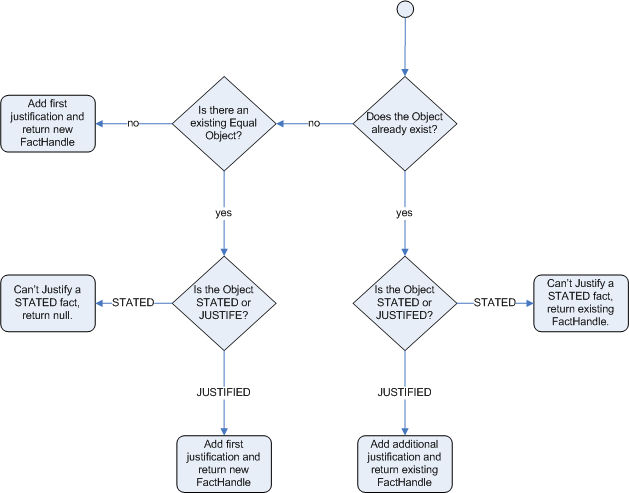
When the Drools rule engine logically inserts an object during a rule execution, the Drools rule engine justifies the object by executing the rule. For each logical insertion, only one equal object can exist, and each subsequent equal logical insertion increases the justification counter for that logical insertion. A justification is removed when the conditions of the rule become untrue. When no more justifications exist, the logical object is automatically retracted.
Government ID example
So now we know what inference is, and have a basic example, how does this facilitate good rule design and maintenance?
Consider a government ID department that is responsible for issuing ID cards when children become adults. They might have a decision table that includes logic like this, which says when an adult living in London is 18 or over, issue the card:
RuleTable ID Card |
|||
CONDITION |
CONDITION |
ACTION |
|
p : Person |
|||
location |
age >= $1 |
issueIdCard($1) |
|
Select Person |
Select Adults |
Issue ID Card |
|
Issue ID Card to Adults |
London |
18 |
p |
However the ID department does not set the policy on who an adult is. That’s done at a central government level. If the central government were to change that age to 21, this would initiate a change management process. Someone would have to liaise with the ID department and make sure their systems are updated, in time for the law going live.
This change management process and communication between departments is not ideal for an agile environment, and change becomes costly and error prone. Also the card department is managing more information than it needs to be aware of with its "monolithic" approach to rules management which is "leaking" information better placed elsewhere. By this I mean that it doesn’t care what explicit "age >= 18" information determines whether someone is an adult, only that they are an adult.
In contrast to this, let’s pursue an approach where we split (de-couple) the authoring responsibilities, so that both the central government and the ID department maintain their own rules.
It’s the central government’s job to determine who is an adult. If they change the law they just update their central repository with the new rules, which others use:
RuleTable Age Policy |
||
CONDITION |
ACTION |
|
p : Person |
||
age >= $1 |
insert($1) |
|
Adult Age Policy |
Add Adult Relation |
|
Infer Adult |
18 |
new IsAdult( p ) |
The IsAdult fact, as discussed previously, is inferred from the policy rules. It encapsulates the seemingly arbitrary piece of logic "age >= 18" and provides semantic abstractions for its meaning. Now if anyone uses the above rules, they no longer need to be aware of explicit information that determines whether someone is an adult or not. They can just use the inferred fact:
RuleTable ID Card |
|||
CONDITION |
CONDITION |
ACTION |
|
p : Person |
isAdult |
||
location |
person == $1 |
issueIdCard($1) |
|
Select Person |
Select Adults |
Issue ID Card |
|
Issue ID Card to Adults |
London |
p |
p |
While the example is very minimal and trivial it illustrates some important points. We started with a monolithic and leaky approach to our knowledge engineering. We created a single decision table that had all possible information in it and that leaks information from central government that the ID department did not care about and did not want to manage.
We first de-coupled the knowledge process so each department was responsible for only what it needed to know. We then encapsulated this leaky knowledge using an inferred fact IsAdult. The use of the term IsAdult also gave a semantic abstraction to the previously arbitrary logic "age >= 18".
So a general rule of thumb when doing your knowledge engineering is:
-
Bad
-
Monolithic
-
Leaky
-
-
Good
-
De-couple knowledge responsibilities
-
Encapsulate knowledge
-
Provide semantic abstractions for those encapsulations
-
Fact equality modes in the Drools rule engine
The Drools rule engine supports the following fact equality modes that determine how the Drools rule engine stores and compares inserted facts:
-
identity: (Default) The Drools rule engine uses anIdentityHashMapto store all inserted facts. For every new fact insertion, the Drools rule engine returns a newFactHandleobject. If a fact is inserted again, the Drools rule engine returns the originalFactHandleobject, ignoring repeated insertions for the same fact. In this mode, two facts are the same for the Drools rule engine only if they are the very same object with the same identity. -
equality: The Drools rule engine uses aHashMapto store all inserted facts. The Drools rule engine returns a newFactHandleobject only if the inserted fact is not equal to an existing fact, according to theequals()method of the inserted fact. In this mode, two facts are the same for the Drools rule engine if they are composed the same way, regardless of identity. Use this mode when you want objects to be assessed based on feature equality instead of explicit identity.
As an illustration of fact equality modes, consider the following example facts:
Person p1 = new Person("John", 45);
Person p2 = new Person("John", 45);In identity mode, facts p1 and p2 are different instances of a Person class and are treated as separate objects because they have separate identities. In equality mode, facts p1 and p2 are treated as the same object because they are composed the same way. This difference in behavior affects how you can interact with fact handles.
For example, assume that you insert facts p1 and p2 into the Drools rule engine and later you want to retrieve the fact handle for p1. In identity mode, you must specify p1 to return the fact handle for that exact object, whereas in equality mode, you can specify p1, p2, or new Person("John", 45) to return the fact handle.
identity modeksession.insert(p1);
ksession.getFactHandle(p1);equality modeksession.insert(p1);
ksession.getFactHandle(p1);
// Alternate option:
ksession.getFactHandle(new Person("John", 45));To set the fact equality mode, use one of the following options:
-
Set the system property
drools.equalityBehaviortoidentity(default) orequality. -
Set the equality mode while creating the KIE base programmatically:
KieServices ks = KieServices.get(); KieBaseConfiguration kieBaseConf = ks.newKieBaseConfiguration(); kieBaseConf.setOption(EqualityBehaviorOption.EQUALITY); KieBase kieBase = kieContainer.newKieBase(kieBaseConf); -
Set the equality mode in the KIE module descriptor file (
kmodule.xml) for a specific Drools project:<kmodule> ... <kbase name="KBase2" default="false" equalsBehavior="equality" packages="org.domain.pkg2, org.domain.pkg3" includes="KBase1"> ... </kbase> ... </kmodule>
Execution control in the Drools rule engine
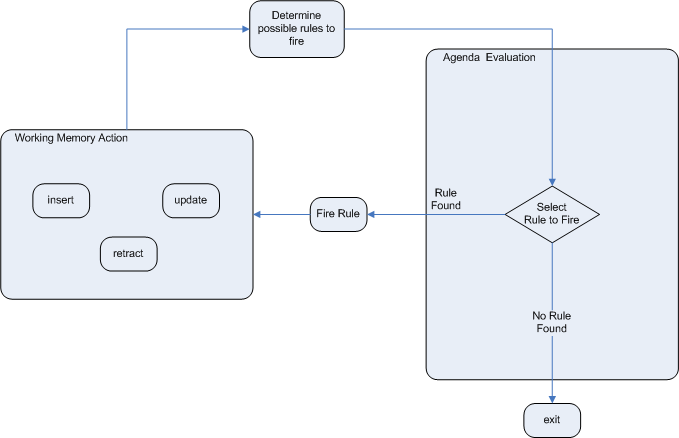
When new rule data enters the working memory of the Drools rule engine, rules may become fully matched and eligible for execution. A single working memory action can result in multiple eligible rule executions. When a rule is fully matched, the Drools rule engine creates an activation instance, referencing the rule and the matched facts, and adds the activation onto the Drools rule engine agenda. The agenda controls the execution order of these rule activations using a conflict resolution strategy.
After the first call of fireAllRules() in the Java application, the Drools rule engine cycles repeatedly through two phases:
-
Agenda evaluation. In this phase, the Drools rule engine selects all rules that can be executed. If no executable rules exist, the execution cycle ends. If an executable rule is found, the Drools rule engine registers the activation in the agenda and then moves on to the working memory actions phase to perform rule consequence actions.
-
Working memory actions. In this phase, the Drools rule engine performs the rule consequence actions (the
thenportion of each rule) for all activated rules previously registered in the agenda. After all the consequence actions are complete or the main Java application process callsfireAllRules()again, the Drools rule engine returns to the agenda evaluation phase to reassess rules.
When multiple rules exist on the agenda, the execution of one rule may cause another rule to be removed from the agenda. To avoid this, you can define how and when rules are executed in the Drools rule engine. Some common methods for defining rule execution order are by using rule salience, agenda groups, or activation groups.
Salience for rules
Each rule has an integer salience attribute that determines the order of execution. Rules with a higher salience value are given higher priority when ordered in the activation queue. The default salience value for rules is zero, but the salience can be negative or positive.
For example, the following sample DRL rules are listed in the Drools rule engine stack in the order shown:
rule "RuleA"
salience 95
when
$fact : MyFact( field1 == true )
then
System.out.println("Rule2 : " + $fact);
update($fact);
end
rule "RuleB"
salience 100
when
$fact : MyFact( field1 == false )
then
System.out.println("Rule1 : " + $fact);
$fact.setField1(true);
update($fact);
endThe RuleB rule is listed second, but it has a higher salience value than the RuleA rule and is therefore executed first.
Agenda groups for rules
An agenda group is a set of rules bound together by the same agenda-group rule attribute. Agenda groups partition rules on the Drools rule engine agenda. At any one time, only one group has a focus that gives that group of rules priority for execution before rules in other agenda groups. You determine the focus with a setFocus() call for the agenda group. You can also define rules with an auto-focus attribute so that the next time the rule is activated, the focus is automatically given to the entire agenda group to which the rule is assigned.
Each time the setFocus() call is made in a Java application, the Drools rule engine adds the specified agenda group to the top of the rule stack. The default agenda group "MAIN" contains all rules that do not belong to a specified agenda group and is executed first in the stack unless another group has the focus.
For example, the following sample DRL rules belong to specified agenda groups and are listed in the Drools rule engine stack in the order shown:
rule "Increase balance for credits"
agenda-group "calculation"
when
ap : AccountPeriod()
acc : Account( $accountNo : accountNo )
CashFlow( type == CREDIT,
accountNo == $accountNo,
date >= ap.start && <= ap.end,
$amount : amount )
then
acc.balance += $amount;
endrule "Print balance for AccountPeriod"
agenda-group "report"
when
ap : AccountPeriod()
acc : Account()
then
System.out.println( acc.accountNo +
" : " + acc.balance );
endFor this example, the rules in the "report" agenda group must always be executed first and the rules in the "calculation" agenda group must always be executed second. Any remaining rules in other agenda groups can then be executed. Therefore, the "report" and "calculation" groups must receive the focus to be executed in that order, before other rules can be executed:
Agenda agenda = ksession.getAgenda();
agenda.getAgendaGroup( "report" ).setFocus();
agenda.getAgendaGroup( "calculation" ).setFocus();
ksession.fireAllRules();You can also use the clear() method to cancel all the activations generated by the rules belonging to a given agenda group before each has had a chance to be executed:
ksession.getAgenda().getAgendaGroup( "Group A" ).clear();Activation groups for rules
An activation group is a set of rules bound together by the same activation-group rule attribute. In this group, only one rule can be executed. After conditions are met for a rule in that group to be executed, all other pending rule executions from that activation group are removed from the agenda.
For example, the following sample DRL rules belong to the specified activation group and are listed in the Drools rule engine stack in the order shown:
rule "Print balance for AccountPeriod1"
activation-group "report"
when
ap : AccountPeriod1()
acc : Account()
then
System.out.println( acc.accountNo +
" : " + acc.balance );
endrule "Print balance for AccountPeriod2"
activation-group "report"
when
ap : AccountPeriod2()
acc : Account()
then
System.out.println( acc.accountNo +
" : " + acc.balance );
endFor this example, if the first rule in the "report" activation group is executed, the second rule in the group and all other executable rules on the agenda are removed from the agenda.
Rule execution modes and thread safety in the Drools rule engine
The Drools rule engine supports the following rule execution modes that determine how and when the Drools rule engine executes rules:
-
Passive mode: (Default) The Drools rule engine evaluates rules when a user or an application explicitly calls
fireAllRules(). Passive mode in the Drools rule engine is best for applications that require direct control over rule evaluation and execution, or for complex event processing (CEP) applications that use the pseudo clock implementation in the Drools rule engine.Example CEP application code with the Drools rule engine in passive modeKieSessionConfiguration config = KieServices.Factory.get().newKieSessionConfiguration(); config.setOption( ClockTypeOption.get("pseudo") ); KieSession session = kbase.newKieSession( conf, null ); SessionPseudoClock clock = session.getSessionClock(); session.insert( tick1 ); session.fireAllRules(); clock.advanceTime(1, TimeUnit.SECONDS); session.insert( tick2 ); session.fireAllRules(); clock.advanceTime(1, TimeUnit.SECONDS); session.insert( tick3 ); session.fireAllRules(); session.dispose(); -
Active mode: If a user or application calls
fireUntilHalt(), the Drools rule engine starts in active mode and evaluates rules continually until the user or application explicitly callshalt(). Active mode in the Drools rule engine is best for applications that delegate control of rule evaluation and execution to the Drools rule engine, or for complex event processing (CEP) applications that use the real-time clock implementation in the Drools rule engine. Active mode is also optimal for CEP applications that use active queries.Example CEP application code with the Drools rule engine in active modeKieSessionConfiguration config = KieServices.Factory.get().newKieSessionConfiguration(); config.setOption( ClockTypeOption.get("realtime") ); KieSession session = kbase.newKieSession( conf, null ); new Thread( new Runnable() { @Override public void run() { session.fireUntilHalt(); } } ).start(); session.insert( tick1 ); ... Thread.sleep( 1000L ); ... session.insert( tick2 ); ... Thread.sleep( 1000L ); ... session.insert( tick3 ); session.halt(); session.dispose();This example calls
fireUntilHalt()from a dedicated execution thread to prevent the current thread from being blocked indefinitely while the Drools rule engine continues evaluating rules. The dedicated thread also enables you to callhalt()at a later stage in the application code.
Although you should avoid using both fireAllRules() and fireUntilHalt() calls, especially from different threads, the Drools rule engine can handle such situations safely using thread-safety logic and an internal state machine. If a fireAllRules() call is in progress and you call fireUntilHalt(), the Drools rule engine continues to run in passive mode until the fireAllRules() operation is complete and then starts in active mode in response to the fireUntilHalt() call. However, if the Drools rule engine is running in active mode following a fireUntilHalt() call and you call fireAllRules(), the fireAllRules() call is ignored and the Drools rule engine continues to run in active mode until you call halt().
For added thread safety in active mode, the Drools rule engine supports a submit() method that you can use to group and perform operations on a KIE session in a thread-safe, atomic action:
submit() method to perform atomic operations in active modeKieSession session = ...;
new Thread( new Runnable() {
@Override
public void run() {
session.fireUntilHalt();
}
} ).start();
final FactHandle fh = session.insert( fact_a );
... Thread.sleep( 1000L ); ...
session.submit( new KieSession.AtomicAction() {
@Override
public void execute( KieSession kieSession ) {
fact_a.setField("value");
kieSession.update( fh, fact_a );
kieSession.insert( fact_1 );
kieSession.insert( fact_2 );
kieSession.insert( fact_3 );
}
} );
... Thread.sleep( 1000L ); ...
session.insert( fact_z );
session.halt();
session.dispose();Thread safety and atomic operations are also helpful from a client-side perspective. For example, you might need to insert more than one fact at a given time, but require the Drools rule engine to consider the insertions as an atomic operation and to wait until all the insertions are complete before evaluating the rules again.
Fact propagation modes in the Drools rule engine
The Drools rule engine supports the following fact propagation modes that determine how the Drools rule engine progresses inserted facts through the engine network in preparation for rule execution:
-
Lazy: (Default) Facts are propagated in batch collections at rule execution, not in real time as the facts are individually inserted by a user or application. As a result, the order in which the facts are ultimately propagated through the Drools rule engine may be different from the order in which the facts were individually inserted.
-
Immediate: Facts are propagated immediately in the order that they are inserted by a user or application.
-
Eager: Facts are propagated lazily (in batch collections), but before rule execution. The Drools rule engine uses this propagation behavior for rules that have the
no-looporlock-on-activeattribute.
By default, the Phreak rule algorithm in the Drools rule engine uses lazy fact propagation for improved rule evaluation overall. However, in few cases, this lazy propagation behavior can alter the expected result of certain rule executions that may require immediate or eager propagation.
For example, the following rule uses a specified query with a ? prefix to invoke the query in pull-only or passive fashion:
query Q (Integer i)
String( this == i.toString() )
end
rule "Rule"
when
$i : Integer()
?Q( $i; )
then
System.out.println( $i );
endFor this example, the rule should be executed only when a String that satisfies the query is inserted before the Integer, such as in the following example commands:
KieSession ksession = ...
ksession.insert("1");
ksession.insert(1);
ksession.fireAllRules();However, due to the default lazy propagation behavior in Phreak, the Drools rule engine does not detect the insertion sequence of the two facts in this case, so this rule is executed regardless of String and Integer insertion order. For this example, immediate propagation is required for the expected rule evaluation.
To alter the Drools rule engine propagation mode to achieve the expected rule evaluation in this case, you can add the @Propagation(<type>) tag to your rule and set <type> to LAZY, IMMEDIATE, or EAGER.
In the same example rule, the immediate propagation annotation enables the rule to be evaluated only when a String that satisfies the query is inserted before the Integer, as expected:
query Q (Integer i)
String( this == i.toString() )
end
rule "Rule" @Propagation(IMMEDIATE)
when
$i : Integer()
?Q( $i; )
then
System.out.println( $i );
endAgenda evaluation filters
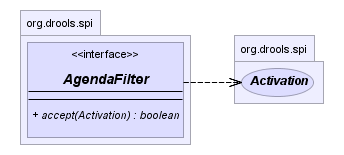
The Drools rule engine supports an AgendaFilter object in the filter interface that you can use to allow or deny the evaluation of specified rules during agenda evaluation. You can specify an agenda filter as part of a fireAllRules() call.
The following example code permits only rules ending with the string "Test" to be evaluated and executed. All other rules are filtered out of the Drools rule engine agenda.
ksession.fireAllRules( new RuleNameEndsWithAgendaFilter( "Test" ) );Phreak rule algorithm in the Drools rule engine
The Drools rule engine in Drools uses the Phreak algorithm for rule evaluation. Phreak evolved from the Rete algorithm, including the enhanced Rete algorithm ReteOO that was introduced in previous versions of Drools for object-oriented systems. Overall, Phreak is more scalable than Rete and ReteOO, and is faster in large systems.
While Rete is considered eager (immediate rule evaluation) and data oriented, Phreak is considered lazy (delayed rule evaluation) and goal oriented. The Rete algorithm performs many actions during the insert, update, and delete actions in order to find partial matches for all rules. This eagerness of the Rete algorithm during rule matching requires a lot of time before eventually executing rules, especially in large systems. With Phreak, this partial matching of rules is delayed deliberately to handle large amounts of data more efficiently.
The Phreak algorithm adds the following set of enhancements to previous Rete algorithms:
-
Three layers of contextual memory: Node, segment, and rule memory types
-
Rule-based, segment-based, and node-based linking
-
Lazy (delayed) rule evaluation
-
Stack-based evaluations with pause and resume
-
Isolated rule evaluation
-
Set-oriented propagations
Rule evaluation in Phreak
When the Drools rule engine starts, all rules are considered to be unlinked from pattern-matching data that can trigger the rules. At this stage, the Phreak algorithm in the Drools rule engine does not evaluate the rules. The insert, update, and delete actions are queued, and Phreak uses a heuristic, based on the rule most likely to result in execution, to calculate and select the next rule for evaluation. When all the required input values are populated for a rule, the rule is considered to be linked to the relevant pattern-matching data. Phreak then creates a goal that represents this rule and places the goal into a priority queue that is ordered by rule salience. Only the rule for which the goal was created is evaluated, and other potential rule evaluations are delayed. While individual rules are evaluated, node sharing is still achieved through the process of segmentation.
Unlike the tuple-oriented Rete, the Phreak propagation is collection oriented. For the rule that is being evaluated, the Drools rule engine accesses the first node and processes all queued insert, update, and delete actions. The results are added to a set, and the set is propagated to the child node. In the child node, all queued insert, update, and delete actions are processed, adding the results to the same set. The set is then propagated to the next child node and the same process repeats until it reaches the terminal node. This cycle creates a batch process effect that can provide performance advantages for certain rule constructs.
The linking and unlinking of rules happens through a layered bit-mask system, based on network segmentation. When the rule network is built, segments are created for rule network nodes that are shared by the same set of rules. A rule is composed of a path of segments. In case a rule does not share any node with any other rule, it becomes a single segment.
A bit-mask offset is assigned to each node in the segment. Another bit mask is assigned to each segment in the path of the rule according to these requirements:
-
If at least one input for a node exists, the node bit is set to the
onstate. -
If each node in a segment has the bit set to the
onstate, the segment bit is also set to theonstate. -
If any node bit is set to the
offstate, the segment is also set to theoffstate. -
If each segment in the path of the rule is set to the
onstate, the rule is considered linked, and a goal is created to schedule the rule for evaluation.
The same bit-mask technique is used to track modified nodes, segments, and rules. This tracking ability enables an already linked rule to be unscheduled from evaluation if it has been modified since the evaluation goal for it was created. As a result, no rules can ever evaluate partial matches.
This process of rule evaluation is possible in Phreak because, as opposed to a single unit of memory in Rete, Phreak has three layers of contextual memory with node, segment, and rule memory types. This layering enables much more contextual understanding during the evaluation of a rule.
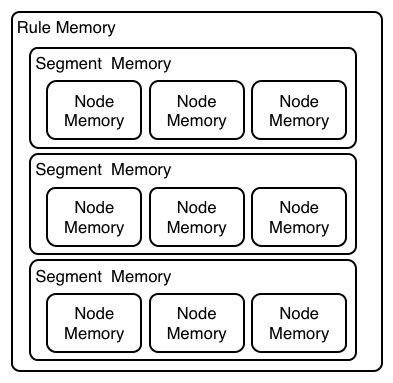
The following examples illustrate how rules are organized and evaluated in this three-layered memory system in Phreak.
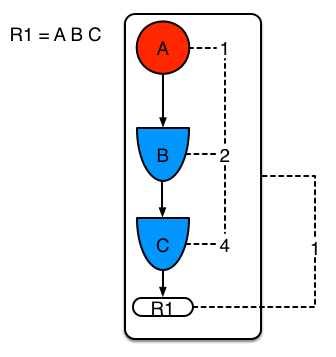
Example 1: A single rule (R1) with three patterns: A, B and C. The rule forms a single segment, with bits 1, 2, and 4 for the nodes. The single segment has a bit offset of 1.
Example 2: Rule R2 is added and shares pattern A.
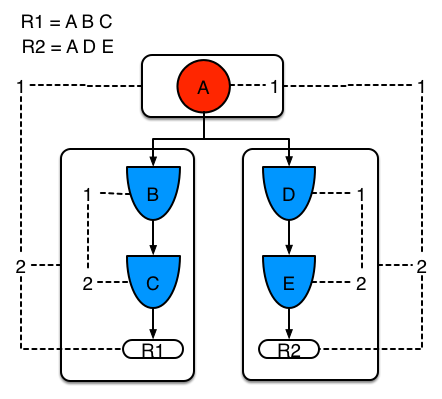
Pattern A is placed in its own segment, resulting in two segments for each rule. Those two segments form a path for their respective rules. The first segment is shared by both paths. When pattern A is linked, the segment becomes linked. The segment then iterates over each path that the segment is shared by, setting the bit 1 to on. If patterns B and C are later turned on, the second segment for path R1 is linked, and this causes bit 2 to be turned on for R1. With bit 1 and bit 2 turned on for R1, the rule is now linked and a goal is created to schedule the rule for later evaluation and execution.
When a rule is evaluated, the segments enable the results of the matching to be shared. Each segment has a staging memory to queue all inserts, updates, and deletes for that segment. When R1 is evaluated, the rule processes pattern A, and this results in a set of tuples. The algorithm detects a segmentation split, creates peered tuples for each insert, update, and delete in the set, and adds them to the R2 staging memory. Those tuples are then merged with any existing staged tuples and are executed when R2 is eventually evaluated.
Example 3: Rules R3 and R4 are added and share patterns A and B.
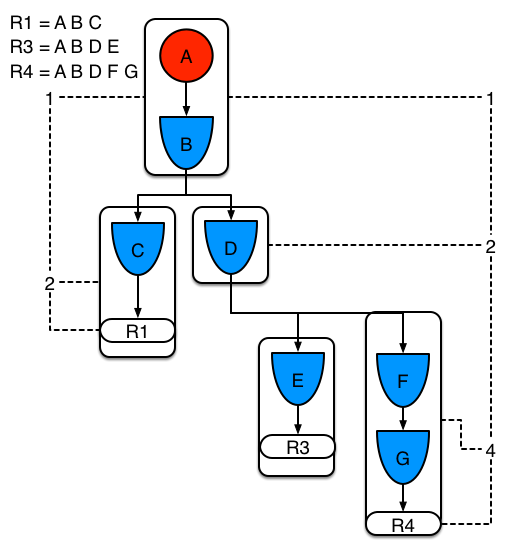
Rules R3 and R4 have three segments and R1 has two segments. Patterns A and B are shared by R1, R3, and R4, while pattern D is shared by R3 and R4.
Example 4: A single rule (R1) with a subnetwork and no pattern sharing.
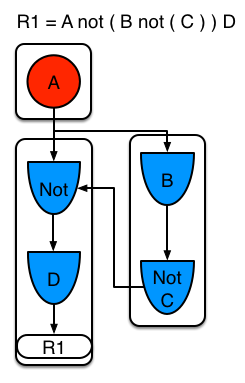
Subnetworks are formed when a Not, Exists, or Accumulate node contains more than one element. In this example, the element B not( C ) forms the subnetwork. The element not( C ) is a single element that does not require a subnetwork and is therefore merged inside of the Not node. The subnetwork uses a dedicated segment. Rule R1 still has a path of two segments and the subnetwork forms another inner path. When the subnetwork is linked, it is also linked in the outer segment.
Example 5: Rule R1 with a subnetwork that is shared by rule R2.
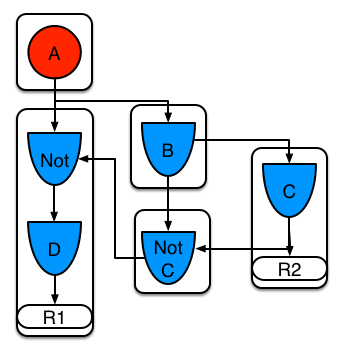
The subnetwork nodes in a rule can be shared by another rule that does not have a subnetwork. This sharing causes the subnetwork segment to be split into two segments.
Constrained Not nodes and Accumulate nodes can never unlink a segment, and are always considered to have their bits turned on.
The Phreak evaluation algorithm is stack based instead of method-recursion based. Rule evaluation can be paused and resumed at any time when a StackEntry is used to represent the node currently being evaluated.
When a rule evaluation reaches a subnetwork, a StackEntry object is created for the outer path segment and the subnetwork segment. The subnetwork segment is evaluated first, and when the set reaches the end of the subnetwork path, the segment is merged into a staging list for the outer node that the segment feeds into. The previous StackEntry object is then resumed and can now process the results of the subnetwork. This process has the added benefit, especially for Accumulate nodes, that all work is completed in a batch, before propagating to the child node.
The same stack system is used for efficient backward chaining. When a rule evaluation reaches a query node, the evaluation is paused and the query is added to the stack. The query is then evaluated to produce a result set, which is saved in a memory location for the resumed StackEntry object to pick up and propagate to the child node. If the query itself called other queries, the process repeats, while the current query is paused and a new evaluation is set up for the current query node.
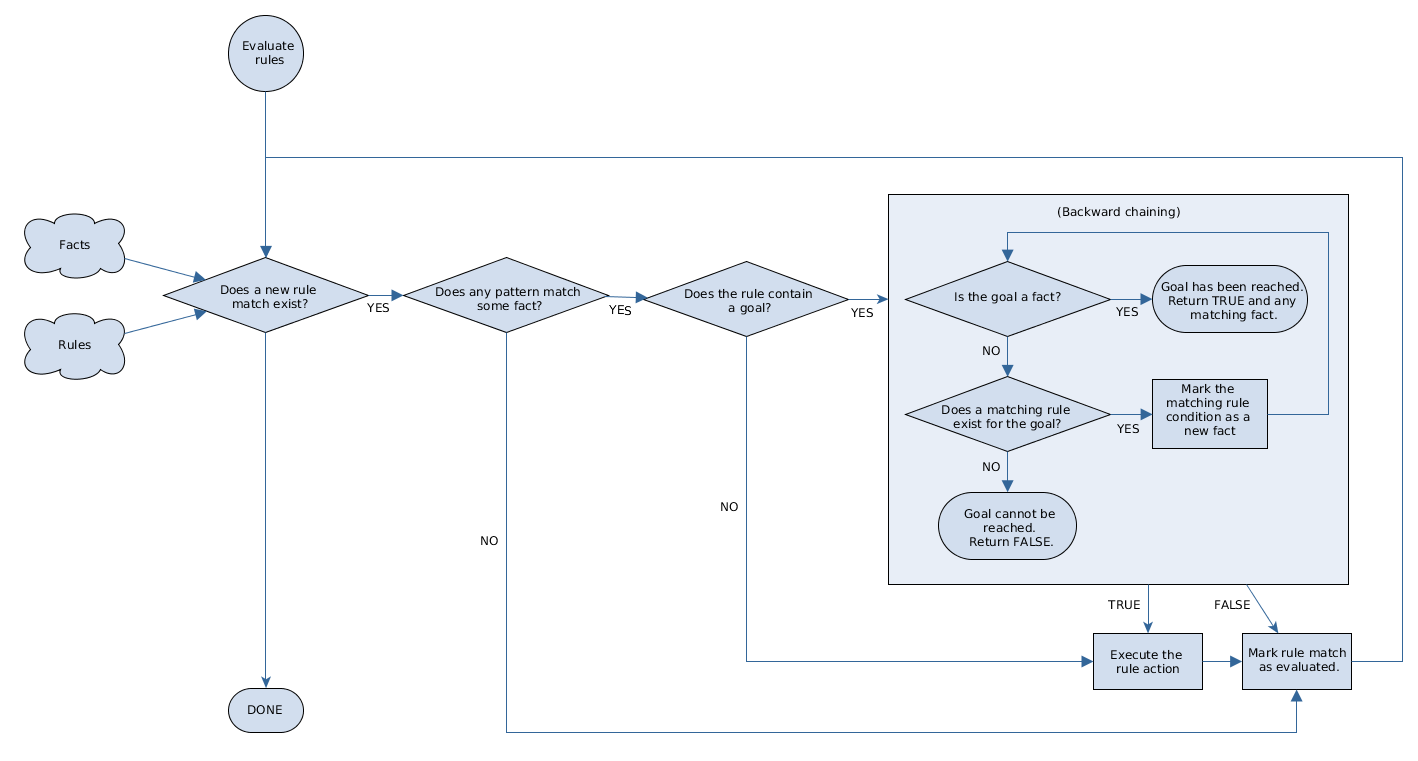
Rule evaluation with forward and backward chaining
The Drools rule engine in Drools is a hybrid reasoning system that uses both forward chaining and backward chaining to evaluate rules. A forward-chaining rule system is a data-driven system that starts with a fact in the working memory of the Drools rule engine and reacts to changes to that fact. When objects are inserted into working memory, any rule conditions that become true as a result of the change are scheduled for execution by the agenda.
In contrast, a backward-chaining rule system is a goal-driven system that starts with a conclusion that the Drools rule engine attempts to satisfy, often using recursion. If the system cannot reach the conclusion or goal, it searches for subgoals, which are conclusions that complete part of the current goal. The system continues this process until either the initial conclusion is satisfied or all subgoals are satisfied.
The following diagram illustrates how the Drools rule engine evaluates rules using forward chaining overall with a backward-chaining segment in the logic flow:
Rule base configuration
Drools contains a RuleBaseConfiguration.java object that you can use to configure exception handler settings, multithreaded execution, and sequential mode in the Drools rule engine.
For the rule base configuration options, see the Drools RuleBaseConfiguration.java page in GitHub.
The following rule base configuration options are available for the Drools rule engine:
- drools.consequenceExceptionHandler
-
When configured, this system property defines the class that manages the exceptions thrown by rule consequences. You can use this property to specify a custom exception handler for rule evaluation in the Drools rule engine.
Default value:
org.drools.core.runtime.rule.impl.DefaultConsequenceExceptionHandlerYou can specify the custom exception handler using one of the following options:
-
Specify the exception handler in a system property:
drools.consequenceExceptionHandler=org.drools.core.runtime.rule.impl.MyCustomConsequenceExceptionHandler -
Specify the exception handler while creating the KIE base programmatically:
KieServices ks = KieServices.Factory.get(); KieBaseConfiguration kieBaseConf = ks.newKieBaseConfiguration(); kieBaseConf.setOption(ConsequenceExceptionHandlerOption.get(MyCustomConsequenceExceptionHandler.class)); KieBase kieBase = kieContainer.newKieBase(kieBaseConf);
-
- drools.multithreadEvaluation
-
When enabled, this system property enables the Drools rule engine to evaluate rules in parallel by dividing the Phreak rule network into independent partitions. You can use this property to increase the speed of rule evaluation for specific rule bases.
Default value:
falseYou can enable multithreaded evaluation using one of the following options:
-
Enable the multithreaded evaluation system property:
drools.multithreadEvaluation=true -
Enable multithreaded evaluation while creating the KIE base programmatically:
KieServices ks = KieServices.Factory.get(); KieBaseConfiguration kieBaseConf = ks.newKieBaseConfiguration(); kieBaseConf.setOption(MultithreadEvaluationOption.YES); KieBase kieBase = kieContainer.newKieBase(kieBaseConf);
Rules that use queries, salience, or agenda groups are currently not supported by the parallel Drools rule engine. If these rule elements are present in the KIE base, the compiler emits a warning and automatically switches back to single-threaded evaluation. However, in some cases, the Drools rule engine might not detect the unsupported rule elements and rules might be evaluated incorrectly. For example, the Drools rule engine might not detect when rules rely on implicit salience given by rule ordering inside the DRL file, resulting in incorrect evaluation due to the unsupported salience attribute.
-
- drools.sequential
-
When enabled, this system property enables sequential mode in the Drools rule engine. In sequential mode, the Drools rule engine evaluates rules one time in the order that they are listed in the Drools rule engine agenda without regard to changes in the working memory. This means that the Drools rule engine ignores any
insert,modify, orupdatestatements in rules and executes rules in a single sequence. As a result, rule execution may be faster in sequential mode, but important updates may not be applied to your rules. You can use this property if you use stateless KIE sessions and you do not want the execution of rules to influence subsequent rules in the agenda. Sequential mode applies to stateless KIE sessions only.Default value:
falseYou can enable sequential mode using one of the following options:
-
Enable the sequential mode system property:
drools.sequential=true -
Enable sequential mode while creating the KIE base programmatically:
KieServices ks = KieServices.Factory.get(); KieBaseConfiguration kieBaseConf = ks.newKieBaseConfiguration(); kieBaseConf.setOption(SequentialOption.YES); KieBase kieBase = kieContainer.newKieBase(kieBaseConf); -
Enable sequential mode in the KIE module descriptor file (
kmodule.xml) for a specific Drools project:<kmodule> ... <kbase name="KBase2" default="false" sequential="true" packages="org.domain.pkg2, org.domain.pkg3" includes="KBase1"> ... </kbase> ... </kmodule>
-
Sequential mode in Phreak
Sequential mode is an advanced rule base configuration in the Drools rule engine, supported by Phreak, that enables the Drools rule engine to evaluate rules one time in the order that they are listed in the Drools rule engine agenda without regard to changes in the working memory. In sequential mode, the Drools rule engine ignores any insert, modify, or update statements in rules and executes rules in a single sequence. As a result, rule execution may be faster in sequential mode, but important updates may not be applied to your rules.
Sequential mode applies to only stateless KIE sessions because stateful KIE sessions inherently use data from previously invoked KIE sessions. If you use a stateless KIE session and you want the execution of rules to influence subsequent rules in the agenda, then do not enable sequential mode. Sequential mode is disabled by default in the Drools rule engine.
To enable sequential mode, use one of the following options:
-
Set the system property
drools.sequentialtotrue. -
Enable sequential mode while creating the KIE base programmatically:
KieServices ks = KieServices.Factory.get(); KieBaseConfiguration kieBaseConf = ks.newKieBaseConfiguration(); kieBaseConf.setOption(SequentialOption.YES); KieBase kieBase = kieContainer.newKieBase(kieBaseConf); -
Enable sequential mode in the KIE module descriptor file (
kmodule.xml) for a specific Drools project:<kmodule> ... <kbase name="KBase2" default="false" sequential="true" packages="org.domain.pkg2, org.domain.pkg3" includes="KBase1"> ... </kbase> ... </kmodule>
To configure sequential mode to use a dynamic agenda, use one of the following options:
-
Set the system property
drools.sequential.agendatodynamic. -
Set the sequential agenda option while creating the KIE base programmatically:
KieServices ks = KieServices.Factory.get(); KieBaseConfiguration kieBaseConf = ks.newKieBaseConfiguration(); kieBaseConf.setOption(SequentialAgendaOption.DYNAMIC); KieBase kieBase = kieContainer.newKieBase(kieBaseConf);
When you enable sequential mode, the Drools rule engine evaluates rules in the following way:
-
Rules are ordered by salience and position in the rule set.
-
An element for each possible rule match is created. The element position indicates the execution order.
-
Node memory is disabled, with the exception of the right-input object memory.
-
The left-input adapter node propagation is disconnected and the object with the node is referenced in a
Commandobject. TheCommandobject is added to a list in the working memory for later execution. -
All objects are asserted, and then the list of
Commandobjects is checked and executed. -
All matches that result from executing the list are added to elements based on the sequence number of the rule.
-
The elements that contain matches are executed in a sequence. If you set a maximum number of rule executions, the Drools rule engine activates no more than that number of rules in the agenda for execution.
In sequential mode, the LeftInputAdapterNode node creates a Command object and adds it to a list in the working memory of the Drools rule engine. This Command object contains references to the LeftInputAdapterNode node and the propagated object. These references stop any left-input propagations at insertion time so that the right-input propagation never needs to attempt to join the left inputs. The references also avoid the need for the left-input memory.
All nodes have their memory turned off, including the left-input tuple memory, but excluding the right-input object memory. After all the assertions are finished and the right-input memory of all the objects is populated, the Drools rule engine iterates over the list of LeftInputAdatperNode Command objects. The objects propagate down the network, attempting to join the right-input objects, but they are not retained in the left input.
The agenda with a priority queue to schedule the tuples is replaced by an element for each rule. The sequence number of the RuleTerminalNode node indicates the element where to place the match. After all Command objects have finished, the elements are checked and existing matches are executed. To improve performance, the first and the last populated cell in the elements are retained.
When the network is constructed, each RuleTerminalNode node receives a sequence number based on its salience number and the order in which it was added to the network.
The right-input node memories are typically hash maps for fast object deletion. Because object deletions are not supported, Phreak uses an object list when the values of the object are not indexed. For a large number of objects, indexed hash maps provide a performance increase. If an object has only a few instances, Phreak uses an object list instead of an index.
Complex event processing (CEP)
In Drools, an event is a record of a significant change of state in the application domain at a point in time. Depending on how the domain is modeled, the change of state may be represented by a single event, multiple atomic events, or hierarchies of correlated events. From a complex event processing (CEP) perspective, an event is a type of fact or object that occurs at a specific point in time, and a business rule is a definition of how to react to the data from that fact or object. For example, in a stock broker application, a change in security prices, a change in ownership from seller to buyer, or a change in an account holder’s balance are all considered to be events because a change has occurred in the state of the application domain at a given time.
The Drools rule engine in Drools uses complex event processing (CEP) to detect and process multiple events within a collection of events, to uncover relationships that exist between events, and to infer new data from the events and their relationships.
CEP use cases share several requirements and goals with business rule use cases.
From a business perspective, business rule definitions are often defined based on the occurrence of scenarios triggered by events. In the following examples, events form the basis of business rules:
-
In an algorithmic trading application, a rule performs an action if the security price increases by X percent above the day opening price. The price increases are denoted by events on a stock trading application.
-
In a monitoring application, a rule performs an action if the temperature in the server room increases X degrees in Y minutes. The sensor readings are denoted by events.
From a technical perspective, business rule evaluation and CEP have the following key similarities:
-
Both business rule evaluation and CEP require seamless integration with the enterprise infrastructure and applications. This is particularly important with life-cycle management, auditing, and security.
-
Both business rule evaluation and CEP have functional requirements such as pattern matching, and non-functional requirements such as response time limits and query-rule explanations.
CEP scenarios have the following key characteristics:
-
Scenarios usually process large numbers of events, but only a small percentage of the events are relevant.
-
Events are usually immutable and represent a record of change in state.
-
Rules and queries run against events and must react to detected event patterns.
-
Related events usually have a strong temporal relationship.
-
Individual events are not prioritized. The CEP system prioritizes patterns of related events and the relationships between them.
-
Events usually need to be composed and aggregated.
Given these common CEP scenario characteristics, the CEP system in Drools supports the following features and functions to optimize event processing:
-
Event processing with proper semantics
-
Event detection, correlation, aggregation, and composition
-
Event stream processing
-
Temporal constraints to model the temporal relationships between events
-
Sliding windows of significant events
-
Session-scoped unified clock
-
Required volumes of events for CEP use cases
-
Reactive rules
-
Adapters for event input into the Drools rule engine (pipeline)
Events in complex event processing
In Drools, an event is a record of a significant change of state in the application domain at a point in time. Depending on how the domain is modeled, the change of state may be represented by a single event, multiple atomic events, or hierarchies of correlated events. From a complex event processing (CEP) perspective, an event is a type of fact or object that occurs at a specific point in time, and a business rule is a definition of how to react to the data from that fact or object. For example, in a stock broker application, a change in security prices, a change in ownership from seller to buyer, or a change in an account holder’s balance are all considered to be events because a change has occurred in the state of the application domain at a given time.
Events have the following key characteristics:
-
Are immutable: An event is a record of change that has occurred at some time in the past and cannot be changed.
The Drools rule engine does not enforce immutability on the Java objects that represent events. This behavior makes event data enrichment possible. Your application should be able to populate unpopulated event attributes, and these attributes are used by the Drools rule engine to enrich the event with inferred data. However, you should not change event attributes that have already been populated.
-
Have strong temporal constraints: Rules involving events usually require the correlation of multiple events that occur at different points in time relative to each other.
-
Have managed life cycles: Because events are immutable and have temporal constraints, they are usually only relevant for a specified period of time. This means that the Drools rule engine can automatically manage the life cycle of events.
-
Can use sliding windows: You can define sliding windows of time or length with events. A sliding time window is a specified period of time during which events can be processed. A sliding length window is a specified number of events that can be processed.
Declaring facts as events
You can declare facts as events in your Java class or DRL rule file so that the Drools rule engine handles the facts as events during complex event processing. You can declare the facts as interval-based events or point-in-time events. Interval-based events have a duration time and persist in the working memory of the Drools rule engine until their duration time has lapsed. Point-in-time events have no duration and are essentially interval-based events with a duration of zero.
For the relevant fact type in your Java class or DRL rule file, enter the @role( event ) metadata tag and parameter. The @role metadata tag accepts the following two values:
-
fact: (Default) Declares the type as a regular fact -
event: Declares the type as an event
For example, the following snippet declares that the StockPoint fact type in a stock broker application must be handled as an event:
import some.package.StockPoint
declare StockPoint
@role( event )
endIf StockPoint is a fact type declared in the DRL rule file instead of in a pre-existing class, you can declare the event in-line in your application code:
declare StockPoint
@role( event )
datetime : java.util.Date
symbol : String
price : double
endEvent processing modes in the Drools rule engine
The Drools rule engine runs in either cloud mode or stream mode. In cloud mode, the Drools rule engine processes facts as facts with no temporal constraints, independent of time, and in no particular order. In stream mode, the Drools rule engine processes facts as events with strong temporal constraints, in real time or near real time. Stream mode uses synchronization to make event processing possible in Drools.
- Cloud mode
-
Cloud mode is the default operating mode of the Drools rule engine. In cloud mode, the Drools rule engine treats events as an unordered cloud. Events still have time stamps, but the Drools rule engine running in cloud mode cannot draw relevance from the time stamp because cloud mode ignores the present time. This mode uses the rule constraints to find the matching tuples to activate and execute rules.
Cloud mode does not impose any kind of additional requirements on facts. However, because the Drools rule engine in this mode has no concept of time, it cannot use temporal features such as sliding windows or automatic life-cycle management. In cloud mode, events must be explicitly retracted when they are no longer needed.
The following requirements are not imposed in cloud mode:
-
No clock synchronization because the Drools rule engine has no notion of time
-
No ordering of events because the Drools rule engine processes events as an unordered cloud, against which the Drools rule engine match rules
You can specify cloud mode either by setting the system property in the relevant configuration files or by using the Java client API:
Set cloud mode using system propertydrools.eventProcessingMode=cloudSet cloud mode using Java client APIimport org.kie.api.conf.EventProcessingOption; import org.kie.api.KieBaseConfiguration; import org.kie.api.KieServices.Factory; KieBaseConfiguration config = KieServices.Factory.get().newKieBaseConfiguration(); config.setOption(EventProcessingOption.CLOUD);You can also specify cloud mode using the
eventProcessingMode="<mode>"KIE base attribute in the KIE module descriptor file (kmodule.xml) for a specific Drools project:Set cloud mode using projectkmodule.xmlfile<kmodule> ... <kbase name="KBase2" default="false" eventProcessingMode="cloud" packages="org.domain.pkg2, org.domain.pkg3" includes="KBase1"> ... </kbase> ... </kmodule> -
- Stream mode
-
Stream mode enables the Drools rule engine to process events chronologically and in real time as they are inserted into the Drools rule engine. In stream mode, the Drools rule engine synchronizes streams of events (so that events in different streams can be processed in chronological order), implements sliding windows of time or length, and enables automatic life-cycle management.
The following requirements apply to stream mode:
-
Events in each stream must be ordered chronologically.
-
A session clock must be present to synchronize event streams.
Your application does not need to enforce ordering events between streams, but using event streams that have not been synchronized may cause unexpected results. You can specify stream mode either by setting the system property in the relevant configuration files or by using the Java client API:
Set stream mode using system propertydrools.eventProcessingMode=streamSet stream mode using Java client APIimport org.kie.api.conf.EventProcessingOption; import org.kie.api.KieBaseConfiguration; import org.kie.api.KieServices.Factory; KieBaseConfiguration config = KieServices.Factory.get().newKieBaseConfiguration(); config.setOption(EventProcessingOption.STREAM);You can also specify stream mode using the
eventProcessingMode="<mode>"KIE base attribute in the KIE module descriptor file (kmodule.xml) for a specific Drools project:Set stream mode using projectkmodule.xmlfile<kmodule> ... <kbase name="KBase2" default="false" eventProcessingMode="stream" packages="org.domain.pkg2, org.domain.pkg3" includes="KBase1"> ... </kbase> ... </kmodule> -
Negative patterns in Drools rule engine stream mode
A negative pattern is a pattern for conditions that are not met. For example, the following DRL rule activates a fire alarm if a fire is detected and the sprinkler is not activated:
rule "Sound the alarm"
when
$f : FireDetected()
not(SprinklerActivated())
then
// Sound the alarm.
endIn cloud mode, the Drools rule engine assumes all facts (regular facts and events) are known in advance and evaluates negative patterns immediately. In stream mode, the Drools rule engine can support temporal constraints on facts to wait for a set time before activating a rule.
The same example rule in stream mode activates the fire alarm as usual, but applies a 10-second delay.
rule "Sound the alarm"
when
$f : FireDetected()
not(SprinklerActivated(this after[0s,10s] $f))
then
// Sound the alarm.
endThe following modified fire alarm rule expects one Heartbeat event to occur every 10 seconds. If the expected event does not occur, the rule is executed. This rule uses the same type of object in both the first pattern and in the negative pattern. The negative pattern has the temporal constraint to wait 0 to 10 seconds before executing and excludes the Heartbeat event bound to $h so that the rule can be executed. The bound event $h must be explicitly excluded in order for the rule to be executed because the temporal constraint [0s, …] does not inherently exclude that event from being matched again.
rule "Sound the alarm"
when
$h: Heartbeat() from entry-point "MonitoringStream"
not(Heartbeat(this != $h, this after[0s,10s] $h) from entry-point "MonitoringStream")
then
// Sound the alarm.
endProperty-change settings and listeners for fact types
By default, the Drools rule engine does not re-evaluate all fact patterns for fact types each time a rule is triggered, but instead reacts only to modified properties that are constrained or bound inside a given pattern. For example, if a rule calls modify() as part of the rule actions but the action does not generate new data in the KIE base, the Drools rule engine does not automatically re-evaluate all fact patterns because no data was modified. This property reactivity behavior prevents unwanted recursions in the KIE base and results in more efficient rule evaluation. This behavior also means that you do not always need to use the no-loop rule attribute to avoid infinite recursion.
You can modify or disable this property reactivity behavior with the following KnowledgeBuilderConfiguration options, and then use a property-change setting in your Java class or DRL files to fine-tune property reactivity as needed:
-
ALWAYS: (Default) All types are property reactive, but you can disable property reactivity for a specific type by using the@classReactiveproperty-change setting. -
ALLOWED: No types are property reactive, but you can enable property reactivity for a specific type by using the@propertyReactiveproperty-change setting. -
DISABLED: No types are property reactive. All property-change listeners are ignored.
KnowledgeBuilderConfiguration config = KnowledgeBuilderFactory.newKnowledgeBuilderConfiguration();
config.setOption(PropertySpecificOption.ALLOWED);
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory.newKnowledgeBuilder(config);Alternatively, you can update the drools.propertySpecific system property in the standalone.xml file of your Drools distribution:
<system-properties>
...
<property name="drools.propertySpecific" value="ALLOWED"/>
...
</system-properties>The Drools rule engine supports the following property-change settings and listeners for fact classes or declared DRL fact types:
- @classReactive
-
If property reactivity is set to
ALWAYSin the Drools rule engine (all types are property reactive), this tag disables the default property reactivity behavior for a specific Java class or a declared DRL fact type. You can use this tag if you want the Drools rule engine to re-evaluate all fact patterns for the specified fact type each time the rule is triggered, instead of reacting only to modified properties that are constrained or bound inside a given pattern.Example: Disable default property reactivity in a DRL type declarationdeclare Person @classReactive firstName : String lastName : String endExample: Disable default property reactivity in a Java class@classReactive public static class Person { private String firstName; private String lastName; } - @propertyReactive
-
If property reactivity is set to
ALLOWEDin the Drools rule engine (no types are property reactive unless specified), this tag enables property reactivity for a specific Java class or a declared DRL fact type. You can use this tag if you want the Drools rule engine to react only to modified properties that are constrained or bound inside a given pattern for the specified fact type, instead of re-evaluating all fact patterns for the fact each time the rule is triggered.Example: Enable property reactivity in a DRL type declaration (when reactivity is disabled globally)declare Person @propertyReactive firstName : String lastName : String endExample: Enable property reactivity in a Java class (when reactivity is disabled globally)@propertyReactive public static class Person { private String firstName; private String lastName; } - @watch
-
This tag enables property reactivity for additional properties that you specify in-line in fact patterns in DRL rules. This tag is supported only if property reactivity is set to
ALWAYSin the Drools rule engine, or if property reactivity is set toALLOWEDand the relevant fact type uses the@propertyReactivetag. You can use this tag in DRL rules to add or exclude specific properties in fact property reactivity logic.Default parameter: None
Supported parameters: Property name,
*(all),!(not),!*(no properties)<factPattern> @watch ( <property> )Example: Enable or disable property reactivity in fact patterns// Listens for changes in both `firstName` (inferred) and `lastName`: Person(firstName == $expectedFirstName) @watch( lastName ) // Listens for changes in all properties of the `Person` fact: Person(firstName == $expectedFirstName) @watch( * ) // Listens for changes in `lastName` and explicitly excludes changes in `firstName`: Person(firstName == $expectedFirstName) @watch( lastName, !firstName ) // Listens for changes in all properties of the `Person` fact except `age`: Person(firstName == $expectedFirstName) @watch( *, !age ) // Excludes changes in all properties of the `Person` fact (equivalent to using `@classReactivity` tag): Person(firstName == $expectedFirstName) @watch( !* )The Drools rule engine generates a compilation error if you use the
@watchtag for properties in a fact type that uses the@classReactivetag (disables property reactivity) or when property reactivity is set toALLOWEDin the Drools rule engine and the relevant fact type does not use the@propertyReactivetag. Compilation errors also arise if you duplicate properties in listener annotations, such as@watch( firstName, ! firstName ). - @propertyChangeSupport
-
For facts that implement support for property changes as defined in the JavaBeans Specification, this tag enables the Drools rule engine to monitor changes in the fact properties.
Example: Declare property change support in JavaBeans objectdeclare Person @propertyChangeSupport end
Temporal operators for events
In stream mode, the Drools rule engine supports the following temporal operators for events that are inserted into the working memory of the Drools rule engine. You can use these operators to define the temporal reasoning behavior of the events that you declare in your Java class or DRL rule file. Temporal operators are not supported when the Drools rule engine is running in cloud mode.
-
after -
before -
coincides -
during -
includes -
finishes -
finished by -
meets -
met by -
overlaps -
overlapped by -
starts -
started by- after
-
This operator specifies if the current event occurs after the correlated event. This operator can also define an amount of time after which the current event can follow the correlated event, or a delimiting time range during which the current event can follow the correlated event.
For example, the following pattern matches if
$eventAstarts between 3 minutes and 30 seconds and 4 minutes after$eventBfinishes. If$eventAstarts earlier than 3 minutes and 30 seconds after$eventBfinishes, or later than 4 minutes after$eventBfinishes, then the pattern is not matched.$eventA : EventA(this after[3m30s, 4m] $eventB)You can also express this operator in the following way:
3m30s <= $eventA.startTimestamp - $eventB.endTimeStamp <= 4mThe
afteroperator supports up to two parameter values:-
If two values are defined, the interval starts on the first value (3 minutes and 30 seconds in the example) and ends on the second value (4 minutes in the example).
-
If only one value is defined, the interval starts on the provided value and runs indefinitely with no end time.
-
If no value is defined, the interval starts at 1 millisecond and runs indefinitely with no end time.
The
afteroperator also supports negative time ranges:$eventA : EventA(this after[-3m30s, -2m] $eventB)If the first value is greater than the second value, the Drools rule engine automatically reverses them. For example, the following two patterns are interpreted by the Drools rule engine in the same way:
$eventA : EventA(this after[-3m30s, -2m] $eventB) $eventA : EventA(this after[-2m, -3m30s] $eventB) -
- before
-
This operator specifies if the current event occurs before the correlated event. This operator can also define an amount of time before which the current event can precede the correlated event, or a delimiting time range during which the current event can precede the correlated event.
For example, the following pattern matches if
$eventAfinishes between 3 minutes and 30 seconds and 4 minutes before$eventBstarts. If$eventAfinishes earlier than 3 minutes and 30 seconds before$eventBstarts, or later than 4 minutes before$eventBstarts, then the pattern is not matched.$eventA : EventA(this before[3m30s, 4m] $eventB)You can also express this operator in the following way:
3m30s <= $eventB.startTimestamp - $eventA.endTimeStamp <= 4mThe
beforeoperator supports up to two parameter values:-
If two values are defined, the interval starts on the first value (3 minutes and 30 seconds in the example) and ends on the second value (4 minutes in the example).
-
If only one value is defined, the interval starts on the provided value and runs indefinitely with no end time.
-
If no value is defined, the interval starts at 1 millisecond and runs indefinitely with no end time.
The
beforeoperator also supports negative time ranges:$eventA : EventA(this before[-3m30s, -2m] $eventB)If the first value is greater than the second value, the Drools rule engine automatically reverses them. For example, the following two patterns are interpreted by the Drools rule engine in the same way:
$eventA : EventA(this before[-3m30s, -2m] $eventB) $eventA : EventA(this before[-2m, -3m30s] $eventB) -
- coincides
-
This operator specifies if the two events occur at the same time, with the same start and end times.
For example, the following pattern matches if both the start and end time stamps of
$eventAand$eventBare identical:$eventA : EventA(this coincides $eventB)The
coincidesoperator supports up to two parameter values for the distance between the event start and end times, if they are not identical:-
If only one parameter is given, the parameter is used to set the threshold for both the start and end times of both events.
-
If two parameters are given, the first is used as a threshold for the start time and the second is used as a threshold for the end time.
The following pattern uses start and end time thresholds:
$eventA : EventA(this coincides[15s, 10s] $eventB)The pattern matches if the following conditions are met:
abs($eventA.startTimestamp - $eventB.startTimestamp) <= 15s && abs($eventA.endTimestamp - $eventB.endTimestamp) <= 10sThe Drools rule engine does not support negative intervals for the coincidesoperator. If you use negative intervals, the Drools rule engine generates an error. -
- during
-
This operator specifies if the current event occurs within the time frame of when the correlated event starts and ends. The current event must start after the correlated event starts and must end before the correlated event ends. (With the
coincidesoperator, the start and end times are the same or nearly the same.)For example, the following pattern matches if
$eventAstarts after$eventBstarts and ends before$eventBends:$eventA : EventA(this during $eventB)You can also express this operator in the following way:
$eventB.startTimestamp < $eventA.startTimestamp <= $eventA.endTimestamp < $eventB.endTimestampThe
duringoperator supports one, two, or four optional parameters:-
If one value is defined, this value is the maximum distance between the start times of the two events and the maximum distance between the end times of the two events.
-
If two values are defined, these values are a threshold between which the current event start time and end time must occur in relation to the correlated event start and end times.
For example, if the values are
5sand10s, the current event must start between 5 and 10 seconds after the correlated event starts and must end between 5 and 10 seconds before the correlated event ends. -
If four values are defined, the first and second values are the minimum and maximum distances between the start times of the events, and the third and fourth values are the minimum and maximum distances between the end times of the two events.
-
- includes
-
This operator specifies if the correlated event occurs within the time frame of when the current event occurs. The correlated event must start after the current event starts and must end before the current event ends. (The behavior of this operator is the reverse of the
duringoperator behavior.)For example, the following pattern matches if
$eventBstarts after$eventAstarts and ends before$eventAends:$eventA : EventA(this includes $eventB)You can also express this operator in the following way:
$eventA.startTimestamp < $eventB.startTimestamp <= $eventB.endTimestamp < $eventA.endTimestampThe
includesoperator supports one, two, or four optional parameters:-
If one value is defined, this value is the maximum distance between the start times of the two events and the maximum distance between the end times of the two events.
-
If two values are defined, these values are a threshold between which the correlated event start time and end time must occur in relation to the current event start and end times.
For example, if the values are
5sand10s, the correlated event must start between 5 and 10 seconds after the current event starts and must end between 5 and 10 seconds before the current event ends. -
If four values are defined, the first and second values are the minimum and maximum distances between the start times of the events, and the third and fourth values are the minimum and maximum distances between the end times of the two events.
-
- finishes
-
This operator specifies if the current event starts after the correlated event but both events end at the same time.
For example, the following pattern matches if
$eventAstarts after$eventBstarts and ends at the same time when$eventBends:$eventA : EventA(this finishes $eventB)You can also express this operator in the following way:
$eventB.startTimestamp < $eventA.startTimestamp && $eventA.endTimestamp == $eventB.endTimestampThe
finishesoperator supports one optional parameter that sets the maximum time allowed between the end times of the two events:$eventA : EventA(this finishes[5s] $eventB)This pattern matches if these conditions are met:
$eventB.startTimestamp < $eventA.startTimestamp && abs($eventA.endTimestamp - $eventB.endTimestamp) <= 5sThe Drools rule engine does not support negative intervals for the finishesoperator. If you use negative intervals, the Drools rule engine generates an error. - finished by
-
This operator specifies if the correlated event starts after the current event but both events end at the same time. (The behavior of this operator is the reverse of the
finishesoperator behavior.)For example, the following pattern matches if
$eventBstarts after$eventAstarts and ends at the same time when$eventAends:$eventA : EventA(this finishedby $eventB)You can also express this operator in the following way:
$eventA.startTimestamp < $eventB.startTimestamp && $eventA.endTimestamp == $eventB.endTimestampThe
finished byoperator supports one optional parameter that sets the maximum time allowed between the end times of the two events:$eventA : EventA(this finishedby[5s] $eventB)This pattern matches if these conditions are met:
$eventA.startTimestamp < $eventB.startTimestamp && abs($eventA.endTimestamp - $eventB.endTimestamp) <= 5sThe Drools rule engine does not support negative intervals for the finished byoperator. If you use negative intervals, the Drools rule engine generates an error. - meets
-
This operator specifies if the current event ends at the same time when the correlated event starts.
For example, the following pattern matches if
$eventAends at the same time when$eventBstarts:$eventA : EventA(this meets $eventB)You can also express this operator in the following way:
abs($eventB.startTimestamp - $eventA.endTimestamp) == 0The
meetsoperator supports one optional parameter that sets the maximum time allowed between the end time of the current event and the start time of the correlated event:$eventA : EventA(this meets[5s] $eventB)This pattern matches if these conditions are met:
abs($eventB.startTimestamp - $eventA.endTimestamp) <= 5sThe Drools rule engine does not support negative intervals for the meetsoperator. If you use negative intervals, the Drools rule engine generates an error. - met by
-
This operator specifies if the correlated event ends at the same time when the current event starts. (The behavior of this operator is the reverse of the
meetsoperator behavior.)For example, the following pattern matches if
$eventBends at the same time when$eventAstarts:$eventA : EventA(this metby $eventB)You can also express this operator in the following way:
abs($eventA.startTimestamp - $eventB.endTimestamp) == 0The
met byoperator supports one optional parameter that sets the maximum distance between the end time of the correlated event and the start time of the current event:$eventA : EventA(this metby[5s] $eventB)This pattern matches if these conditions are met:
abs($eventA.startTimestamp - $eventB.endTimestamp) <= 5sThe Drools rule engine does not support negative intervals for the met byoperator. If you use negative intervals, the Drools rule engine generates an error. - overlaps
-
This operator specifies if the current event starts before the correlated event starts and it ends during the time frame that the correlated event occurs. The current event must end between the start and end times of the correlated event.
For example, the following pattern matches if
$eventAstarts before$eventBstarts and then ends while$eventBoccurs, before$eventBends:$eventA : EventA(this overlaps $eventB)The
overlapsoperator supports up to two parameters:-
If one parameter is defined, the value is the maximum distance between the start time of the correlated event and the end time of the current event.
-
If two parameters are defined, the values are the minimum distance (first value) and the maximum distance (second value) between the start time of the correlated event and the end time of the current event.
-
- overlapped by
-
This operator specifies if the correlated event starts before the current event starts and it ends during the time frame that the current event occurs. The correlated event must end between the start and end times of the current event. (The behavior of this operator is the reverse of the
overlapsoperator behavior.)For example, the following pattern matches if
$eventBstarts before$eventAstarts and then ends while$eventAoccurs, before$eventAends:$eventA : EventA(this overlappedby $eventB)The
overlapped byoperator supports up to two parameters:-
If one parameter is defined, the value is the maximum distance between the start time of the current event and the end time of the correlated event.
-
If two parameters are defined, the values are the minimum distance (first value) and the maximum distance (second value) between the start time of the current event and the end time of the correlated event.
-
- starts
-
This operator specifies if the two events start at the same time but the current event ends before the correlated event ends.
For example, the following pattern matches if
$eventAand$eventBstart at the same time, and$eventAends before$eventBends:$eventA : EventA(this starts $eventB)You can also express this operator in the following way:
$eventA.startTimestamp == $eventB.startTimestamp && $eventA.endTimestamp < $eventB.endTimestampThe
startsoperator supports one optional parameter that sets the maximum distance between the start times of the two events:$eventA : EventA(this starts[5s] $eventB)This pattern matches if these conditions are met:
abs($eventA.startTimestamp - $eventB.startTimestamp) <= 5s && $eventA.endTimestamp < $eventB.endTimestampThe Drools rule engine does not support negative intervals for the startsoperator. If you use negative intervals, the Drools rule engine generates an error. - started by
-
This operator specifies if the two events start at the same time but the correlated event ends before the current event ends. (The behavior of this operator is the reverse of the
startsoperator behavior.)For example, the following pattern matches if
$eventAand$eventBstart at the same time, and$eventBends before$eventAends:$eventA : EventA(this startedby $eventB)You can also express this operator in the following way:
$eventA.startTimestamp == $eventB.startTimestamp && $eventA.endTimestamp > $eventB.endTimestampThe
started byoperator supports one optional parameter that sets the maximum distance between the start times of the two events:$eventA : EventA( this starts[5s] $eventB)This pattern matches if these conditions are met:
abs( $eventA.startTimestamp - $eventB.startTimestamp ) <= 5s && $eventA.endTimestamp > $eventB.endTimestampThe Drools rule engine does not support negative intervals for the started byoperator. If you use negative intervals, the Drools rule engine generates an error.
Session clock implementations in the Drools rule engine
During complex event processing, events in the Drools rule engine may have temporal constraints and therefore require a session clock that provides the current time. For example, if a rule needs to determine the average price of a given stock over the last 60 minutes, the Drools rule engine must be able to compare the stock price event time stamp with the current time in the session clock.
The Drools rule engine supports a real-time clock and a pseudo clock. You can use one or both clock types depending on the scenario:
-
Rules testing: Testing requires a controlled environment, and when the tests include rules with temporal constraints, you must be able to control the input rules and facts and the flow of time.
-
Regular execution: The Drools rule engine reacts to events in real time and therefore requires a real-time clock.
-
Special environments: Specific environments may have specific time control requirements. For example, clustered environments may require clock synchronization or Java Enterprise Edition (JEE) environments may require a clock provided by the application server.
-
Rules replay or simulation: In order to replay or simulate scenarios, the application must be able to control the flow of time.
Consider your environment requirements as you decide whether to use a real-time clock or pseudo clock in the Drools rule engine.
- Real-time clock
-
The real-time clock is the default clock implementation in the Drools rule engine and uses the system clock to determine the current time for time stamps. To configure the Drools rule engine to use the real-time clock, set the KIE session configuration parameter to
realtime:Configure real-time clock in KIE sessionimport org.kie.api.KieServices.Factory; import org.kie.api.runtime.conf.ClockTypeOption; import org.kie.api.runtime.KieSessionConfiguration; KieSessionConfiguration config = KieServices.Factory.get().newKieSessionConfiguration(); config.setOption(ClockTypeOption.get("realtime")); - Pseudo clock
-
The pseudo clock implementation in the Drools rule engine is helpful for testing temporal rules and it can be controlled by the application. To configure the Drools rule engine to use the pseudo clock, set the KIE session configuration parameter to
pseudo:Configure pseudo clock in KIE sessionimport org.kie.api.runtime.conf.ClockTypeOption; import org.kie.api.runtime.KieSessionConfiguration; import org.kie.api.KieServices.Factory; KieSessionConfiguration config = KieServices.Factory.get().newKieSessionConfiguration(); config.setOption(ClockTypeOption.get("pseudo"));You can also use additional configurations and fact handlers to control the pseudo clock:
Control pseudo clock behavior in KIE sessionimport java.util.concurrent.TimeUnit; import org.kie.api.runtime.KieSessionConfiguration; import org.kie.api.KieServices.Factory; import org.kie.api.runtime.KieSession; import org.drools.core.time.SessionPseudoClock; import org.kie.api.runtime.rule.FactHandle; import org.kie.api.runtime.conf.ClockTypeOption; KieSessionConfiguration conf = KieServices.Factory.get().newKieSessionConfiguration(); conf.setOption( ClockTypeOption.get("pseudo")); KieSession session = kbase.newKieSession(conf, null); SessionPseudoClock clock = session.getSessionClock(); // While inserting facts, advance the clock as necessary. FactHandle handle1 = session.insert(tick1); clock.advanceTime(10, TimeUnit.SECONDS); FactHandle handle2 = session.insert(tick2); clock.advanceTime(30, TimeUnit.SECONDS); FactHandle handle3 = session.insert(tick3);
Event streams and entry points
The Drools rule engine can process high volumes of events in the form of event streams. In DRL rule declarations, a stream is also known as an entry point. When you declare an entry point in a DRL rule or Java application, the Drools rule engine, at compile time, identifies and creates the proper internal structures to use data from only that entry point to evaluate that rule.
Facts from one entry point, or stream, can join facts from any other entry point in addition to facts already in the working memory of the Drools rule engine. Facts always remain associated with the entry point through which they entered the Drools rule engine. Facts of the same type can enter the Drools rule engine through several entry points, but facts that enter the Drools rule engine through entry point A can never match a pattern from entry point B.
Event streams have the following characteristics:
-
Events in the stream are ordered by time stamp. The time stamps may have different semantics for different streams, but they are always ordered internally.
-
Event streams usually have a high volume of events.
-
Atomic events in streams are usually not useful individually, only collectively in a stream.
-
Event streams can be homogeneous and contain a single type of event, or heterogeneous and contain events of different types.
Declaring entry points for rule data
You can declare an entry point (event stream) for events so that the Drools rule engine uses data from only that entry point to evaluate the rules. You can declare an entry point either implicitly by referencing it in DRL rules or explicitly in your Java application.
Use one of the following methods to declare the entry point:
-
In the DRL rule file, specify
from entry-point "<name>"for the inserted fact:Authorize withdrawal rule with "ATM Stream" entry pointrule "Authorize withdrawal" when WithdrawRequest($ai : accountId, $am : amount) from entry-point "ATM Stream" CheckingAccount(accountId == $ai, balance > $am) then // Authorize withdrawal. endApply fee rule with "Branch Stream" entry pointrule "Apply fee on withdraws on branches" when WithdrawRequest($ai : accountId, processed == true) from entry-point "Branch Stream" CheckingAccount(accountId == $ai) then // Apply a $2 fee on the account. endBoth example DRL rules from a banking application insert the event
WithdrawalRequestwith the factCheckingAccount, but from different entry points. At run time, the Drools rule engine evaluates theAuthorize withdrawalrule using data from only the"ATM Stream"entry point, and evaluates theApply feerule using data from only the"Branch Stream"entry point. Any events inserted into the"ATM Stream"can never match patterns for the"Apply fee"rule, and any events inserted into the"Branch Stream"can never match patterns for the"Authorize withdrawal rule". -
In the Java application code, use the
getEntryPoint()method to specify and obtain anEntryPointobject and insert facts into that entry point accordingly:Java application code with EntryPoint object and inserted factsimport org.kie.api.runtime.KieSession; import org.kie.api.runtime.rule.EntryPoint; // Create your KIE base and KIE session as usual. KieSession session = ... // Create a reference to the entry point. EntryPoint atmStream = session.getEntryPoint("ATM Stream"); // Start inserting your facts into the entry point. atmStream.insert(aWithdrawRequest);Any DRL rules that specify
from entry-point "ATM Stream"are then evaluated based on the data in this entry point only.
Sliding windows of time or length
In stream mode, the Drools rule engine can process events from a specified sliding window of time or length. A sliding time window is a specified period of time during which events can be processed. A sliding length window is a specified number of events that can be processed. When you declare a sliding window in a DRL rule or Java application, the Drools rule engine, at compile time, identifies and creates the proper internal structures to use data from only that sliding window to evaluate that rule.
For example, the following DRL rule snippets instruct the Drools rule engine to process only the stock points from the last 2 minutes (sliding time window) or to process only the last 10 stock points (sliding length window):
StockPoint() over window:time(2m)StockPoint() over window:length(10)Declaring sliding windows for rule data
You can declare a sliding window of time (flow of time) or length (number of occurrences) for events so that the Drools rule engine uses data from only that window to evaluate the rules.
In the DRL rule file, specify over window:<time_or_length>(<value>) for the inserted fact.
For example, the following two DRL rules activate a fire alarm based on an average temperature. However, the first rule uses a sliding time window to calculate the average over the last 10 minutes while the second rule uses a sliding length window to calculate the average over the last one hundred temperature readings.
rule "Sound the alarm if temperature rises above threshold"
when
TemperatureThreshold($max : max)
Number(doubleValue > $max) from accumulate(
SensorReading($temp : temperature) over window:time(10m),
average($temp))
then
// Sound the alarm.
endrule "Sound the alarm if temperature rises above threshold"
when
TemperatureThreshold($max : max)
Number(doubleValue > $max) from accumulate(
SensorReading($temp : temperature) over window:length(100),
average($temp))
then
// Sound the alarm.
endThe Drools rule engine discards any SensorReading events that are more than 10 minutes old or that are not part of the last one hundred readings, and continues recalculating the average as the minutes or readings "slide" forward in real time.
The Drools rule engine does not automatically remove outdated events from the KIE session because other rules without sliding window declarations might depend on those events. The Drools rule engine stores events in the KIE session until the events expire either by explicit rule declarations or by implicit reasoning within the Drools rule engine based on inferred data in the KIE base.
Memory management for events
In stream mode, the Drools rule engine uses automatic memory management to maintain events that are stored in KIE sessions. The Drools rule engine can retract from a KIE session any events that no longer match any rule due to their temporal constraints and release any resources held by the retracted events.
The Drools rule engine uses either explicit or inferred expiration to retract outdated events:
-
Explicit expiration: The Drools rule engine removes events that are explicitly set to expire in rules that declare the
@expirestag:DRL rule snippet with explicit expirationdeclare StockPoint @expires( 30m ) endThis example rule sets any
StockPointevents to expire after 30 minutes and to be removed from the KIE session if no other rules use the events. -
Inferred expiration: The Drools rule engine can calculate the expiration offset for a given event implicitly by analyzing the temporal constraints in the rules:
DRL rule with temporal constraintsrule "Correlate orders" when $bo : BuyOrder($id : id) $ae : AckOrder(id == $id, this after[0,10s] $bo) then // Perform an action. endFor this example rule, the Drools rule engine automatically calculates that whenever a
BuyOrderevent occurs, the Drools rule engine needs to store the event for up to 10 seconds and wait for the matchingAckOrderevent. After 10 seconds, the Drools rule engine infers the expiration and removes the event from the KIE session. AnAckOrderevent can only match an existingBuyOrderevent, so the Drools rule engine infers the expiration if no match occurs and removes the event immediately.The Drools rule engine analyzes the entire KIE base to find the offset for every event type and to ensure that no other rules use the events that are pending removal. Whenever an implicit expiration clashes with an explicit expiration value, the Drools rule engine uses the greater time frame of the two to store the event longer.
Drools rule engine queries and live queries
You can use queries with the Drools rule engine to retrieve fact sets based on fact patterns as they are used in rules. The patterns might also use optional parameters.
To use queries with the Drools rule engine, you add the query definitions in DRL files and then obtain the matching results in your application code. While a query iterates over a result collection, you can use any identifier that is bound to the query to access the corresponding fact or fact field by calling the get() method with the binding variable name as the argument. If the binding refers to a fact object, you can retrieve the fact handle by calling getFactHandle() with the variable name as the parameter.
query "people under the age of 21"
$person : Person( age < 21 )
endQueryResults results = ksession.getQueryResults( "people under the age of 21" );
System.out.println( "we have " + results.size() + " people under the age of 21" );
System.out.println( "These people are under the age of 21:" );
for ( QueryResultsRow row : results ) {
Person person = ( Person ) row.get( "person" );
System.out.println( person.getName() + "\n" );
}Invoking queries and processing the results by iterating over the returned set can be difficult when you are monitoring changes over time. To alleviate this difficulty with ongoing queries, Drools provides live queries, which use an attached listener for change events instead of returning an iterable result set. Live queries remain open by creating a view and publishing change events for the contents of this view.
To activate a live query, start your query with parameters and monitor changes in the resulting view. You can use the dispose() method to terminate the query and discontinue this reactive scenario.
query colors(String $color1, String $color2)
TShirt(mainColor = $color1, secondColor = $color2, $price: manufactureCost)
endfinal List updated = new ArrayList();
final List removed = new ArrayList();
final List added = new ArrayList();
ViewChangedEventListener listener = new ViewChangedEventListener() {
public void rowUpdated(Row row) {
updated.add( row.get( "$price" ) );
}
public void rowRemoved(Row row) {
removed.add( row.get( "$price" ) );
}
public void rowAdded(Row row) {
added.add( row.get( "$price" ) );
}
};
// Open the live query:
LiveQuery query = ksession.openLiveQuery( "colors",
new Object[] { "red", "blue" },
listener );
...
...
// Terminate the live query:
query.dispose()For more live query examples, see Glazed Lists examples for Drools Live Queries.
Drools rule engine event listeners and debug logging
The Drools rule engine generates events when performing activities such as fact insertions and rule executions. If you register event listeners, the Drools rule engine calls every listener when an activity is performed.
Event listeners have methods that correspond to different types of activities. The Drools rule engine passes an event object to each method; this object contains information about the specific activity.
Your code can implement custom event listeners and you can also add and remove registered event listeners. In this way, your code can be notified of Drools rule engine activity, and you can separate logging and auditing work from the core of your application.
The Drools rule engine supports the following event listeners with the following methods:
public interface AgendaEventListener
extends
EventListener {
void matchCreated(MatchCreatedEvent event);
void matchCancelled(MatchCancelledEvent event);
void beforeMatchFired(BeforeMatchFiredEvent event);
void afterMatchFired(AfterMatchFiredEvent event);
void agendaGroupPopped(AgendaGroupPoppedEvent event);
void agendaGroupPushed(AgendaGroupPushedEvent event);
void beforeRuleFlowGroupActivated(RuleFlowGroupActivatedEvent event);
void afterRuleFlowGroupActivated(RuleFlowGroupActivatedEvent event);
void beforeRuleFlowGroupDeactivated(RuleFlowGroupDeactivatedEvent event);
void afterRuleFlowGroupDeactivated(RuleFlowGroupDeactivatedEvent event);
}public interface RuleRuntimeEventListener extends EventListener {
void objectInserted(ObjectInsertedEvent event);
void objectUpdated(ObjectUpdatedEvent event);
void objectDeleted(ObjectDeletedEvent event);
}For the definitions of event classes, see the GitHub repository.
Drools includes default implementations of these listeners: DefaultAgendaEventListener and DefaultRuleRuntimeEventListener. You can extend each of these implementations to monitor specific events.
For example, the following code extends DefaultAgendaEventListener to monitor the AfterMatchFiredEvent event and attaches this listener to a KIE session. The code prints pattern matches when rules are executed (fired):
AfterMatchFiredEvent events in the agendaksession.addEventListener( new DefaultAgendaEventListener() {
public void afterMatchFired(AfterMatchFiredEvent event) {
super.afterMatchFired( event );
System.out.println( event );
}
});Drools also includes the following Drools rule engine agenda and rule runtime event listeners for debug logging:
-
DebugAgendaEventListener -
DebugRuleRuntimeEventListener
These event listeners implement the same supported event-listener methods and include a debug print statement by default. You can add additional monitoring code for a specific supported event.
For example, the following code uses the DebugRuleRuntimeEventListener event listener to monitor and print all working memory (rule runtime) events:
ksession.addEventListener( new DebugRuleRuntimeEventListener() );Practices for development of event listeners
The Drools rule engine calls event listeners during rule processing. The calls block the execution of the Drools rule engine. Therefore, the event listener can affect the performance of the Drools rule engine.
To ensure minimal disruption, follow the following guidelines:
-
Any action must be as short as possible.
-
A listener class must not have a state. The Drools rule engine can destroy and re-create a listener class at any time.
-
Do not use logic that relies on the order of execution of different event listeners.
-
Do not include interactions with different entities outside the Drools rule engine within a listener. For example, do not include REST calls for notification of events. An exception is the output of logging information; however, a logging listener must be as simple as possible.
-
You can use a listener to modify the state of the Drools rule engine, for example, to change the values of variables.
Configuring a logging utility in the Drools rule engine
The Drools rule engine uses the Java logging API SLF4J for system logging. You can use one of the following logging utilities with the Drools rule engine to investigate Drools rule engine activity, such as for troubleshooting or data gathering:
-
Logback
-
Apache Commons Logging
-
Apache Log4j
-
java.util.loggingpackage
For the logging utility that you want to use, add the relevant dependency to your Maven project or save the relevant XML configuration file in the org.drools package of your Drools distribution:
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
</dependency><configuration>
<logger name="org.drools" level="debug"/>
...
<configuration><log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/">
<category name="org.drools">
<priority value="debug" />
</category>
...
</log4j:configuration>
If you are developing for an ultra light environment, use the slf4j-nop or slf4j-simple logger.
|
Performance tuning considerations with the Drools rule engine
The following key concepts or suggested practices can help you optimize Drools rule engine performance. These concepts are summarized in this section as a convenience and are explained in more detail in the cross-referenced documentation, where applicable. This section will expand or change as needed with new releases of Drools.
- Use sequential mode for stateless KIE sessions that do not require important Drools rule engine updates
-
Sequential mode is an advanced rule base configuration in the Drools rule engine that enables the Drools rule engine to evaluate rules one time in the order that they are listed in the Drools rule engine agenda without regard to changes in the working memory. As a result, rule execution may be faster in sequential mode, but important updates may not be applied to your rules. Sequential mode applies to stateless KIE sessions only.
To enable sequential mode, set the system property
drools.sequentialtotrue.For more information about sequential mode or other options for enabling it, see Sequential mode in Phreak.
- Use simple operations with event listeners
-
Limit the number of event listeners and the type of operations they perform. Use event listeners for simple operations, such as debug logging and setting properties. Complicated operations, such as network calls, in listeners can impede rule execution. After you finish working with a KIE session, remove the attached event listeners so that the session can be cleaned, as shown in the following example:
Example event listener removed after useListener listener = ...; StatelessKnowledgeSession ksession = createSession(); try { ksession.insert(fact); ksession.fireAllRules(); ... } finally { if (session != null) { ksession.detachListener(listener); ksession.dispose(); } }For information about built-in event listeners and debug logging in the Drools rule engine, see Drools rule engine event listeners and debug logging.
- Configure
LambdaIntrospectorcache size for an executable model build -
You can configure the size of
LambdaIntrospector.methodFingerprintsMapcache, which is used in an executable model build. The default size of the cache is32. When you configure smaller value for the cache size, it reduces memory usage. For example, you can configure system propertydrools.lambda.introspector.cache.sizeto0for minimum memory usage. Note that smaller cache size also slows down the build performance. - Use lambda externalization for executable model
-
Enable lambda externalization to optimize the memory consumption during runtime. It rewrites lambdas that are generated and used in the executable model. This enables you to reuse the same lambda multiple times with all the patterns and the same constraint. When the rete or phreak is instantiated, the executable model becomes garbage collectible.
To enable lambda externalization for the executable model, include the following property:
-Ddrools.externaliseCanonicalModelLambda=true - Configure alpha node range index threshold
-
Alpha node range index is used to evaluate the rule constraint. You can configure the threshold of the alpha node range index using the
drools.alphaNodeRangeIndexThresholdsystem property. The default value of the threshold is9, indicating that the alpha node range index is enabled when a precedent node contains more than nine alpha nodes with inequality constraints. For example, when you have nine rules similar toPerson(age > 10),Person(age > 20), …,Person(age > 90), then you can have similar nine alpha nodes.The default value of the threshold is based on the related advantages and overhead. However, if you configure a smaller value for the threshold, then the performance can be improved depending on your rules. For example, you can configure the
drools.alphaNodeRangeIndexThresholdvalue to6, enabling the alpha node range index when you have more than six alpha nodes for a precedent node. You can set a suitable value for the threshold based on the performance test results of your rules. - Enable join node range index
-
The join node range index feature improves the performance only when there is a large number of facts to be joined, for example, 256*16 combinations. When your application inserts a large number of facts, you can enable the join node range index and evaluate the performance improvement. By default, the join node range index is disabled.
Examplekmodule.xmlfile<kbase name="KBase1" betaRangeIndex="enabled">System property forBetaRangeIndexOptiondrools.betaNodeRangeIndexEnabled=true